As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Integração de tabelas do Amazon S3 com AWS Glue Data Catalog and AWS Lake Formation
A funcionalidade Tabelas do Amazon S3 fornece armazenamento do S3 especificamente otimizado para workloads de analytics, melhorando a performance das consultas e reduzindo os custos. Os dados na funcionalidade Tabelas do S3 são armazenados em um novo tipo de bucket: um bucket de tabela, que armazena tabelas como sub-recursos. As tabelas do S3 têm suporte integrado para o padrão Apache Iceberg, que permite que você consulte facilmente dados em tabelas em buckets de tabelas do Amazon S3 usando mecanismos de consulta conhecidos, como o Apache Spark.
Você pode integrar as tabelas do Amazon S3 AWS Glue Data Catalog usando controles de acesso do IAM ou com subsídios do IAM e do Lake Formation:
-
Controle de acesso do IAM: usa políticas do IAM para controlar o acesso às tabelas e ao catálogo de dados do S3. Nessa abordagem de controle de acesso, você precisa de permissões do IAM nos recursos das tabelas do S3 e nos objetos do catálogo de dados para acessar os recursos.
-
Controle de acesso do Lake Formation: usa AWS Lake Formation concessões, além das permissões AWS Glue do IAM, para controlar o acesso às tabelas do S3 por meio do catálogo de dados. Nesse modo, os diretores exigem permissões do IAM para interagir com o catálogo de dados, e as concessões do Lake Formation determinam quais recursos do catálogo (bancos de dados, tabelas, colunas, linhas) o diretor pode acessar. Esse modo oferece suporte a controle de acesso de baixa granularidade (concessões em nível de banco de dados e em nível de tabela) e controle de acesso refinado (segurança em nível de coluna e nível de linha). Quando uma função registrada é configurada e a venda de credenciais está ativada, as permissões IAM do S3 Tables não são necessárias para o diretor, pois o Lake Formation vende credenciais em nome do diretor usando a função registrada. O controle de acesso do Lake Formation também oferece suporte à venda de credenciais para mecanismos de análise de terceiros.
Esta seção fornece orientação para configurar a integração com AWS Lake Formation os seguintes cenários:
-
Cenário A: você integrou tabelas e catálogo de dados do S3 usando controles de acesso do IAM e agora planeja usar AWS Lake Formation. Para saber mais, consulte Alterando os controles de acesso para integração com tabelas do S3.
-
Cenário B: Você planeja integrar as tabelas e o catálogo de dados do S3 usando AWS Lake Formation e não os tem integrados em sua conta e região atualmente. Comece com a Pré-requisitos para integrar o catálogo de tabelas do Amazon S3 ao Data Catalog e o Lake Formation seção e sigaHabilitar a integração de Tabelas do Amazon S3.
-
Cenário C: você integrou tabelas e catálogo de dados do S3 usando AWS Lake Formation e agora planeja usar o IAM. Para saber mais, consulte Alterando os controles de acesso para integração com tabelas do S3.
Certifique-se de seguir as etapas em Integração de tabelas do S3 com serviços de AWS análise para ter as permissões apropriadas para acessar os recursos AWS Glue Data Catalog e seus recursos de tabela e trabalhar com serviços de AWS análise.
Tópicos
Como funciona a integração do Data Catalog e do Lake Formation
Quando você integra o catálogo de tabelas do S3 ao Data Catalog e ao Lake Formation, o serviço AWS Glue cria um único catálogo federado chamado s3tablescatalog no Data Catalog padrão de sua conta específico da sua Região da AWS. A integração mapeia todos os recursos do bucket de tabelas do Amazon S3 em sua conta e Região da AWS no catálogo federado da seguinte maneira:
Os buckets de tabela do Amazon S3 se tornam um catálogo de vários níveis no Data Catalog.
-
O namespace do Amazon S3 associado é registrado como um banco de dados no Data Catalog.
-
As tabelas do Amazon S3 no bucket de tabela se tornam tabelas no Data Catalog.
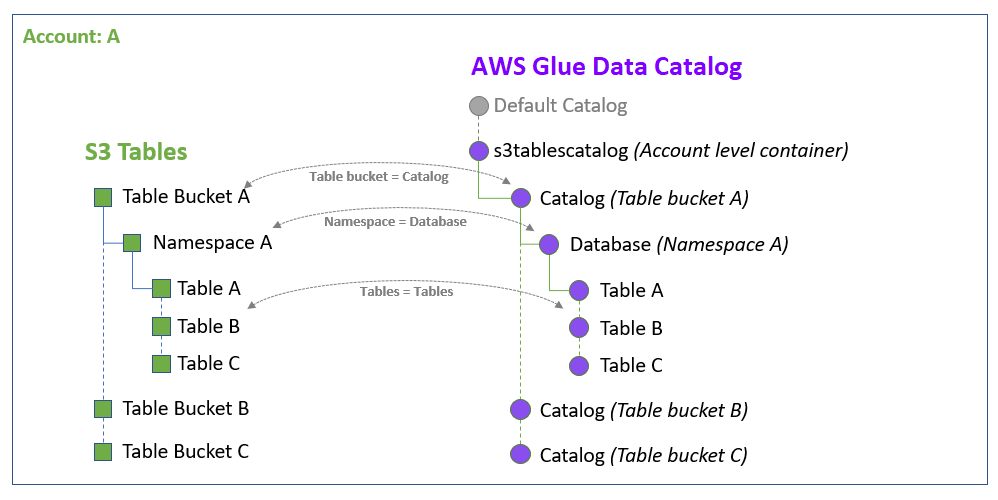
Após a integração com o Lake Formation, você pode criar tabelas Apache Iceberg no catálogo de tabelas e acessá-las por meio de mecanismos de AWS análise integrados, como o Amazon Athena Amazon EMR, bem como mecanismos de análise de terceiros.
Quando você também ativa o Lake Formation com integração, ele permite um controle de acesso refinado. AWS Lake Formation Essa abordagem de segurança significa que, além das permissões AWS Identity and Access Management (IAM), você deve conceder ao diretor do IAM as permissões do Lake Formation em suas tabelas antes de poder trabalhar com elas.
Há dois tipos principais de permissões no AWS Lake Formation:
-
As permissões de acesso a metadados controlam a capacidade de criar, ler, atualizar e excluir tabelas e bancos de dados de metadados no Catálogo de Dados.
-
As permissões de acesso aos dados subjacentes controlam a capacidade de ler e gravar dados nos locais do Amazon S3 subjacentes para os quais os recursos do Catálogo de Dados apontam.
O Lake Formation usa conjuntamente um modelo de permissões próprio e o modelo de permissões do IAM para controlar o acesso aos recursos do Catálogo de Dados e aos dados subjacentes:
-
Para que uma solicitação de acesso aos recursos do Catálogo de Dados ou os dados subjacentes seja bem-sucedida, ela deve passar pelas verificações de permissão do IAM e do Lake Formation.
-
As permissões do IAM controlam o acesso ao Lake Formation, às AWS Glue APIs e aos recursos, enquanto as permissões do Lake Formation controlam o acesso aos recursos do catálogo de dados, às localizações do Amazon S3 e aos dados subjacentes.
As permissões do Lake Formation se aplicam somente na região em que foram concedidas, e uma entidade principal deve ser autorizada por um administrador do data lake ou por outra entidade principal com as permissões necessárias para receber as permissões do Lake Formation.
