As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Solução para monitorar aplicações Kafka com o Amazon Managed Grafana
As aplicações desenvolvidas com base no Apache Kafka
nota
Essa solução não é compatível com o monitoramento de aplicações do Amazon Managed Streaming for Apache Kafka. Para obter mais informações sobre o monitoramento de aplicações do Amazon MSK, consulte Monitorar um cluster do Amazon MSK no Amazon Managed Streaming for Apache Kafka Developer Guide.
Essa solução configura:
-
O espaço de trabalho do Amazon Managed Service for Prometheus armazena métricas do Kafka e da Máquina virtual Java (JVM) do seu cluster do Amazon EKS.
-
Coleta de métricas específicas do Kafka e da JVM usando o CloudWatch agente, bem como um complemento do agente. CloudWatch As métricas são configuradas para serem enviadas para o espaço de trabalho do Amazon Managed Service for Prometheus.
-
Seu espaço de trabalho do Amazon Managed Grafana para extrair essas métricas e criar painéis para ajudar a monitorar o cluster.
nota
Essa solução fornece métricas da JVM e do Kafka para sua aplicação em execução no Amazon EKS, mas não inclui métricas do Amazon EKS. Você pode usar a solução observabilidade para monitorar o Amazon EKS para ver métricas e alertas do seu cluster Amazon EKS.
Sobre esta solução
Essa solução configura um espaço de trabalho do Amazon Managed Grafana para fornecer métricas para sua aplicação do Apache Kafka. As métricas são usadas para gerar painéis que ajudam você a operar sua aplicação com mais eficiência, fornecendo insights sobre o desempenho e a workload da aplicação do Kafka.
A imagem a seguir mostra um exemplo de um dos painéis criados por essa solução.
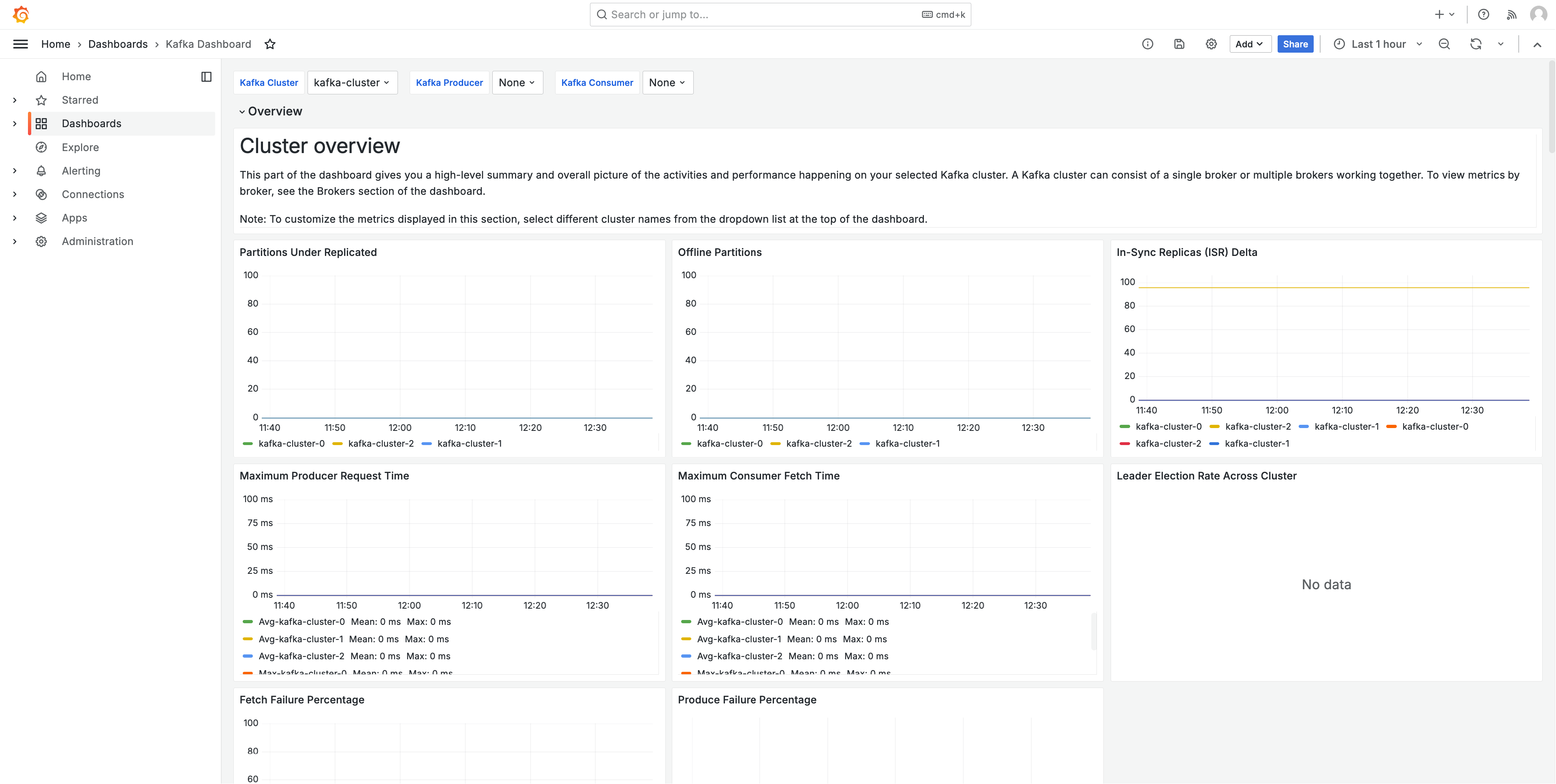
As métricas são extraídas com um intervalo de extração de um minuto. Os dashboards mostram métricas agregadas a um minuto, cinco minutos ou mais, com base na métrica específica.
Para obter uma lista das métricas rastreadas por essa solução, consulte Lista de métricas monitoradas.
Custos
Essa solução cria e usa recursos no seu espaço de trabalho. Você será cobrado pelo uso padrão dos recursos criados, incluindo:
-
