As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
# Tutorial: Ingestão de dados em uma coleção usando o Amazon OpenSearch Ingestion
Este tutorial mostra como usar o Amazon OpenSearch Ingestion para configurar um pipeline simples e ingerir dados em uma coleção Amazon OpenSearch Serverless. Um *pipeline* é um recurso que o OpenSearch Ingestion provisiona e gerencia. Você pode usar um pipeline para filtrar, enriquecer, transformar, normalizar e agregar dados para análises e visualizações posteriores no Service. OpenSearch
*Para ver um tutorial que demonstra como ingerir dados em um domínio de OpenSearch serviço provisionado, consulte.* [Tutorial: Ingestão de dados em um domínio usando o Amazon OpenSearch Ingestion](osis-get-started.md)
Você concluirá as seguintes etapas neste tutorial:
1. [Crie uma coleção](#osis-serverless-get-started-access).
1. [Crie um pipeline](#osis-serverless-get-started-pipeline).
1. [Ingira alguns dados de amostra](#osis-serverless-get-started-ingest).
Neste tutorial, você vai criar os recursos a seguir:
+ Um coleção chamada `ingestion-collection` no qual o pipeline fará a gravação
+ Um pipeline chamado `ingestion-pipeline-serverless`
## Permissões obrigatórias
Para fazer este tutorial, o usuário ou o perfil deve ter uma [política baseada em identidade](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/security-iam-serverless.html#security-iam-serverless-id-based-policies) anexada com as permissões mínimas a seguir. Essas permissões autorizam você criar um perfil de pipeline e anexar uma política (`iam:Create*` e `iam:Attach*`), criar ou modificar uma coleção (`aoss:*`) e trabalhar com pipelines (`osis:*`).
Além disso, várias permissões do IAM são necessárias para criar automaticamente a função do pipeline e passá-la para o OpenSearch Ingestion para que ele possa gravar dados na coleção.
------
#### [ JSON ]
****
```
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Resource":"*",
"Action":[
"osis:*",
"iam:Create*",
"iam:Attach*",
"aoss:*"
]
},
{
"Resource":[
"arn:aws:iam::{{111122223333}}:role/OpenSearchIngestion-PipelineRole"
],
"Effect":"Allow",
"Action":[
"iam:CreateRole",
"iam:AttachRolePolicy",
"iam:PassRole"
]
}
]
}
```
------
## Etapa 1: criar uma coleção
Primeiro, crie uma coleção na qual ingerir dados. Daremos o nome da coleção de `ingestion-collection`.
1. Navegue até o console do Amazon OpenSearch Service em [https://console.aws.amazon.com/aos/home](https://console.aws.amazon.com/aos/home).
1. Escolha **Coleções** no painel de navegação à esquerda e escolha **Criar coleção**.
1. No campo **Geração sem servidor**, escolha **Alternar para o clássico**.
1. Nomeie a coleção **ingestion-collection**.
1. Em **Segurança**, escolha **Criação padrão**.
1. Em **Configurações de acesso à rede**, altere o tipo de acesso para **Público** .
1. Mantenha todas as outras configurações em seus valores padrão e escolha **Próximo**.
1. Agora, configure uma política de acesso aos dados para a coleção. Desmarque a opção **Atender automaticamente às configurações da política de acesso**.
1. Para **Método de definição**, escolha **JSON ** e cole a seguinte política no editor. Essa política faz duas coisas:
+ Permite que o perfil de pipeline faça gravações na coleção.
+ Permite que você *leia* a coleção. Posteriormente, depois de ingerir alguns dados de amostra no pipeline, você consultará a coleção para garantir que os dados foram ingeridos e gravados com sucesso no índice.
```
[
{
"Rules": [
{
"Resource": [
"index/ingestion-collection/*"
],
"Permission": [
"aoss:CreateIndex",
"aoss:UpdateIndex",
"aoss:DescribeIndex",
"aoss:ReadDocument",
"aoss:WriteDocument"
],
"ResourceType": "index"
}
],
"Principal": [
"arn:aws:iam::{{your-account-id}}:role/OpenSearchIngestion-PipelineRole",
"arn:aws:iam::{{your-account-id}}:role/{{Admin}}"
],
"Description": "Rule 1"
}
]
```
1. Modifique os `Principal` elementos para incluir seu Conta da AWS ID. Como segunda entidade principal, especifique um usuário ou perfil que você possa usar para consultar a coleção mais tarde.
