As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
planejamento de recuperação de desastres
A recuperação de desastres (DR) é um serviço essencial para a continuidade e conformidade dos negócios corporativos. O AMS faz parceria com você para ajudá-lo a planejar, implementar e manter sua estratégia de DR no AMS.
O AMS landing zone (LZ), com várias contas e conta única, fornece alta disponibilidade nativa, multi-AZ e de alta disponibilidade para componentes de infraestrutura do AMS que atendem à maioria dos cenários de proteção contra desastres. No entanto, dependendo da cobertura geográfica da sua empresa, você pode precisar de proteção regional. Para disponibilidade entre regiões e DR, outra conta AMS é necessária em uma região diferente (isso vale tanto para a landing zone com várias contas quanto para a landing zone com uma única conta).
O AMS se alinha à orientação de DR da AWS, conforme descrito neste blog, Recupere rapidamente sistemas de missão crítica em um desastre
Vários sites (ou altamente disponíveis)
Espera quente
Luz piloto
Backup e restauração
Essas opções e o suporte do AMS para elas são descritos nas seções a seguir.
Multi-site ou altamente disponível (HA)
A solução de alta disponibilidade geralmente é fornecida pela funcionalidade integrada do aplicativo, como clustering ou replicação síncrona. Os usuários são direcionados tanto para o Prod quanto para os HA/DR nós. O DNS aponta diretamente para os nós ou por meio de um balanceador de carga elástico (ELB).
Seu arquiteto de nuvem (CA) do AMS trabalhará com você como parte de seu planejamento Well-Architected-Review e de DR.
O HA DR utiliza serviços e recursos AWS de aplicativos e nativos, conforme ilustrado no gráfico a seguir:
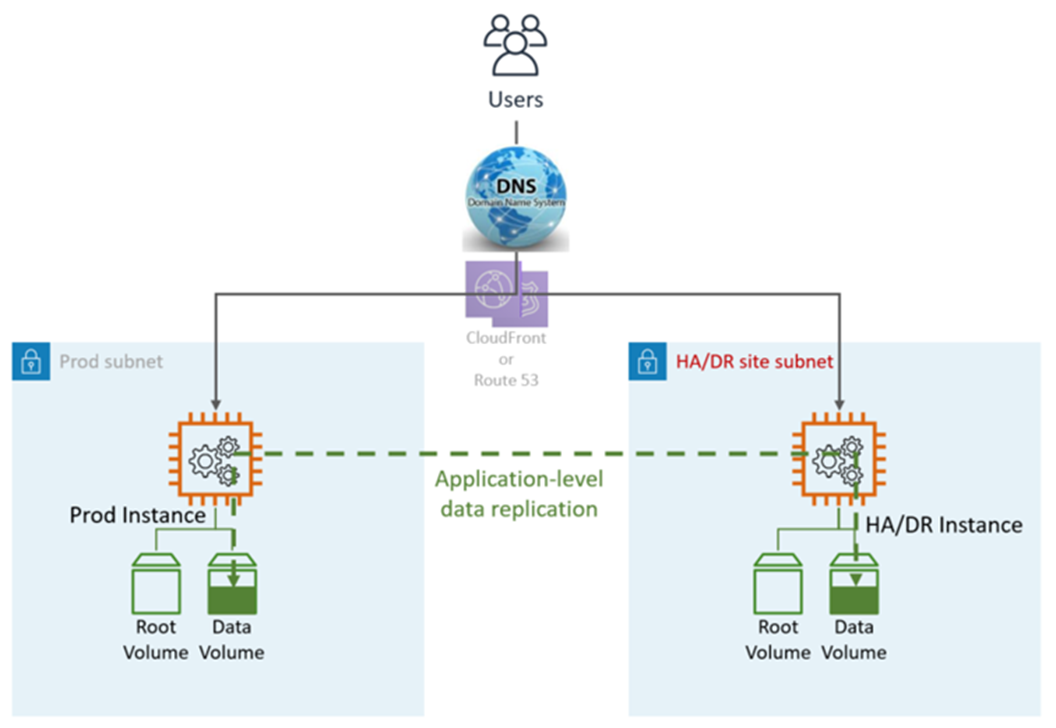
O site de DR pode estar no mesmo local ou em um local diferente Região da AWS.
nota
Uma região diferente (Cross-Region) terá um ambiente diferente do Active Directory.
