Técnicas de geração de prompts para compreensão visual
nota
Esta documentação é para o Amazon Nova versão 1. Para obter informações sobre como criar prompts de compreensão multimodal no Amazon Nova 2, acesse Como gerar prompts de entradas multimodais.
As técnicas a seguir de geração de prompts visuais ajudarão você a criar melhores prompts para o Amazon Nova.
Tópicos
A disposição é importante
Recomendamos que você coloque os arquivos de mídia (como imagens ou vídeos) antes de adicionar qualquer documento, seguidos pelo texto de instrução ou prompts para orientar o modelo. Embora as imagens colocadas após o texto ou intercaladas com texto ainda tenham uma performance adequada, se o caso de uso permitir, a estrutura {media_file}-then-{text} é a abordagem preferencial.
O modelo a seguir pode ser usado para colocar arquivos de mídia antes do texto ao realizar a compreensão visual.
{ "role": "user", "content": [ { "image": "..." }, { "video": "..." }, { "document": "..." }, { "text": "..." } ] }
Nenhuma estrutura seguida |
Prompt otimizado |
|
|---|---|---|
Usuário |
Explique o que está acontecendo na imagem [Image1.png] |
[Image1.png] Explique o que está acontecendo na imagem. |
Vários arquivos de mídia com componentes visuais
Em situações em que você fornece vários arquivos de mídia em turnos, introduza cada imagem com uma etiqueta numerada. Por exemplo, se você usar duas imagens, rotule-as Image
1: e Image 2:. Se você usar três vídeos, rotule-os Video
1:, Video 2: e Video 3:. Você não precisa de novas linhas entre as imagens ou entre as imagens e o prompt.
O modelo abaixo pode ser usado para colocar vários arquivos de mídia:
messages = [ { "role": "user", "content": [ {"text":"Image 1:"}, {"image": {"format": "jpeg", "source": {"bytes": img_1_base64}}}, {"text":"Image 2:"}, {"image": {"format": "jpeg", "source": {"bytes": img_2_base64}}}, {"text":"Image 3:"}, {"image": {"format": "jpeg", "source": {"bytes": img_3_base64}}}, {"text":"Image 4:"}, {"image": {"format": "jpeg", "source": {"bytes": img_4_base64}}}, {"text":"Image 5:"}, {"image": {"format": "jpeg", "source": {"bytes": img_5_base64}}}, {"text":user_prompt}, ], } ]
Prompt não otimizado |
Prompt otimizado |
|---|---|
|
Descreva o que você vê na segunda imagem. [Image1.png] [Image2.png] |
[Image1.png] [Image2.png] Descreva o que você vê na segunda imagem. |
|
A segunda imagem está descrita no documento incluído? [Image1.png] [Image2.png] [Document1.pdf] |
[Image1.png] [Image2.png] [Document1.pdf] A segunda imagem está descrita no documento incluído? |
Devido aos longos tokens de contexto dos tipos de arquivo de mídia, o prompt do sistema indicado no início do prompt pode não ser respeitado em determinadas ocasiões. Nessa circunstância, recomendamos que você mova todas as instruções do sistema para turnos do usuário e siga as orientações gerais de {media_file}-then-{text}. Isso não afeta a geração de prompts do sistema com RAG, agentes ou uso de ferramentas.
Use as instruções do usuário para obter detalhes sobre tarefas de compreensão da visão
Para a compreensão de vídeo, o número de tokens no contexto torna as recomendações em A disposição é importante muito importantes. Use o prompt do sistema para coisas mais gerais, como tom e estilo. Recomendamos que você mantenha as instruções relacionadas ao vídeo como parte do prompt do usuário para uma melhor performance.
O modelo a seguir pode ser usado para instruções aprimoradas:
{ "role": "user", "content": [ { "video": { "format": "mp4", "source": { ... } } }, { "text": "You are an expert in recipe videos. Describe this video in less than 200 words following these guidelines: ..." } ] }
Assim como no texto, recomendamos aplicar uma cadeia de pensamento em imagens e vídeos para obter melhores desempenhos. Também recomendamos que você coloque as diretivas da cadeia de pensamento no prompt do sistema, mantendo outras instruções no prompt do usuário.
Importante
O modelo do Amazon Nova Premier é um modelo de inteligência superior da família do Amazon Nova, capaz de lidar com tarefas mais complexas. Se suas tarefas exigirem um pensamento avançado em cadeia de pensamento, recomendamos que você utilize o modelo de prompt fornecido em Dar tempo ao Amazon Nova pensar (cadeia de pensamento). Essa abordagem pode ajudar a aprimorar as habilidades analíticas e de resolução de problemas do modelo.
