As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Agentes básicos de raciocínio
Um agente de raciocínio básico é a forma mais simples de IA agente que realiza inferência lógica ou tomada de decisão em resposta a uma consulta. Ele aceita a entrada de um usuário ou sistema e processa consultas e gera respostas usando prompts estruturados.
Esse padrão é útil para tarefas que exigem raciocínio, classificação ou resumo em uma única etapa com base em um determinado contexto. Ele não usa memória, ferramentas ou gerenciamento de estado, o que o torna sem estado, leve e altamente combinável em grandes fluxos de trabalho.
Arquitetura
O fluxo de um agente de raciocínio básico é mostrado no diagrama a seguir:
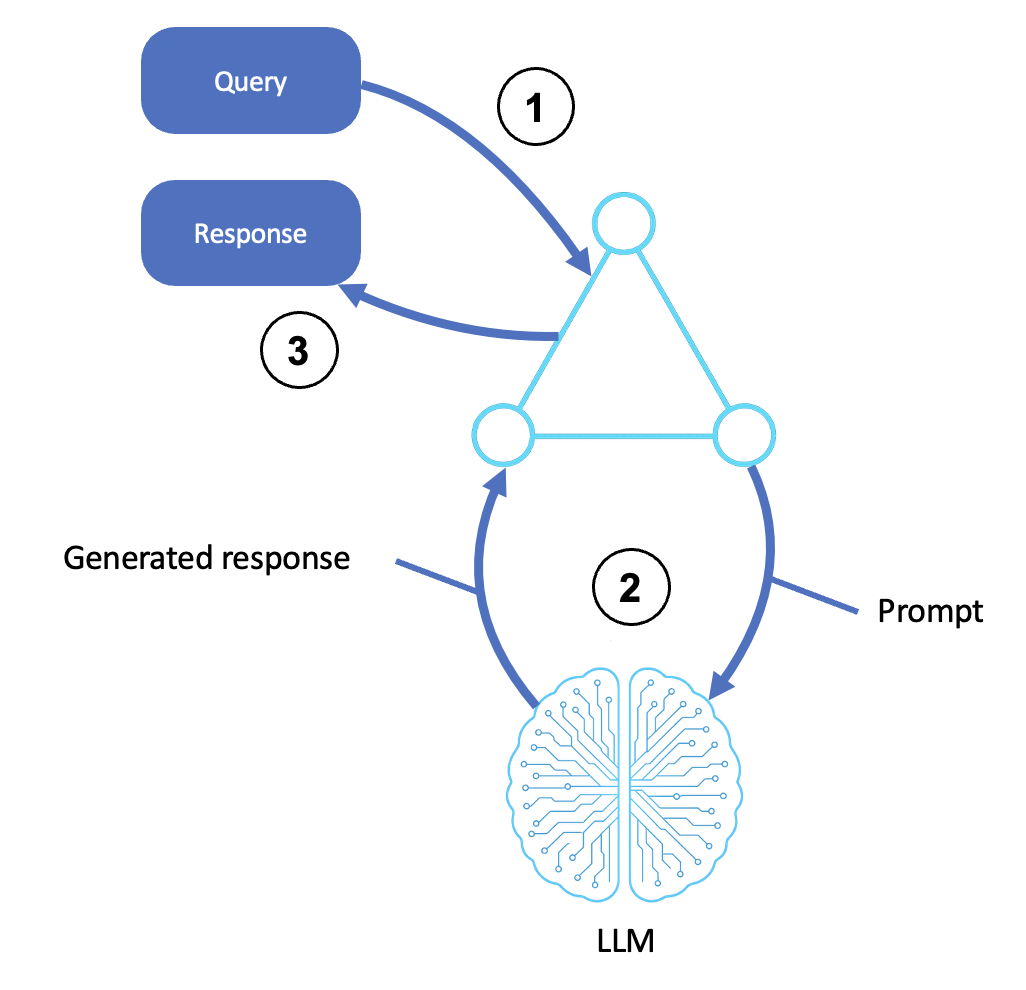
Description
-
Recebe uma entrada
-
Um usuário, sistema ou agente upstream envia uma consulta ou instrução.
-
A entrada é transferida para o shell do agente ou para a camada de orquestração.
-
Essa etapa inclui qualquer pré-processamento, modelagem imediata e identificação de metas.
-
-
Invoca o LLM
-
O agente transforma a consulta em um prompt estruturado e a envia para um LLM (por exemplo, por meio do Amazon Bedrock).
-
O LLM gera uma resposta com base no prompt usando conhecimento e contexto pré-treinados.