Etapas de DR (failover): Failover automático, nenhuma etapa manual é necessária. Em caso de falha na LZ primária, os usuários serão automaticamente redirecionados para o nó. DR/HA Isso é obtido pela configuração do DNS e do aplicativo.
Métricas HA DR:
Objetivo de ponto de recuperação (RPO): <5 min
Objetivo de tempo de recuperação e (RTO): <5 min
Manutenção: Alta (mudanças síncronas são necessárias em ambos os ambientes, como configuração de aplicativos, aplicação de patches, SG ou ALB, certificados etc.).
Custo: Alto
Standby passivo
O termo “espera quente” é usado para descrever um cenário de recuperação de desastres (DR) no qual uma versão reduzida do ambiente está sendo executada na nuvem.
A replicação de dados é feita pela camada de aplicativo, geralmente de forma assíncrona, para uma instância on-line, enquanto o restante das instâncias (por exemplo, camada de aplicativo e Web) pode ser desativada para reduzir o custo. Os usuários são direcionados somente para o site de produção. Outros AWS recursos, como o elastic load balancer (ELB), também podem ser pré-provisionados no site de DR.
Seu arquiteto de nuvem (CA) do AMS trabalhará com você como parte de seu planejamento Well-Architected-Review e de DR.
O Warm Standby DR utiliza serviços e recursos AWS de aplicativos e nativos, conforme ilustrado no gráfico a seguir:
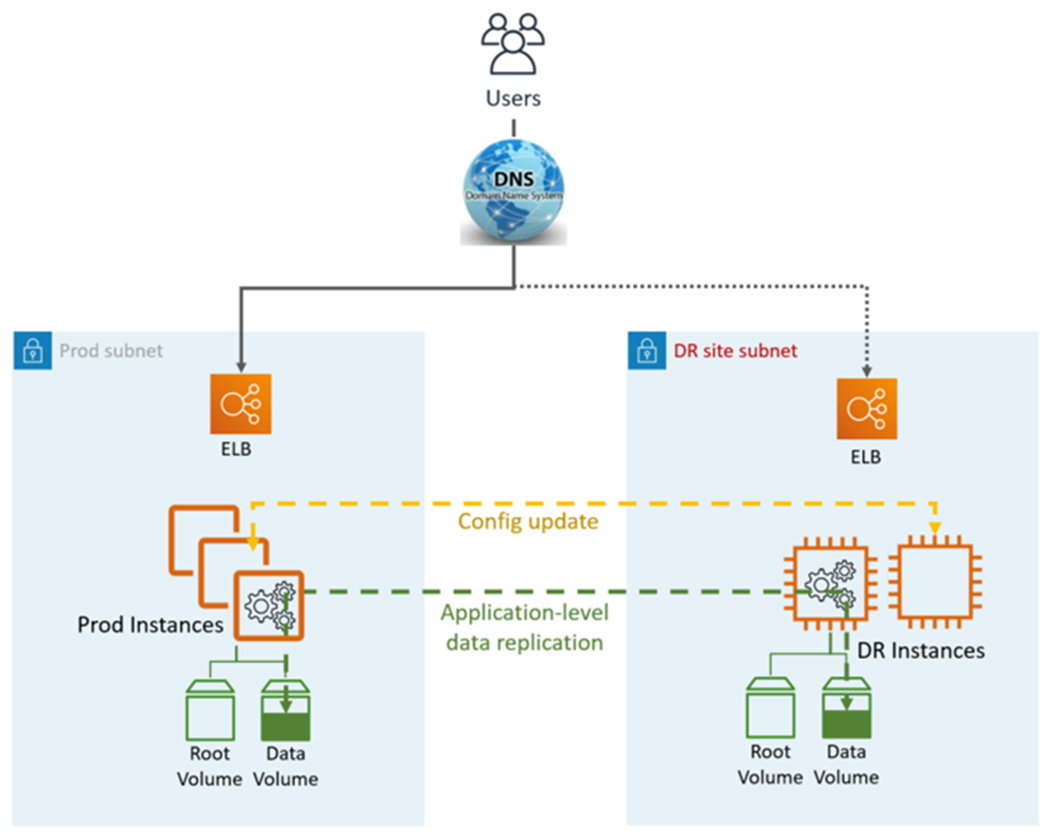
O site de DR pode ser igual ou diferente Região da AWS.
nota
Uma região diferente (Cross-Region) terá um ambiente diferente do Active Directory.