1. Escolha **Próximo**. Nomeie a política de acesso **pipeline-domain-access** e escolha **Avançar** novamente.
1. Reveja sua configuração da coleção e escolha **Enviar**.
## Etapa 2: criar um pipeline
Agora que você tem uma coleção, pode criar um pipeline.
**Para criar um pipeline**
1. No console do Amazon OpenSearch Service, escolha **Pipelines** no painel de navegação esquerdo.
1. Selecione **Criar pipeline**.
1. Selecione o pipeline **Em branco** e escolha **Selecionar esquema**.
1. Neste tutorial, criaremos um subpipeline simples que usa o plug-in [Origem HTTP](https://opensearch.org/docs/latest/data-prepper/pipelines/configuration/sources/http-source/). O plug-in aceita dados de log em formato de matriz JSON. Vamos especificar uma única coleção OpenSearch Serverless como coletor e ingerir todos os dados no índice. `my_logs`
No menu **Origem**, escolha **HTTP**. Em **Caminho**, insira **/logs**.
1. Para simplificar neste tutorial, configuraremos o acesso público do pipeline. Em **Opções de rede de origem**, escolha **Acesso público**. Para saber mais sobre como configurar VPC, consulte [Configurando o acesso à VPC para pipelines de ingestão da Amazon OpenSearch](pipeline-security.md).
1. Escolha **Próximo**.
1. Em **Processador**, insira **Data** e escolha **Adicionar**.
1. Habilite **A partir da hora do recebimento**. Deixe todas as outras configurações com seus valores padrão.
1. Escolha **Próximo**.
1. Configure os detalhes do coletor. Para **tipo de OpenSearch recurso**, escolha **Coleção (sem servidor)**. Em seguida, escolha a coleção de OpenSearch serviços que você criou na seção anterior.
Deixe o nome padrão a política de rede. Em **Nome do índice**, insira **my\_logs**. OpenSearch A ingestão cria automaticamente esse índice na coleção, caso ele ainda não exista.
1. Escolha **Próximo**.
1. Nomeie o pipeline de **ingestion-pipeline-serverless**. Deixe todas as configurações de capacidade com seus valores padrão.
1. Em **Perfil do pipeline**, selecione **Criar e usar um novo perfil de serviço**. O perfil do pipeline fornece as permissões necessárias para um pipeline gravar no coletor de coleções e ler de origens baseadas em pull. Ao selecionar essa opção, você permite que o OpenSearch Inestion crie a função para você, em vez de criá-la manualmente no IAM. Para obter mais informações, consulte [Configurando funções e usuários na Amazon OpenSearch Ingestion](pipeline-security-overview.md).
1. Em **Sufixo do nome da função de serviço**, insira **PipelineRole**. No IAM, o perfil terá o formato `arn:aws:iam::{{your-account-id}}:role/OpenSearchIngestion-PipelineRole`.
1. Escolha **Próximo**. Revise sua configuração do pipeline e escolha **Criar pipeline**. O pipeline leva de 5 a 10 minutos para se tornar ativo.
## Etapa 3: ingerir alguns dados de amostra
Quando o status do pipeline é `Active`, você pode começar a ingerir dados nele. Você deve assinar todas as solicitações HTTP no pipeline usando o [Signature Version 4](https://docs.aws.amazon.com/general/latest/gr/signature-version-4.html). Use uma ferramenta HTTP, como o [Postman](https://www.getpostman.com/) ou [awscurl](https://github.com/okigan/awscurl), para enviar alguns dados para o pipeline. Assim como acontece com a indexação de dados diretamente em uma coleção, a ingestão de dados em um pipeline sempre requer um [perfil do IAM, uma chave de acesso do IAM e uma chave secreta](https://docs.aws.amazon.com/powershell/latest/userguide/pstools-appendix-sign-up.html).
**nota**
A entidade principal responsável pela assinatura da solicitação deve ter a permissão `osis:Ingest` do IAM.
