As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Padrões de paralelização e coleta de dispersão
Muitas tarefas avançadas de raciocínio e geração — como resumir documentos grandes, avaliar vários caminhos de solução ou comparar perspectivas diversas — se beneficiam da execução paralela de prompts. Os fluxos de trabalho sequenciais tradicionais são insuficientes quando são necessárias escalabilidade, capacidade de resposta e tolerância a falhas. Para superar isso, a paralelização baseada em LLM pode ser reimaginada usando um padrão de dispersão e coleta orientado por eventos, em que as tarefas são distribuídas dinamicamente para agentes autônomos e os resultados sintetizados de forma inteligente.
O diagrama a seguir é um exemplo de um fluxo de trabalho de paralelização do LLM:
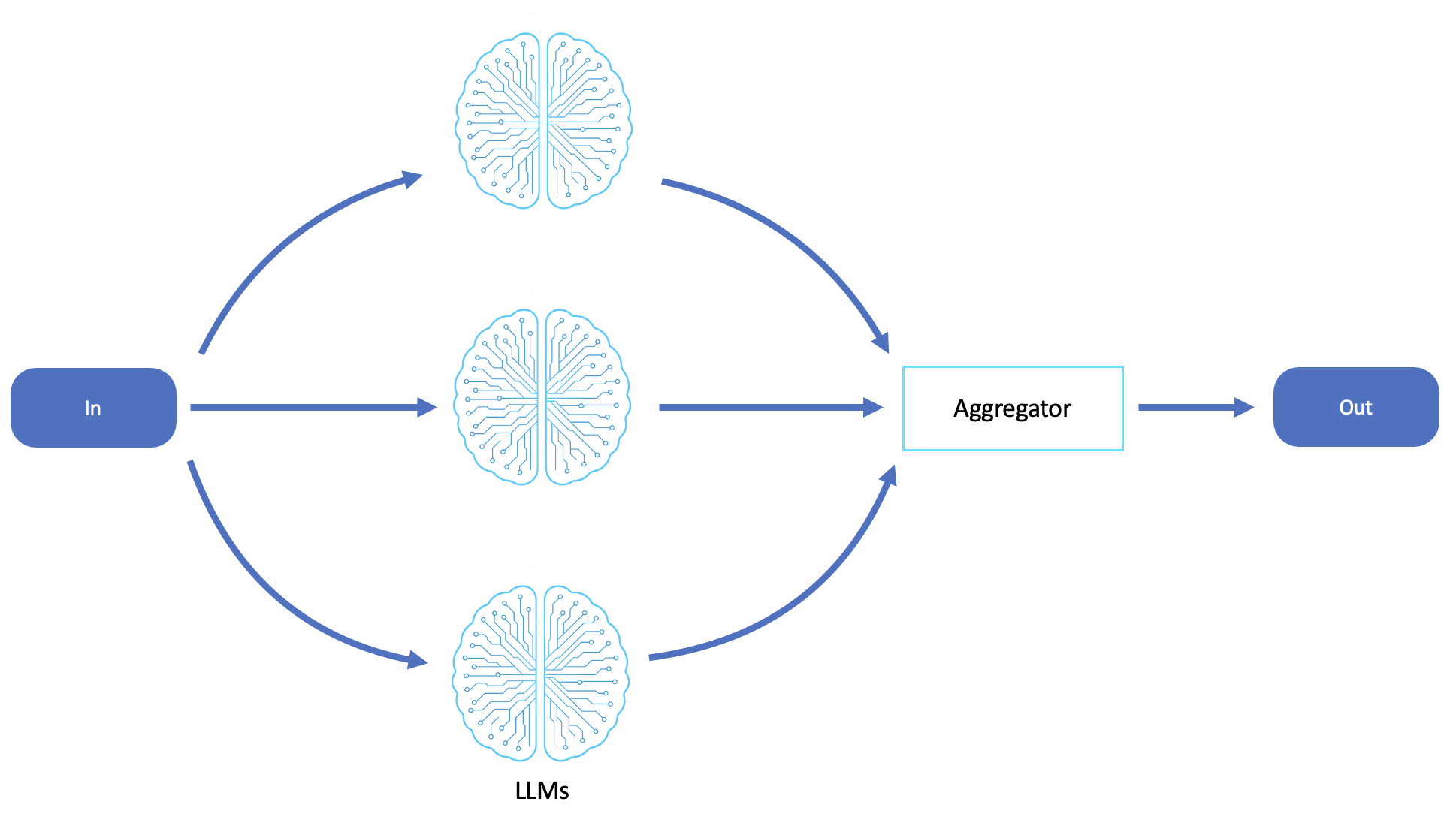
Scatter-gather
Em sistemas distribuídos, um padrão de dispersão envia tarefas para vários serviços ou unidades de processamento em paralelo, aguarda suas respostas e, em seguida, agrega os resultados em uma saída consolidada. Ao contrário do fan-out, o scatter-gather é coordenado porque espera respostas e geralmente aplica a lógica para combinar, comparar e selecionar resultados.