Etapas de DR (failover):
Freie a replicação de dados e torne a instância de dados no site de DR a principal
Atualize a configuração do aplicativo conforme necessário (novo IP, nome do servidor etc.)
Redirecione o DNS para o site de DR (ELB)
Dependências do AD, se necessário (contas de serviço, SPNs, GPOs etc.)
Métricas HA DR:
Objetivo de ponto de recuperação (RPO): <1 hora
Objetivo de tempo de recuperação e (RTO): <1 hora (depende do número de instâncias e da orquestração)
Manutenção: alta (mudanças síncronas são necessárias em ambos os ambientes, como configuração de aplicativos, aplicação de patches, grupos de segurança (SG) ou balanceador de carga de aplicativos (ALB), certificados etc.).
Custo: Médio
Luz piloto
Nessa abordagem de recuperação de desastres (DR), você replica parte do seu ambiente Prod para um conjunto limitado de serviços principais. Uma pequena parte da sua infraestrutura está sempre em execução, sincronizando simultaneamente dados mutáveis (como bancos de dados ou documentos), enquanto outras partes da sua infraestrutura são desligadas e usadas somente durante o teste. Ao contrário de uma abordagem de backup e recuperação, você deve garantir que seus elementos principais mais críticos já estejam configurados e funcionando na zona de pouso do DR (a luz piloto).
Seu arquiteto de nuvem do AMS trabalhará com você como parte de seu planejamento Well-Architected-Review e de DR.
O Pilot Light DR utiliza serviços e recursos AWS de aplicativos e nativos, conforme ilustrado no gráfico a seguir:
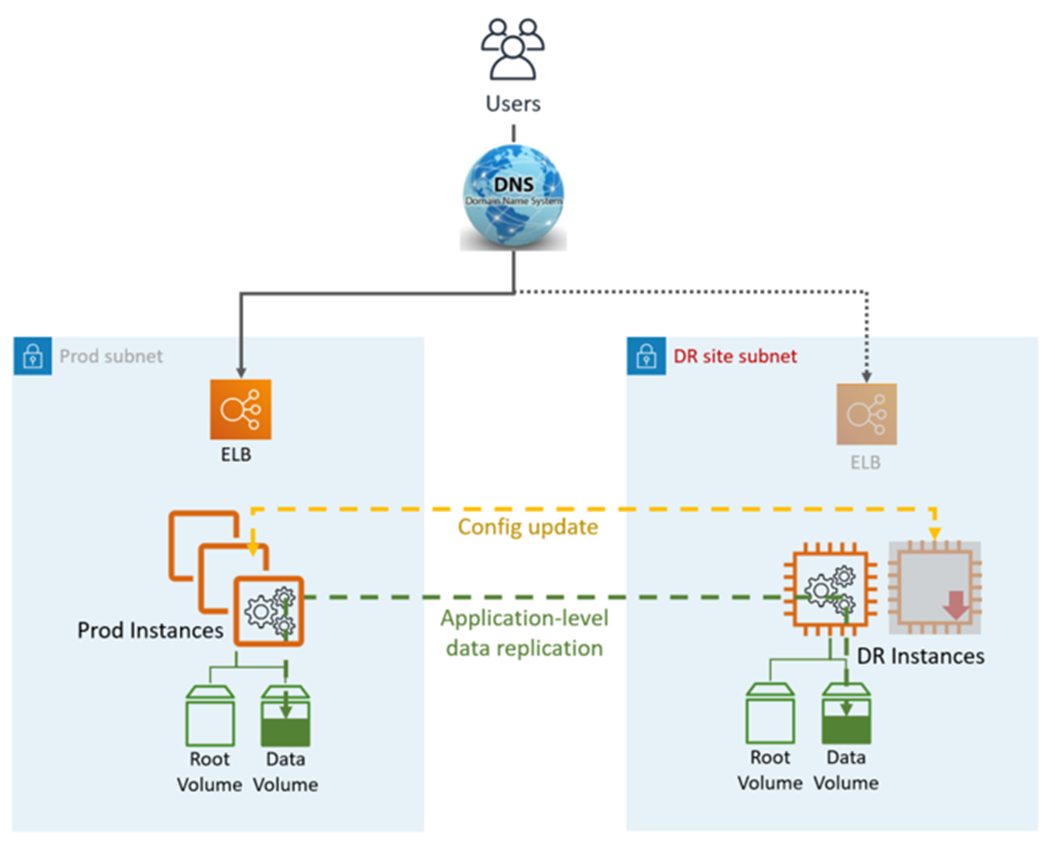
O site de DR pode ser igual ou diferente Região da AWS.