-
A saída gerada pode incluir etapas de raciocínio (cadeia de pensamento), respostas finais ou opções classificadas.
-
-
Retorna uma resposta
-
A saída gerada é retransmitida para a interface do agente.
-
Isso pode incluir formatação, pós-processamento ou uma resposta de API.
-
Capacidades
-
Suporta linguagem natural ou entrada estruturada
-
Usa engenharia rápida para orientar o comportamento
-
Sem estado e escalável
-
Pode ser incorporado à interface do usuário, CLI, APIs e pipelines
Limitações
-
Sem memória ou consciência histórica
-
Sem interação com ferramentas externas ou fontes de dados
-
Limitado ao que o LLM sabe no momento da inferência
Casos de uso comuns
-
Perguntas e respostas conversacionais
-
Explicações e resumos de políticas
-
Orientação para a tomada de decisões
-
Fluxos de chatbot leves e automatizados
-
Classificação, rotulagem e pontuação
Orientação para implementação
Você pode usar as seguintes ferramentas e serviços para criar um agente de raciocínio básico:
-
Amazon Bedrock para invocação de LLM (Anthropic, AI21, Meta)
-
Amazon API Gateway ou AWS Lambda para expô-lo como um microsserviço sem estado
-
Modelos de prompt armazenados no Parameter Store ou como código AWS Secrets Manager
Resumo
O agente de raciocínio básico é fundamental por causa de sua estrutura simples. Ele tem recursos essenciais que transformam metas em caminhos de raciocínio que levam a resultados inteligentes. Esse padrão geralmente é um ponto de partida para padrões avançados, como agentes baseados em ferramentas e agentes que usam geração aumentada de recuperação (RAG). Também é um componente confiável e modular de grandes fluxos de trabalho.
Agente RAG
Retrieval-augmented a geração (RAG) é uma técnica que combina recuperação de informações com geração de texto para criar respostas precisas e contextuais. O RAG permite que os agentes recuperem informações externas relevantes antes de contratar o LLM. Ele amplia a memória efetiva e a precisão do raciocínio de um agente ao basear suas decisões em informações atualizadas, factuais ou específicas do domínio. Em contraste com os LLMs sem estado que dependem exclusivamente de pesos pré-treinados, o RAG tem uma camada externa de pesquisa de conhecimento que aprimora dinamicamente as solicitações com o contexto.
Arquitetura
A lógica do padrão RAG é ilustrada no diagrama a seguir:
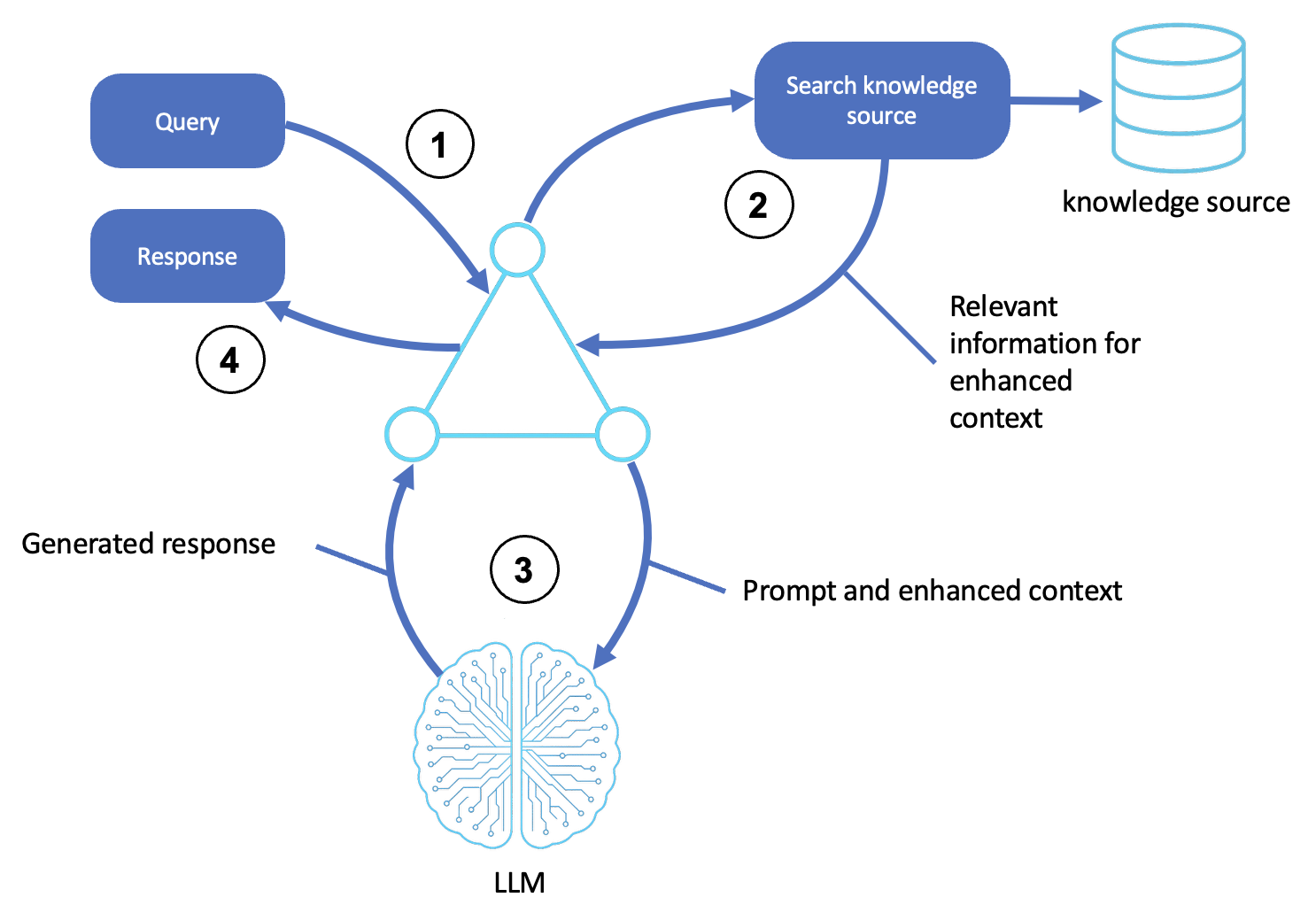
Description
-
Recebe uma consulta
-
Um usuário ou sistema upstream envia uma consulta ou meta ao agente.
-
O shell do agente aceita a solicitação e a formata como uma solicitação de raciocínio.