As implementações comuns para paralelização e coleta de dispersão incluem o seguinte:
-
AWS Step Functions mapear um estado para execução paralela de tarefas
-
AWS Lambda com simultaneidade, coordenando resultados de várias funções invocadas
-
Amazon EventBridge com fluxos de trabalho de correlação IDs e agregação
-
Padrão de controlador personalizado para gerenciar o fan-out e coletar resultados usando o Amazon Simple Storage Service (Amazon S3), o Amazon DynamoDB ou filas
O diagrama a seguir é um exemplo de coleta dispersa:
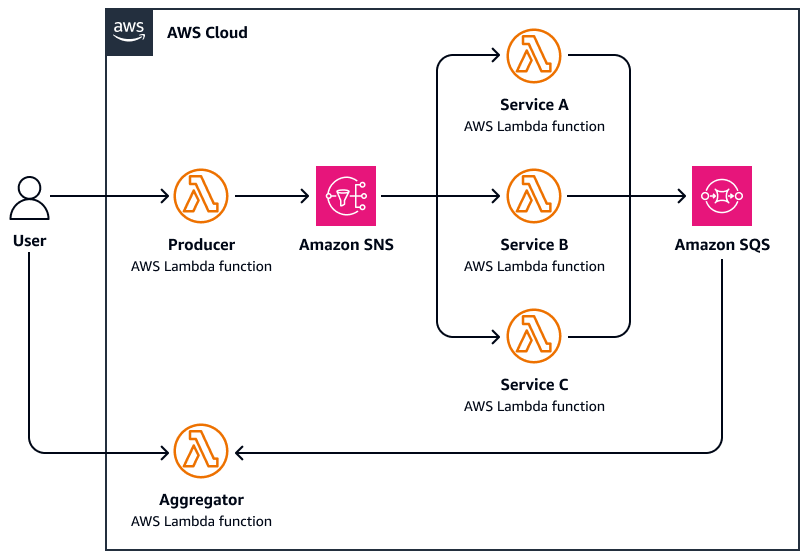
-
Um usuário envia uma solicitação para uma função de coordenador central que dispersa a tarefa publicando mensagens paralelas em um tópico do Amazon Simple Notification Service (Amazon SNS).
-
Cada mensagem inclui metadados da tarefa e é encaminhada para um funcionário especializado. AWS Lambda
-
Cada funcionário processa de AWS Lambda forma independente sua subtarefa atribuída (por exemplo, consultar uma API externa, processar um documento e analisar dados).
-
Os resultados são gravados em uma camada de armazenamento comum, como o Amazon Simple Queue Service (Amazon SQS).
-
A função agregadora espera que todas as respostas sejam concluídas e, em seguida, faz o seguinte:
-
Reúne e agrega os resultados (por exemplo, mescla resumos, seleciona as melhores correspondências)
-
Envia uma resposta final ou aciona um fluxo de trabalho posterior
-
Os casos de uso comuns para padrões de coleta de dispersão incluem o seguinte:
-
Pesquisa federada
-
Mecanismos de comparação de preços
-
Análise de dados agregados
-
Inferência multimodelo
Paralelização baseada em LLM (cognição de dispersão e coleta)
Em sistemas agentes, a paralelização reflete de perto a coleta dispersa, distribuindo subtarefas em várias chamadas ou agentes do LLM, cada um raciocinando de forma independente sobre uma parte do problema. Os resultados retornados são coletados e sintetizados por um processo de agregação, que geralmente é outro agente LLM ou controlador.
Paralelização de agentes
-
Um agente envia uma solicitação “Resuma os insights nesses 10 relatórios”.
-
Ele dispersa os relatórios em 10 tarefas paralelas de resumo do LLM.
-
Ao retornar todos os resumos, o agente faz o seguinte:
-
Agrega resumos em um briefing unificado
-
Identifica temas ou contradições
-
Envia a saída sintetizada para o usuário
-
Esse fluxo de trabalho agente permite um raciocínio paralelo escalável, modular e adaptável. Isso é ideal para casos de uso que exigem alto rendimento cognitivo.
O diagrama a seguir é um exemplo de paralelização de agentes:
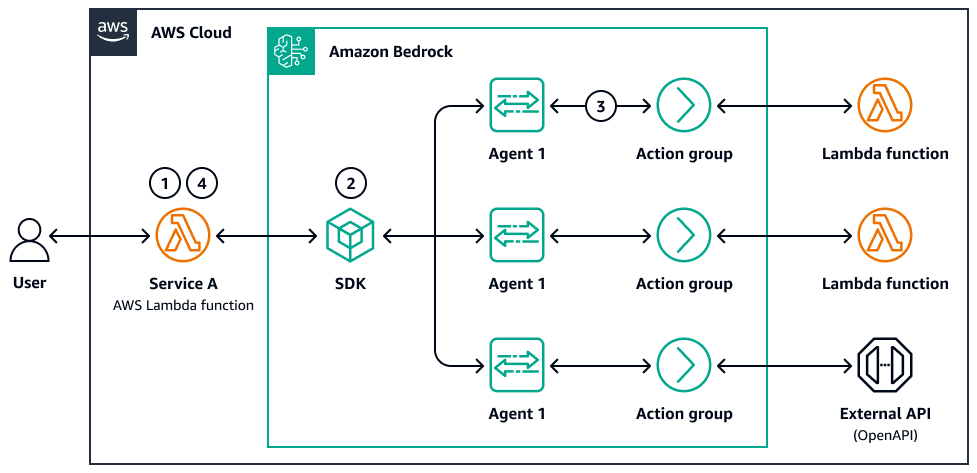
-
Um usuário envia uma consulta com várias partes ou um conjunto de documentos.
-
Um controlador AWS Lambda ou função de etapa distribui as subtarefas. Cada tarefa invoca uma chamada ou subagente do Amazon Bedrock LLM com seu próprio prompt.
-
Quando as chamadas e subtarefas são concluídas, os resultados são armazenados (por exemplo, no Amazon S3 ou no armazenamento de memória) e uma etapa de agregação mescla, compara ou filtra as saídas.
-
O sistema retorna a resposta final ao usuário ou ao agente downstream.
Esse sistema tem um ciclo de raciocínio distribuído com rastreabilidade, tolerância a falhas e ponderação opcional de resultados ou lógica de seleção.
Takeaways
A paralelização agente usa padrões de coleta de dispersão para distribuir tarefas de LLM, permitindo processamento paralelo e síntese inteligente de resultados.
