As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Enriquecimento semântico automático para Serverless
Visão geral do
O recurso de enriquecimento semântico automático pode ajudar a melhorar a relevância da pesquisa em até 20% em relação à pesquisa léxica. O enriquecimento semântico automático elimina o trabalho pesado indiferenciado de gerenciar sua própria infraestrutura de modelo de ML (aprendizado de máquina) e a integração com o mecanismo de pesquisa. O recurso está disponível para todos os três tipos de coleção sem servidor: Pesquisa, Série Temporal e Vetor.
Conceitos de pesquisa semântica
Os mecanismos de pesquisa tradicionais dependem da correspondência palavra a palavra (conhecida como pesquisa léxica) para encontrar resultados para consultas. Embora isso funcione bem para consultas específicas, como números de modelos de televisão, ele pode não retornar resultados relevantes para pesquisas mais abstratas. Por exemplo, ao pesquisar por “sapatos para a praia”, uma pesquisa léxica apenas corresponde às palavras individuais “sapatos”, “praia”, “para” e “o” nos itens do catálogo, potencialmente sem produtos relevantes, como “sandálias resistentes à água” ou “calçados de surfe”, que não contêm os termos de pesquisa exatos.
A pesquisa semântica retorna resultados de consulta que incorporam não apenas a correspondência às palavras-chave, mas a intenção e o significado contextual da pesquisa do usuário. Por exemplo, se um usuário pesquisar “como tratar uma dor de cabeça”, um sistema de busca semântica pode retornar os seguintes resultados:
-
Remédios para enxaqueca
-
Técnicas de controle da dor
-
Over-the-counter analgésicos
Detalhes do modelo e benchmark de desempenho
Embora esse recurso lide com as complexidades técnicas nos bastidores sem expor o modelo subjacente, a descrição do modelo e os resultados de benchmark a seguir ajudam você a tomar decisões informadas sobre a adoção de recursos em suas cargas de trabalho críticas.
O enriquecimento semântico automático usa um modelo esparso pré-treinado e gerenciado por serviços que funciona de forma eficaz sem exigir ajustes personalizados. O modelo analisa os campos que você especifica, expandindo-os em vetores esparsos com base em associações aprendidas de diversos dados de treinamento. Os termos expandidos e seus pesos de significância são armazenados no formato nativo do índice Lucene para uma recuperação eficiente. Otimizamos esse processo usando o modo somente documentos
A validação do desempenho durante o desenvolvimento do recurso usou o conjunto de dados de recuperação de passagens MS MARCO
-
Idioma inglês - Melhoria de relevância de 20% em relação à pesquisa léxica. Também reduziu a latência da pesquisa P90 em 7,7% em relação à pesquisa lexical (BM25 é 26 ms e o enriquecimento semântico automático é 24 ms).
-
Multi-lingual - Melhoria da relevância de 105% em relação à pesquisa lexical, enquanto a latência da pesquisa P90 aumentou 38,4% em relação à pesquisa lexical (BM25 é 26 ms e o enriquecimento semântico automático é 36 ms).
Dada a natureza exclusiva de cada carga de trabalho, você pode avaliar esse recurso em seu ambiente de desenvolvimento usando seus próprios critérios de benchmarking antes de tomar decisões de implementação.
Idiomas suportados
O recurso oferece suporte ao inglês. Além disso, o modelo também oferece suporte para árabe, bengali, chinês, finlandês, francês, hindi, indonésio, japonês, coreano, persa, russo, espanhol, suaíli e telugu.
Configure um índice automático de enriquecimento semântico para coleções sem servidor
Você pode configurar um índice com o enriquecimento semântico automático ativado para seus campos de texto por meio do console, das APIs e dos CloudFormation modelos durante a criação do novo índice. Para habilitá-lo para um índice existente, você deve recriar o índice com o enriquecimento semântico automático ativado para campos de texto.
Com o AWS console, você pode criar um índice com campos de enriquecimento semântico automático. Depois de selecionar uma coleção, você pode encontrar o botão Criar índice na parte superior do console. Depois de escolher Criar índice, o console fornece opções para definir campos de enriquecimento semântico automático. Em um índice, você pode ter combinações de enriquecimento semântico automático para inglês e multilíngue, bem como campos lexicais.