nota
Uma região diferente (Cross-Region) terá um ambiente diferente do Active Directory.
Etapas de DR (failover):
Freie a replicação de dados e torne a instância de dados no site de DR a principal
Inicie as instâncias e a infraestrutura desativadas
Atualize a configuração do aplicativo conforme necessário (novo IP, nome do servidor etc.)
Adicione as instâncias ao ELB conforme necessário
Redirecione o DNS para o site de DR (ELB)
Dependências do AD, se necessário (contas de serviço, SPNs, GPOs etc.)
Métricas de DR do Pilot Light:
Objetivo de ponto de recuperação (RPO): <1 hora
Objetivo de tempo de recuperação e (RTO): aproximadamente 1 hora (depende do número de instâncias e da orquestração)
Manutenção: Média
Custo: Médio
Backup e restauração
Essa abordagem de recuperação de desastres (DR) simples e de baixo custo faz backup de seus dados e aplicativos de qualquer lugar na landing zone de DR para uso durante a recuperação de um desastre.
Seu arquiteto de nuvem do AMS trabalha com você como parte de seu planejamento de Backup e DR.
O Backup and Restore DR utiliza ferramentas e processos automatizados do AMS, conforme ilustrado no gráfico a seguir:
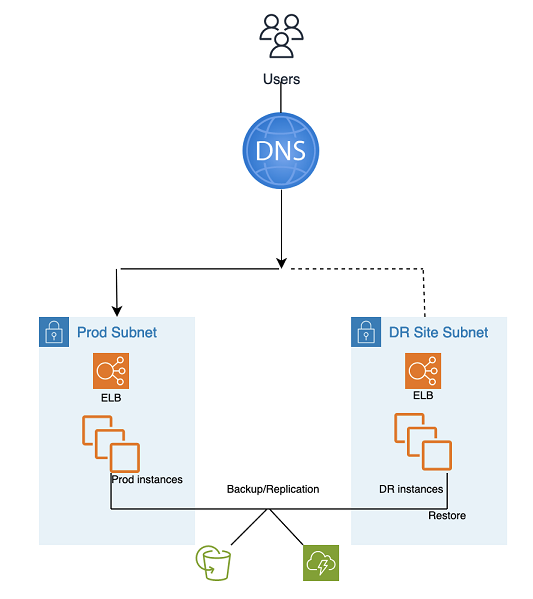
Dois métodos de backup e replicação podem ser usados:
Snapshot do EBS (objetivo de ponto de recuperação (RPO) > 1 hora), conhecido como “EBS”
Recuperação de desastres do AWS Elastic (Recovery Point Objective (RPO) ~ 0,25 horas), conhecido como “DRS”
O site de DR pode estar no mesmo local ou em outro Região da AWS.
nota
Uma região diferente (Cross-Region) tem um ambiente diferente do Active Directory.
Etapas de DR (failover):
Restaure as instâncias a partir de instantâneos (processo em duas etapas com a instância de espaço reservado primeiro)
Atualizar a configuração do aplicativo (novo IP, nome do servidor etc.)