-
-
Pesquisa uma fonte externa
-
O agente identifica os conceitos e a intenção da consulta.
-
Ele consulta uma fonte de conhecimento, como um repositório vetorial, banco de dados ou índice de documentos usando pesquisa semântica ou correspondência de palavras-chave.
-
As passagens, documentos ou entidades mais relevantes são recuperados para uso na próxima etapa.
-
-
Gera uma resposta contextual
-
O agente aumenta o prompt com as informações recuperadas, formando uma entrada contextualizada para o LLM.
-
O LLM processa qualquer entrada usando raciocínio generativo (por exemplo, cadeia de pensamento ou reflexão) para produzir uma resposta precisa.
-
-
Retorna a saída final
-
O agente prepara a saída envolvendo-a em qualquer cabeçalho de comunicação ou na formatação necessária e, em seguida, a retorna ao usuário ou ao sistema de chamada.
-
(Opcional) Os documentos recuperados e a saída do LLM podem ser registrados, pontuados e armazenados na memória para futuras consultas.
-
Capacidades
-
Fact-grounded produção mesmo em domínios de longa duração ou específicos da empresa
-
Extensão de memória sem ajustar o modelo
-
Contexto dinâmico baseado em cada consulta e estado do usuário
-
Totalmente compatível com bancos de dados vetoriais, índices semânticos e filtragem de metadados
Casos de uso comuns
-
Assistentes de conhecimento corporativo
-
Bots de conformidade regulatória
-
Co-pilotos de suporte ao cliente
-
Search-enhanced chatbots
-
Agentes de documentação para desenvolvedores
Orientação para implementação
Use as seguintes ferramentas e serviços para criar um agente que usa o RAG:
-
Amazon Bedrock para invocação de LLM
-
Amazon Kendra OpenSearch ou Amazon Aurora para documentação ou pesquisa estruturada de dados
-
Amazon Simple Storage Service (Amazon S3) (Amazon S3) para armazenamento de documentos
-
AWS Lambda para orquestrar a pesquisa, o prompt e a inferência do LLM
-
Knowledge-based integrações com agentes (usando plug-ins de memória, recuperadores semânticos ou Amazon Bedrock)
Resumo
O agente RAG conecta o raciocínio do modelo estático à inteligência dinâmica do mundo real. Ele capacita os agentes com a capacidade de pesquisar o que não sabem, sintetizar respostas a partir do conhecimento recuperado e produzir respostas auditáveis e de alta confiança.
Os padrões RAG são a base para a criação de agentes inteligentes que escalam o acesso ao conhecimento sem reciclagem. Geralmente, é um precursor de padrões de orquestração mais complexos que envolvem o uso de ferramentas, planejamento e memória de longo prazo.