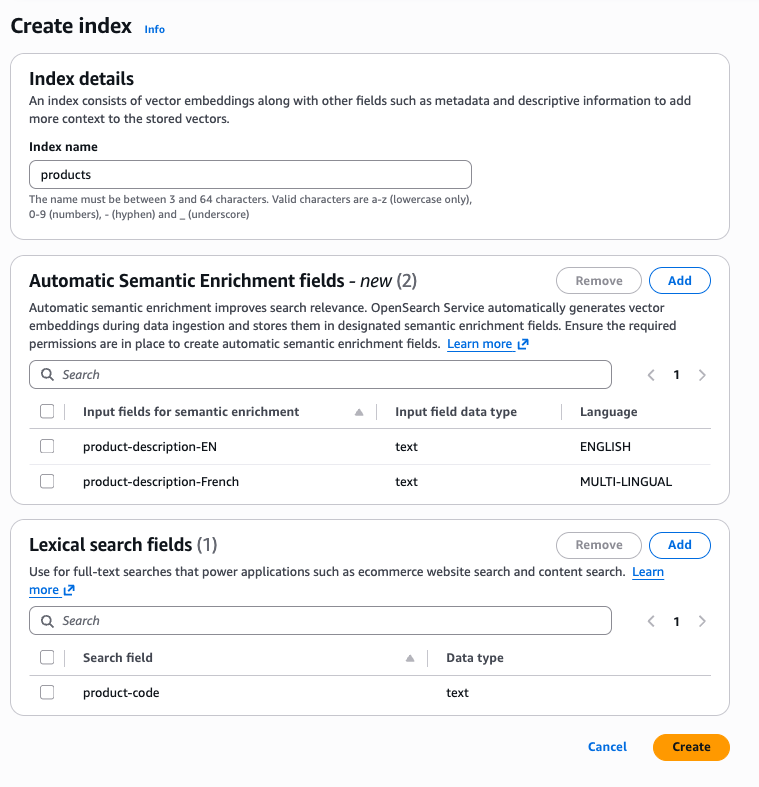
Para criar um índice automático de enriquecimento semântico usando a interface de linha de AWS comando (AWS CLI), use o comando create-index:
aws opensearchserverless create-index \ --id [collection_id] \ --index-name [index_name] \ --index-schema [index_body] \
No exemplo de esquema de índice a seguir, o title_semantic campo tem um tipo de campo definido como text e um parâmetro semantic_enrichment definido como status. ENABLED A configuração do semantic_enrichment parâmetro permite o enriquecimento semântico automático no title_semantic campo. Você pode usar o language_options campo para especificar english oumulti-lingual.
aws opensearchserverless create-index \ --id XXXXXXXXX \ --index-name 'product-catalog' \ --index-schema '{ "mappings": { "properties": { "product_id": { "type": "keyword" }, "title_semantic": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } }, "title_non_semantic": { "type": "text" } } } }'
Para descrever o índice criado, use o seguinte comando:
aws opensearchserverless get-index \ --id [collection_id] \ --index-name [index_name] \
Você também pode usar CloudFormation modelos (Type:AWS:::OpenSearchServerless:CollectionIndex) para criar uma pesquisa semântica durante o provisionamento da coleção, bem como após a criação da coleção.
Atualizar um índice existente
Você pode atualizar um índice existente para adicionar novos campos de enriquecimento semântico, ativar ou desativar o enriquecimento semântico em campos existentes ou adicionar campos de texto não semânticos. Use o update-index comando e forneça somente os campos que você deseja alterar noindex-schema. Os campos não incluídos na solicitação permanecem inalterados.
nota
O índice settings não pode ser atualizado. Se você incluir um settings bloco na solicitação, a operação retornará um erro de validação. Para alterar as configurações do índice, você deve excluir e recriar o índice.
Para atualizar um índice usando o AWS CLI, use o update-index comando:
aws opensearchserverless update-index \ --id [collection_id] \ --index-name [index_name] \ --index-schema [index_body]
Adicionar um novo campo de enriquecimento semântico
Você pode adicionar um novo text campo com o enriquecimento semântico ativado a um índice existente. O serviço configura automaticamente o modelo de ML, o pipeline de ingestão e o pipeline de pesquisa necessários. Novos documentos indexados após a atualização são enriquecidos automaticamente.