Configure outra infraestrutura conforme necessário (SG, ELB e assim por diante)
Redirecione o DNS para o site de DR (ELB)
Atualize ou restaure dependências do AD, se necessário (contas de serviço, nomes principais de serviço (SPNs), objetos de política de grupo (GPOs) etc.)
Métricas de DR de backup e restauração:
Objetivo de ponto de recuperação (RPO): >1 hora ou ~0,25 horas (depende da solução selecionada - EBS ou DRE)
Objetivo de tempo de recuperação e (RTO): aproximadamente 1 hora (depende do número de instâncias e da orquestração)
Manutenção: Alta (mudanças síncronas são necessárias em ambos os ambientes, como configuração de aplicativos, patches, grupos de segurança ou balanceadores de carga de aplicativos, certificados e assim por diante.
Custo: Médio
Proteção contra desastres para EC2 com instantâneos do EBS no AMS
Pré-requisitos:
Zona de pouso do AMS Prod (fonte)
Zona de pouso do AMS DR (alvo DR)
Os snapshots do EBS estão habilitados para instâncias do EC2 ()AWS Backup
Solução de replicação de instantâneos:
Cross AZ: Não aplicável - os snapshots do EBS estão altamente disponíveis na região por design
Cross-Region: AWS Backup
O diagrama a seguir representa o processo de restauração do EC2 a partir de snapshots do EBS no AMS:
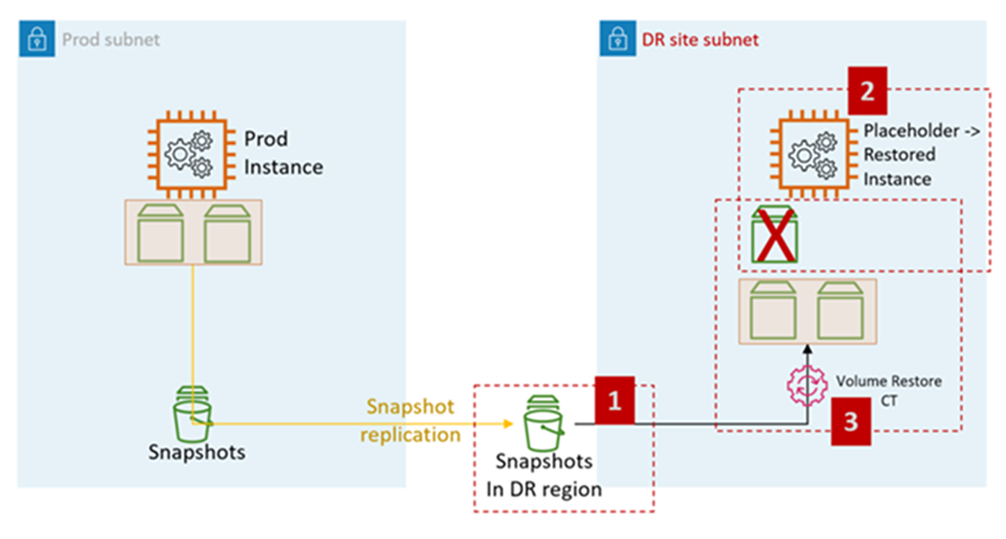
Etapas de DR do EC2 no AMS:
Crie um RFC para compartilhar os instantâneos do EBS com a conta de destino (necessário para Cross-Region DR).
: Gerenciamento, componentes avançados de pilha, EBS Snapshot, compartilhamento
Crie uma pilha EC2 AMS de espaço reservado na sub-rede de destino (sub-rede do site de DR). A recomendação é usar a ingestão de CFN para criar a pilha, pois o cliente pode combinar as etapas de atribuição de grupos de segurança e outras (como adicionar a instância a um ELB) na mesma pilha.
Tipo de alteração: implantação, ingestão, empilhamento a partir do CloudFormation modelo, criação
Eleve um RFC para realizar a restauração do volume da pilha do EC2.
Tipo de alteração: gerenciamento, componentes avançados da pilha, pilha de instâncias do EC2, volumes de restauração.
O CT restaura os volumes dos instantâneos compartilhados na etapa 1 e se conecta à instância de espaço reservado criada na etapa 2.