Poucos exemplares capturados
Assim como nos modelos de texto, recomendamos que você forneça exemplos de imagens para melhorar o desempenho de compreensão da imagem (exemplos de vídeos não podem ser fornecidos devido à limitação de um único vídeo por inferência). Recomendamos que você coloque os exemplos no prompt do usuário, depois do arquivo de mídia, em vez de fornecê-los no prompt do sistema.
| 0-Shot | 2-Shot | |
|---|---|---|
| User | [Image 1] | |
| Assistant | The image 1 description | |
| User | [Image 2] | |
| Assistant | The image 2 description | |
| User | [Image 3] Explique o que está acontecendo na imagem |
[Image 3] Explique o que está acontecendo na imagem |
Detecção de caixa delimitadora
Caso precise identificar as coordenadas da caixa delimitadora de um objeto, você pode utilizar o modelo do Amazon Nova para gerar caixas delimitadoras em uma escala de [0, 1000]. Depois de obter essas coordenadas, você pode redimensioná-las com base nas dimensões da imagem como uma etapa de pós-processamento. Para obter informações mais detalhadas sobre como realizar essa etapa de pós-processamento, consulte o caderno do Amazon Nova Image Grounding
Confira abaixo um exemplo de prompt para detecção de caixa delimitadora:
Detect bounding box of objects in the image, only detect {item_name} category objects with high confidence, output in a list of bounding box format. Output example: [ {"{item_name}": [x1, y1, x2, y2]}, ... ] Result:
Estilo ou saídas mais completas
A saída de compreensão do vídeo pode ser muito curta. Se você quiser saídas mais longas, recomendamos criar uma persona para o modelo. Você pode direcionar essa persona para responder da maneira desejada, de forma semelhante à utilização do perfil do sistema.
Outras modificações nas respostas podem ser obtidas com técnicas de one-shot e few-shot. Forneça exemplos do que seria uma boa resposta, e o modelo poderá imitar aspectos dela ao gerar respostas.
Extrair o conteúdo do documento para o Markdown
O Amazon Nova Premier demonstra recursos aprimorados para entender gráficos incorporados em documentos e a capacidade de ler e compreender conteúdo de domínios complexos, como artigos científicos. Além disso, o Amazon Nova Premier mostra um desempenho aprimorado ao extrair o conteúdo do documento e pode gerar essas informações nos formatos Markdown Table e Latex.
O exemplo a seguir fornece uma tabela em uma imagem, junto com um prompt para que o Amazon Nova Premier converta o conteúdo da imagem em uma tabela Markdown. Depois que o Markdown (ou Latex Representation) for criado, você poderá usar ferramentas para converter o conteúdo em JSON ou outra saída estruturada.