Importante
Os documentos existentes não são preenchidos. Para preencher o campo de enriquecimento semântico em documentos existentes, você deve inseri-los novamente após a atualização. Até serem reingeridos, os documentos existentes não se beneficiarão da pesquisa semântica no novo campo.
aws opensearchserverless update-index \ --id my-collection-id \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "description": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } } } } }'
Desativar o enriquecimento semântico em um campo
Para desativar o enriquecimento semântico em um campo que atualmente o tem ativado, status defina como. DISABLED O campo é removido dos canais de ingestão e pesquisa. O campo de texto subjacente e seu campo de incorporação permanecem no índice, mas não são mais enriquecidos.
aws opensearchserverless update-index \ --id my-collection-id \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "title_semantic": { "type": "text", "semantic_enrichment": { "status": "DISABLED" } } } } }'
Limitações de atualização
As operações a seguir não são suportadas update-index e exigem que você exclua e recrie o índice:
-
Mudando
language_optionsem um campo que atualmente tem o enriquecimento semântico habilitado. Desative o campo primeiro e, em seguida, reative-o com a opção de novo idioma. -
Atualizando campos aninhados. O enriquecimento semântico só é suportado em campos de nível superior
text. -
Atualizando o índice
settings.
nota
Se o índice tiver um canal de ingestão ou de pesquisa personalizado que não tenha sido criado pelo enriquecimento semântico automático, a operação de atualização será bloqueada. Remova o pipeline personalizado antes de adicionar campos de enriquecimento semântico.
Ingestão e pesquisa de dados
Depois de criar um índice com o enriquecimento semântico automático ativado, o recurso funciona automaticamente durante o processo de ingestão de dados, sem necessidade de configuração adicional.
Ingestão de dados: quando você adiciona documentos ao seu índice, o sistema automaticamente:
-
Analisa os campos de texto que você designou para enriquecimento semântico
-
Gera codificações semânticas usando o modelo esparso gerenciado por OpenSearch serviços
-
Armazena essas representações enriquecidas junto com seus dados originais
Esse processo usa conectores OpenSearch de ML e pipelines de ingestão integrados, que são criados e gerenciados automaticamente nos bastidores.
Pesquisa: os dados de enriquecimento semântico já estão indexados, então as consultas são executadas com eficiência sem invocar o modelo de ML novamente. Isso significa que você obtém maior relevância de pesquisa sem sobrecarga adicional de latência de pesquisa.
Configurar permissões para enriquecimento semântico automático
Antes de criar um índice de enriquecimento semântico automatizado, você deve configurar as permissões necessárias. Esta seção explica as permissões necessárias e como configurá-las.
Permissões de política do IAM
Use a seguinte política AWS Identity and Access Management (IAM) para conceder as permissões necessárias para trabalhar com o enriquecimento semântico automático:
- Permissões de chave
-
-
As permissões
aoss:*Indexhabilitam o gerenciamento de índices -
A
aoss:APIAccessAllpermissão permite operações OpenSearch de API -
Para restringir as permissões a uma coleção específica, substitua
"Resource": "*"pelo ARN da coleção
-
Configurar permissões de acesso a dados
Para configurar um índice para enriquecimento semântico automático, você deve ter as políticas de acesso a dados apropriadas que concedam permissão para acessar recursos de índice, pipeline e coleção de modelos. Para saber mais sobre políticas de acesso a dados, consulte Controle de acesso a dados para Amazon OpenSearch Serverless. Para obter o procedimento de configuração de uma política de acesso a dados, consulte Criação de políticas de acesso a dados (console).
Permissões de acesso a dados
[ { "Description": "Create index permission", "Rules": [ { "ResourceType": "index", "Resource": ["index/collection_name/*"], "Permission": [ "aoss:CreateIndex", "aoss:DescribeIndex", "aoss:UpdateIndex", "aoss:DeleteIndex" ] } ], "Principal": [ "arn:aws:iam::account_id:role/role_name" ] }, { "Description": "Create pipeline permission", "Rules": [ { "ResourceType": "collection", "Resource": ["collection/collection_name"], "Permission": [ "aoss:CreateCollectionItems", "aoss:DescribeCollectionItems" ] } ], "Principal": [ "arn:aws:iam::account_id:role/role_name" ] }, { "Description": "Create model permission", "Rules": [ { "ResourceType": "model", "Resource": ["model/collection_name/*"], "Permission": ["aoss:CreateMLResource"] } ], "Principal": [ "arn:aws:iam::account_id:role/role_name" ] }, ]
Permissões de acesso à rede
Para permitir que as APIs do serviço acessem coleções privadas, você deve configurar políticas de rede que permitam o acesso necessário entre a API do serviço e a coleção. Para obter mais informações sobre políticas de rede, consulte Acesso à rede para Amazon OpenSearch Serverless.