Acesso dos usuários ao espaço de trabalho do Amazon Managed Grafana. Para obter mais informações sobre preços, consulte Preço do Amazon Managed Grafana
. -
Ingestão e armazenamento de métricas do Amazon Managed Service for Prometheus e análise de métricas (processamento de exemplos de consultas). O número de métricas usadas por essa solução depende da configuração e do uso da aplicação.
Você pode visualizar as métricas de ingestão e armazenamento no Amazon Managed Service for Prometheus CloudWatch usando Para obter mais informações, consulte as CloudWatchmétricas no Guia do usuário do Amazon Managed Service for Prometheus.
Você pode estimar o custo usando a Calculadora de Preços na página de preços do Amazon Managed Service for Prometheus
. A quantidade de métricas dependerá do número de nós no cluster e das métricas que as aplicações produzem. -
Custos de rede. Você pode incorrer em cobranças AWS de rede padrão para tráfego entre zonas de disponibilidade, regiões ou outros tipos de tráfego.
As calculadoras de preços, disponíveis na página de preços de cada produto, podem ajudar a entender os possíveis custos de sua solução. As informações a seguir podem ajudar a obter um custo básico para a solução em execução na mesma zona de disponibilidade do cluster do Amazon EKS.
| Produto | Métrica da calculadora | Valor |
|---|---|---|
Amazon Managed Service for Prometheus |
Série ativa |
95 (por pod do Kafka) |
Intervalo médio da coleta |
60 (segundos) |
|
Amazon Managed Grafana |
Número de ativos editors/administrators |
1 (ou mais, com base em seus usuários) |
Esses números são os números base para uma solução que executa o Kafka no Amazon EKS. Isso fornecerá uma estimativa dos custos básicos. Conforme você adiciona pods do Kafka a sua aplicação, os custos aumentam, conforme mostrado. Esses custos excluem os custos de uso da rede, que variam com base no fato de o espaço de trabalho Amazon Managed Grafana, o espaço de trabalho do Amazon Managed Service for Prometheus e o cluster Amazon EKS estarem na mesma zona de disponibilidade e VPN. Região da AWS
Pré-requisitos
Essa solução exige que você tenha realizado as ações a seguir antes de usá-la.