Primeiro, obtenha o URL de ingestão na página **Configurações do Pipeline**:
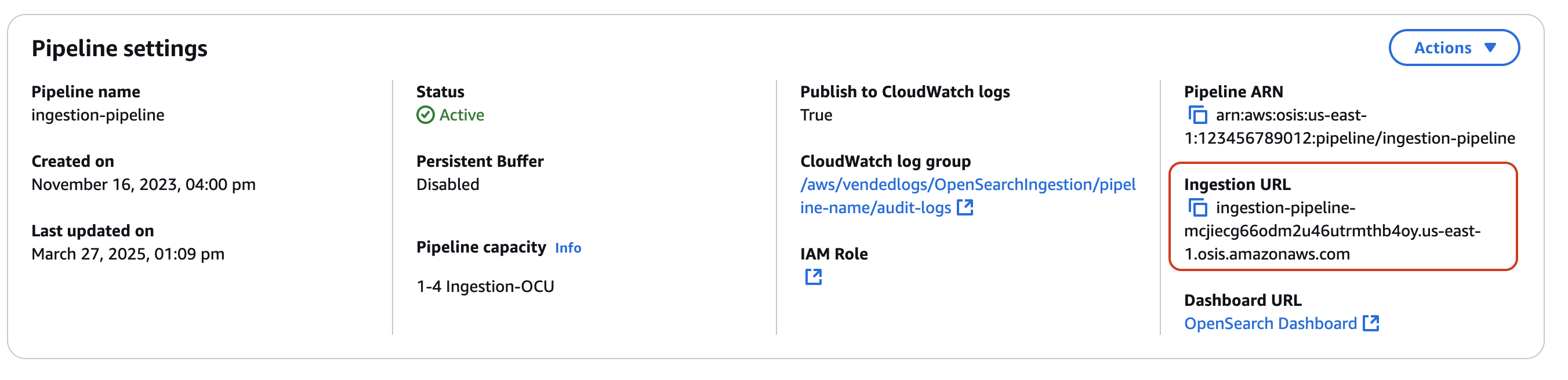
Depois, envie alguns dados de exemplo para o caminho de ingestão. O exemplo de solicitação a seguir usa [awscurl](https://github.com/okigan/awscurl) para enviar um único arquivo de log para o pipeline:
```
awscurl --service osis --region {{us-east-1}} \
-X POST \
-H "Content-Type: application/json" \
-d '[{"time":"2014-08-11T11:40:13+00:00","remote_addr":"122.226.223.69","status":"404","request":"GET http://www.k2proxy.com//hello.html HTTP/1.1","http_user_agent":"Mozilla/4.0 (compatible; WOW64; SLCC2;)"}]' \
https://{{pipeline-endpoint}}.{{us-east-1}}.osis.amazonaws.com/logs
```
Você obterá uma resposta `200 OK`.
Agora, consulte o índice `my_logs` para garantir que a entrada do log tenha sido ingerida com sucesso:
```
awscurl --service aoss --region {{us-east-1}} \
-X GET \
https://{{collection-id}}.{{us-east-1}}.aoss.amazonaws.com/my_logs/_search | json_pp
```
**Resposta de exemplo**:
```
{
"took":348,
"timed_out":false,
"_shards":{
"total":0,
"successful":0,
"skipped":0,
"failed":0
},
"hits":{
"total":{
"value":1,
"relation":"eq"
},
"max_score":1.0,
"hits":[
{
"_index":"my_logs",
"_id":"1%3A0%3ARJgDvIcBTy5m12xrKE-y",
"_score":1.0,
"_source":{
"time":"2014-08-11T11:40:13+00:00",
"remote_addr":"122.226.223.69",
"status":"404",
"request":"GET http://www.k2proxy.com//hello.html HTTP/1.1",
"http_user_agent":"Mozilla/4.0 (compatible; WOW64; SLCC2;)",
"@timestamp":"2023-04-26T05:22:16.204Z"
}
}
]
}
}
```
## Recursos relacionados
Este tutorial apresentou um caso de uso simples de ingestão de um único documento via HTTP. Em cenários de produção, você configurará seus aplicativos cliente (como o Fluent Bit, o Kubernetes ou o OpenTelemetry Collector) para enviar dados para um ou mais pipelines. Seus pipelines provavelmente serão mais complexos do que o exemplo simples deste tutorial.
Para começar a configurar seus clientes e ingerir dados, consulte os seguintes recursos:
+ [Criação e gerenciamento de pipelines](creating-pipeline.md#create-pipeline)
+ [Configurando seus clientes para enviar dados para OpenSearch o Inestion](configure-client.md)
+ [Documentação do Data Prepper](https://opensearch.org/docs/latest/clients/data-prepper/index/)