[ { "Description":"Enable automatic semantic enrichment in a private collection", "Rules":[ { "ResourceType":"collection", "Resource":[ "collection/collection_name" ] } ], "AllowFromPublic":false, "SourceServices":[ "aoss.amazonaws.com" ], } ]
Para configurar as permissões de acesso à rede para uma coleção privada
-
Faça login no console OpenSearch de serviço em https://console.aws.amazon.com/aos/home
. -
No painel de navegação esquerdo, escolha Políticas de rede. Depois, siga um destes procedimentos:
-
Escolha o nome de uma política existente e escolha Editar
-
Escolha Criar política de rede e configure os detalhes da política
-
-
Na área Tipo de acesso, escolha Privado (recomendado) e selecione Acesso privado ao serviço da AWS .
-
No campo de pesquisa, escolha Serviço e depois aoss.amazonaws.com.
-
Na área Tipo de recurso, marque a caixa de seleção Habilitar acesso ao OpenSearch endpoint.
-
Em Pesquisar coleções ou inserir termos de prefixo específicos, no campo de pesquisa, selecione Nome da coleção. Em seguida, insira ou selecione o nome das coleções a serem associadas à política de rede.
-
Escolha Criar para uma nova política de rede ou Atualizar para uma política de rede existente.
Regravações de consultas
O enriquecimento semântico automático converte automaticamente suas consultas de “correspondência” existentes em consultas de pesquisa semântica sem exigir modificações na consulta. Se uma consulta de correspondência fizer parte de uma consulta composta, o sistema percorrerá sua estrutura de consulta, localizará consultas de correspondência e as substituirá por consultas neurais esparsas. Atualmente, o recurso suporta apenas a substituição de consultas “correspondentes”, seja uma consulta autônoma ou parte de uma consulta composta. “multi_match” não é suportado. Além disso, o recurso oferece suporte a todas as consultas compostas para substituir suas consultas de correspondência aninhadas. As consultas compostas incluem: bool, boosting, constant_score, dis_max, function_score e hybrid.
Limitações do enriquecimento semântico automático
A pesquisa semântica automática é mais eficaz quando aplicada a campos de pequeno a médio porte que contêm conteúdo em linguagem natural, como títulos de filmes, descrições de produtos, resenhas e resumos. Embora a pesquisa semântica aumente a relevância para a maioria dos casos de uso, ela pode não ser ideal para determinados cenários. Considere as seguintes limitações ao decidir se deve implementar o enriquecimento semântico automático para seu caso de uso específico.
-
Documentos muito longos — O modelo esparso atual processa apenas os primeiros 8.192 tokens de cada documento em inglês. Para documentos multilíngues, são 512 tokens. Para artigos longos, considere implementar a fragmentação de documentos para garantir o processamento completo do conteúdo.
-
Cargas de trabalho de análise de registros — O enriquecimento semântico aumenta significativamente o tamanho do índice, o que pode ser desnecessário para a análise de registros, onde a correspondência exata normalmente é suficiente. O contexto semântico adicional raramente melhora a eficácia da pesquisa de registros o suficiente para justificar o aumento dos requisitos de armazenamento.
-
O enriquecimento semântico automático não é compatível com o recurso Fonte Derivada.
Preços
O Amazon OpenSearch Service fatura o enriquecimento semântico automático com base nas unidades de OpenSearch computação (OCUs) consumidas durante a geração de vetores esparsos no momento da indexação. Você é cobrado somente pelo uso real durante a indexação dos campos de texto em que você ativou o enriquecimento semântico automático. Uma OCU de pesquisa semântica pode processar 11,1 milhões de tokens para conteúdo em inglês. Para processar 2,4 bilhões de tokens, você precisaria de cerca de 216 buscas semânticas OCU-hours (2,4 bilhões/11,10 milhões). Com um preço de 0,24 USD por pesquisa semântica OCU-hour, o custo do processamento de 10 GB de dados para pesquisa semântica automática seria de 51 USD (216 x 0 USD). OCU-hours 24/OCU-hora). Não há cobranças adicionais de OCU de pesquisa semântica durante as operações de pesquisa ou para armazenamento de dados.
Você pode monitorar esse consumo usando a CloudWatch métrica da AmazonSemanticSearchOCU. Para obter detalhes específicos sobre limites de token de modelo, taxa de transferência de volume por OCU e um exemplo de cálculo de amostra, acesse Preços de OpenSearch serviços