-
Você deve ter ou criar um cluster do Amazon Elastic Kubernetes Service que deseja monitorar, e o cluster deve ter pelo menos um nó. O cluster deve ter o acesso ao endpoint do servidor de API definido para incluir acesso privado (ele também pode permitir acesso público).
O modo de autenticação deve incluir acesso à API (pode ser definido como
APIouAPI_AND_CONFIG_MAP). Isso permite que a implantação da solução use entradas de acesso.O seguinte deve ser instalado no cluster (verdadeiro por padrão ao criar o cluster por meio do console, mas deve ser adicionado se você criar o cluster usando a AWS API ou AWS CLI): Amazon EKS Pod Identity Agent, AWS CNI, CoreDNS e Amazon EBS CSI AddOns Driver (o driver CSI do Amazon EBS AddOn não é tecnicamente necessário para a solução Kube-proxy , mas é necessário para a maioria dos aplicativos Kafka).
Salve o nome do cluster para especificar posteriormente. Isso pode ser encontrado nos detalhes do cluster no console do Amazon EKS.
nota
Para obter detalhes sobre como criar um cluster do Amazon EKS, consulte Conceitos básicos do Amazon EKS.
-
Você deve estar executando uma aplicação Apache Kafka em Máquinas virtuais Java no seu cluster Amazon EKS.
-
Você deve criar um espaço de trabalho do Amazon Managed Service for Prometheus no mesmo espaço de trabalho do seu cluster Amazon Conta da AWS EKS. Para obter detalhes, consulte Create a workspace no Guia do usuário do Amazon Managed Service for Prometheus.
Salve o ARN do espaço de trabalho do Amazon Managed Service for Prometheus para especificar posteriormente.
-
Você deve criar um espaço de trabalho Amazon Managed Grafana com o Grafana versão 9 ou mais recente, da mesma Região da AWS forma que seu cluster Amazon EKS. Para obter detalhes sobre como criar um espaço de trabalho, consulte Criar um espaço de trabalho do Amazon Managed Grafana.
A função do espaço de trabalho deve ter permissões para acessar o Amazon Managed Service for Prometheus e as APIs da Amazon. CloudWatch A maneira mais fácil de fazer isso é usar Service-managedas permissões e selecionar o Amazon Managed Service para Prometheus e. CloudWatch Você também pode adicionar manualmente AmazonGrafanaCloudWatchAccessas políticas AmazonPrometheusQueryAccesse à sua função do IAM do workspace.
Salve o ID e o endpoint do espaço de trabalho do Amazon Managed Grafana para especificar posteriormente. O ID está no formato
g-123example. O ID e o endpoint podem ser encontrados no console do Amazon Managed Grafana. O endpoint é o URL do espaço de trabalho e inclui o ID. Por exemplo, .https://g-123example.grafana-workspace.<region>.amazonaws.com/
nota
Embora não seja estritamente necessário configurar a solução, você deve configurar a autenticação de usuário no espaço de trabalho do Amazon Managed Grafana antes que os usuários possam acessar os dashboards criados. Para obter mais informações, consulte Autenticar usuários nos espaços de trabalho do Amazon Managed Grafana.
Usar esta solução
Essa solução configura a AWS infraestrutura para oferecer suporte a relatórios e métricas de monitoramento de um aplicativo Kafka executado em um cluster Amazon EKS. É possível instalá-la usando AWS Cloud Development Kit (AWS CDK):
nota
Para usar essa solução para monitorar um cluster Amazon EKS com AWS CDK
-
Certifique-se de ter concluído todas as etapas dos pré-requisitos.
-
Faça download de todos os arquivos da solução do Amazon S3. Os arquivos estão localizados em
s3://aws-observability-solutions/Kafka_EKS/OSS/CDK/v1.0.0/iac, e você pode fazer o download deles com o comando do Amazon S3 a seguir. Execute esse comando em uma pasta no ambiente de linha de comandos.aws s3 sync s3://aws-observability-solutions/Kafka_EKS/OSS/CDK/v1.0.0/iac/ .Você não precisa modificar esses arquivos.
-
No ambiente de linha de comandos (na pasta em que você fez o download dos arquivos da solução), execute os comandos a seguir.