Funcionalidade de CT de restauração de volume:
Encerrar a instância de espaço reservado
Restaure volumes a partir dos instantâneos
Troque os volumes
Inicie a instância
Sair do domínio antigo
Alterar o nome do host
Reinicializar. Os scripts de bootstrap do AMS unem a instância ao domínio de destino (DR) na inicialização
Entrada CT de restauração de volume:
InstanceId (ID da instância de espaço reservado)
RootDeviceSnapshotId, o snapshot do EBS para o volume raiz restaurado
KMSKeyId, o identificador de chave KMS, ou ARN, para criptografar todos os volumes restaurados na instância do EC2
DeviceNames, até 25 (opcional)
SnapshotIds, até 25 (opcional). Lista de instantâneos dos volumes a serem restaurados
Proteção contra desastres para EC2 com Elastic Disaster Recovery no AMS
Pré-requisitos:
Zona de pouso do AMS Prod (fonte)
Zona de pouso do AMS DR (alvo DR)
Primeiro, você deve inicializar o serviço Elastic Disaster Recovery para tudo em Regiões da AWS que planeja usá-lo.
Crie uma função do IAM em sua landing zone (LZ) de DR para acessar o console do Elastic Disaster Recovery.
Importante: um documento SSM é criado como uma ação pós-lançamento no DRS. Essa ação deve estar ativada em todos os seus servidores nas PostLaunch configurações.
a instância de destino (espaço reservado) deve ter uma chave de tag: “AWSDRS”, valor: "”. AllowLaunchingIntoThisInstance A instância de espaço reservado deve estar no estado interrompido. Caso contrário, o AMS não poderá selecionar a instância de espaço reservado nas configurações de execução e o Elastic Disaster Recovery não poderá restaurar sobre a instância de espaço reservado.
Para obter um diagrama do processo de configuração e restauração do Elastic Disaster Recovery para o EC2 no AMS, consulte Recuperação de desastres do AWS Elastic Arquitetura geral (AWS DRS).
Etapas de DR do EC2 com o Elastic Disaster Recovery no AMS:
Crie uma pilha AMS do EC2 de espaço reservado na sub-rede de destino (sub-rede do site de DR) com as tags adequadas. Para obter mais informações, consulte a seção anterior. Recomendamos usar a ingestão de CFN para criar a pilha, pois você pode combinar as etapas de atribuição de grupos de segurança e marcação da instância, do volume do EBS e outros (como adicionar a instância a um ELB) na mesma pilha.
Tipo de alteração: implantação, ingestão, empilhamento a partir do CloudFormation modelo, criação
Pare a instância de espaço reservado.
Tipo de alteração: gerenciamento, componentes avançados de pilha, instância EC2, parada
Se não for feito na etapa 1, marque a instância de espaço reservado e seu volume do EBS com a chave: “AWSDRS”, valor: "”. AllowLaunchingIntoThisInstance
Tipo de alteração: Gerenciamento, Componentes avançados da pilha, Tag, Atualização.
Use a instância de espaço reservado da etapa 1 como destino em Iniciar na ID da instância, Configurações de inicialização do DRS para o servidor de origem. Inicie o treinamento de recuperação de instâncias a partir do console do Elastic Disaster Recovery para o servidor de origem.
nota
Os volumes da instância de espaço reservado são retidos na conta. Para excluir esses volumes, envie um item Gerenciamento | Componentes avançados da pilha | Volume do EBS | Excluir tipo de alteração (ct-3e3h8u0sp5z80) ao final da operação de recuperação de desastres.
Fluxo de trabalho do Elastic Disaster Recovery
A instância de destino (espaço reservado) precisa estar no estado interrompido
Troque os volumes e exclua o volume raiz de origem (espaço reservado)
Inicie a instância
Execute as ações de pós-lançamento para concluir os seguintes itens:
Ative o agente SSM.
Troque os volumes e exclua o volume raiz de origem (espaço reservado).
Inicie a instância
Execute o documento PostLaunchScript SSM. Este documento faz o seguinte:
Sai do domínio antigo.
Muda o nome do host.
Reinicializar. Os scripts de bootstrap do AMS unem a instância ao domínio de destino (DR) durante a inicialização.