Make a table representation in Markdown of the image provided.
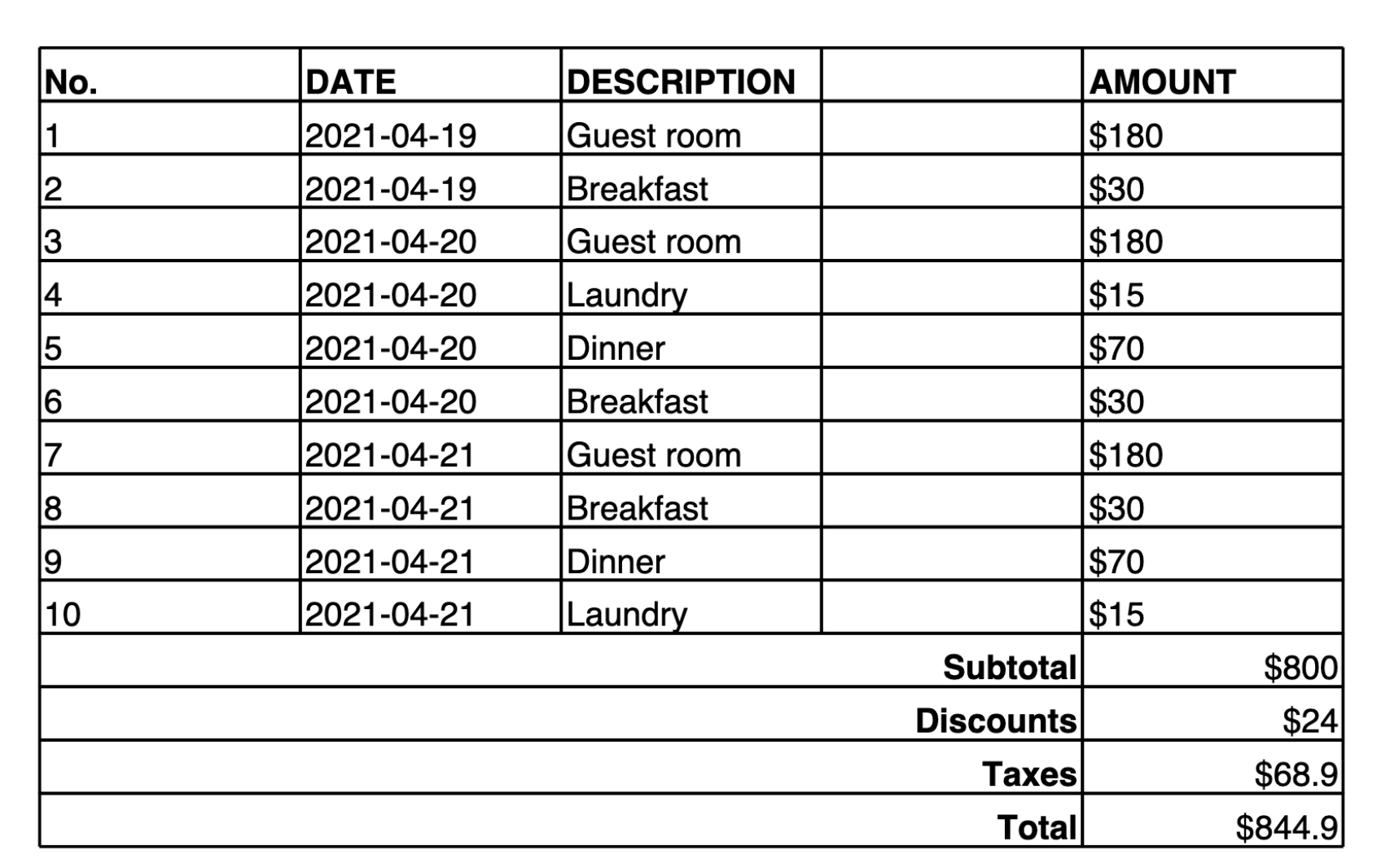
Veja aqui a saída fornecida pelo modelo:
| No. | DATE | DESCRIPTION | AMOUNT | |-----|------------|-------------|--------| | 1 | 2021-04-19 | Guest room | $180 | | 2 | 2021-04-19 | Breakfast | $30 | | 3 | 2021-04-20 | Guest room | $180 | | 4 | 2021-04-20 | Laundry | $15 | | 5 | 2021-04-20 | Dinner | $70 | | 6 | 2021-04-20 | Breakfast | $30 | | 7 | 2021-04-21 | Guest room | $180 | | 8 | 2021-04-21 | Breakfast | $30 | | 9 | 2021-04-21 | Dinner | $70 | | 10 | 2021-04-21 | Laundry | $15 | | | | Subtotal | $800 | | | | Discounts | $24 | | | | Taxes | $68.9 | | | | Total | $844.9 |
Essa saída usa notação de tabela personalizada, onde || é usada como separador de coluna e && como separador de linha.
Configurações de parâmetros de inferência para compreensão da visão
Para casos de uso de compreensão da visão, recomendamos que você comece com os parâmetros de inferência temperature definidos como 0 e topK definidos como 1. Depois de observar a saída do modelo, você pode ajustar os parâmetros de inferência com base no caso de uso. Esses valores geralmente dependem da tarefa e da variação necessária, aumentam a configuração de temperatura para induzir mais variações nas respostas.
Classificação de vídeo
Para classificar efetivamente o conteúdo de vídeo em categorias apropriadas, forneça as categorias que o modelo possa usar para classificação. Considere a amostra de prompt a seguir:
[Video] Which category would best fit this video? Choose an option from the list below: \Education\Film & Animation\Sports\Comedy\News & Politics\Travel & Events\Entertainment\Trailers\How-to & Style\Pets & Animals\Gaming\Nonprofits & Activism\People & Blogs\Music\Science & Technology\Autos & Vehicles
Tags de vídeos
O Amazon Nova Premier apresenta uma funcionalidade aprimorada para criar tags de vídeo. Para obter melhores resultados, use a seguinte instrução solicitando tags separadas por vírgula: “Use vírgulas para separar cada tag”. Veja a seguir um exemplo de prompt:
[video] "Can you list the relevant tags for this video? Use commas to separate each tag."
Legendas densas de vídeos
O Amazon Nova Premier demonstra recursos aprimorados para fornecer legendas densas: descrições textuais detalhadas geradas para vários segmentos do vídeo. Aqui está um exemplo de prompt:
[Video] Generate a comprehensive caption that covers all major events and visual elements in the video.