Defina as variáveis de ambiente necessárias. Substitua
REGIONAMG_ENDPOINT,EKS_CLUSTER, eAMP_ARNpor seu Região da AWS endpoint de espaço de trabalho Amazon Managed Grafana (no formulário)http://g-123example.grafana-workspace.us-east-1.amazonaws.com, nome do cluster Amazon EKS e ARN do espaço de trabalho Amazon Managed Service for Prometheus.export AWS_REGION=REGIONexport AMG_ENDPOINT=AMG_ENDPOINTexport EKS_CLUSTER_NAME=EKS_CLUSTERexport AMP_WS_ARN=AMP_ARN -
Você deve criar anotações que possam ser usadas pela implantação. Você pode optar por anotar diretamente um namespace, implantação, statefulset, daemonset ou seus pods. A solução do Kafka requer cinco anotações. Você usará
kubectlpara anotar seus recursos com os seguintes comandos:kubectl annotate<resource-type><resource-value>instrumentation.opentelemetry.io/inject-java=true kubectl annotate<resource-type><resource-value>cloudwatch.aws.amazon.com/inject-jmx-jvm=true kubectl annotate<resource-type><resource-value>cloudwatch.aws.amazon.com/inject-jmx-kafka=true kubectl annotate<resource-type><resource-value>cloudwatch.aws.amazon.com/inject-jmx-kafka-producer=true kubectl annotate<resource-type><resource-value>cloudwatch.aws.amazon.com/inject-jmx-kafka-consumer=trueSubstitua
<resource-type>e<resource-value>pelos valores corretos para seu sistema. Por exemplo, para anotar sua implantaçãofoo, seu primeiro comando seria:kubectl annotate deployment foo instrumentation.opentelemetry.io/inject-java=true -
Crie um token de conta de serviço com acesso ADMIN para chamar as APIs HTTP do Grafana. Para obter detalhes, consulte Usando contas de serviço. Você pode usar o AWS CLI com os seguintes comandos para criar o token. Você precisará
GRAFANA_IDsubstituir o pelo ID do seu espaço de trabalho Grafana (ele estará no formulário).g-123exampleEssa chave vai expirar após 7.200 segundos, ou 2 horas. Você pode alterar a hora (seconds-to-live), se necessário. A implantação leva menos de uma hora.# creates a new service account (optional: you can use an existing account) GRAFANA_SA_ID=$(aws grafana create-workspace-service-account \ --workspace-idGRAFANA_ID\ --grafana-role ADMIN \ --name grafana-operator-key \ --query 'id' \ --output text) # creates a new token for calling APIs export AMG_API_KEY=$(aws grafana create-workspace-service-account-token \ --workspace-id $managed_grafana_workspace_id \ --name "grafana-operator-key-$(date +%s)" \ --seconds-to-live 7200 \ --service-account-id $GRAFANA_SA_ID \ --query 'serviceAccountToken.key' \ --output text)Disponibilize a chave de API para o AWS CDK adicionando-a AWS Systems Manager com o comando a seguir.
AWS_REGIONSubstitua pela região em que sua solução será executada (no formulárious-east-1).aws ssm put-parameter --name "/observability-aws-solution-kafka-eks/grafana-api-key" \ --type "SecureString" \ --value $AMG_API_KEY \ --regionAWS_REGION\ --overwrite -
Execute o comando
makea seguir, que vai instalar todas as outras dependências do projeto.make deps -
Por fim, execute o AWS CDK projeto:
make build && make pattern aws-observability-solution-kafka-eks-$EKS_CLUSTER_NAME deploy -
[Opcional] Depois que a criação da pilha for concluída, você poderá usar o mesmo ambiente para criar mais instâncias da pilha para outras aplicações do Kafka executadas em clusters do Amazon EKS na mesma região, desde que preencha os outros pré-requisitos de cada um (incluindo espaços de trabalho separados do Amazon Managed Grafana e do Amazon Managed Service for Prometheus). Você precisará redefinir os comandos
exportcom os novos parâmetros.
Quando a criação da pilha for concluída, o espaço de trabalho Amazon Managed Grafana será preenchido com um painel mostrando as métricas para suas aplicações e o cluster do Amazon EKS. Levará alguns minutos para que as métricas sejam exibidas, pois elas estão sendo coletadas.
Lista de métricas monitoradas
Essa solução coleta métricas do seu aplicativo JVM-based Kafka. Essas métricas são armazenadas no Amazon Managed Service for Prometheus e exibidas nos dashboards do Amazon Managed Grafana.
As métricas a seguir são monitoradas com essa solução.
jvm.classes.loaded
jvm.gc.collections.count
jvm.gc.collections.elapsed
jvm.memory.heap.init
jvm.memory.heap.max
jvm.memory.heap.used
jvm.memory.heap.committed
jvm.memory.nonheap.init
jvm.memory.nonheap.max
jvm.memory.nonheap.used
jvm.memory.nonheap.committed
jvm.memory.pool.init
jvm.memory.pool.max
jvm.memory.pool.used
jvm.memory.pool.committed
jvm.threads.count
kafka.message.count
kafka.request.count
kafka.request.failed
kafka.request.time.total
kafka.request.time.50p
kafka.request.time.99p
kafka.request.time.avg
kafka.network.io
kafka.purgatory.size
kafka.partition.count
kafka.partition.offline
kafka.partition.under_replicated
kafka.isr.operation.count
kafka.max.lag
kafka.controller.active.count
kafka.leader.election.rate
kafka.unclean.election.rate
kafka.request.queue
kafka.logs.flush.time.count
kafka.logs.flush.time.median
kafka.logs.flush.time.99p
kafka.consumer.fetch-rate
kafka.consumer.records-lag-max
kafka.consumer.total.bytes-consumed-rate
kafka.consumer.total.fetch-size-avg
kafka.consumer.total.records-consumed-rate
kafka.consumer.bytes-consumed-rate
kafka.consumer.fetch-size-avg
kafka.consumer.records-consumed-rate
kafka.producer.io-wait-time-ns-avg
kafka.producer.outgoing-byte-rate
kafka.producer.request-latency-avg
kafka.producer.request-rate
kafka.producer.response-rate
kafka.producer.byte-rate
kafka.producer.compression-rate
kafka.producer.record-error-rate
kafka.producer.record-retry-rate
kafka.producer.record-send-rate
Solução de problemas
Há algumas coisas que podem fazer com que a configuração do projeto falhe. Certifique-se de verificar o seguinte:
-
Você deve concluir todos os pré-requisitos antes de instalar a solução.
-
O cluster deve ter pelo menos um nó antes de tentar criar a solução ou acessar as métricas.
-
O cluster do Amazon EKS deve ter os complementos
AWS CNI,CoreDNSekube-proxyinstalados. Se eles não estiverem instalados, a solução não funcionará corretamente. Eles são instalados por padrão ao criar o cluster por meio do console. Talvez seja necessário instalá-los se o cluster tiver sido criado por meio de um AWS SDK. -
O tempo limite de instalação dos pods do Amazon EKS expirou. Isso poderá acontecer se não houver capacidade suficiente de nós disponível. Há várias causas para esses problemas, incluindo:
-
O cluster do Amazon EKS foi inicializado com o Fargate em vez do Amazon EC2. Esse projeto requer o Amazon EC2.
-
Os nós estão corrompidos e, portanto, indisponíveis.
Você pode usar
kubectl describe nodepara verificar os taints. Em seguida,NODENAME| grep Taintskubectl taint nodepara remover os taints. Certifique-se de incluirNODENAMETAINT_NAME--após o nome do taint. -
Os nós atingiram o limite de capacidade. Nesse caso, você pode criar um novo nó ou aumentar a capacidade.
-
-
Você não vê nenhum dashboard no Grafana: você está usando o ID incorreto do espaço de trabalho do Grafana.
Execute o seguinte comando para obter informações sobre o Grafana:
kubectl describe grafanas external-grafana -n grafana-operatorVocê pode verificar os resultados do URL correto do espaço de trabalho. Se não for o que você espera, implante novamente com o ID do espaço de trabalho correto.
Spec: External: API Key: Key: GF_SECURITY_ADMIN_APIKEY Name: grafana-admin-credentials URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Status: Admin URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Dashboards: ... -
Você não vê nenhum dashboard no Grafana: você está usando uma chave de API expirada.
Para procurar esse caso, você precisará obter o operador do Grafana e verificar se há erros nos logs. Obtenha o nome do operador do Grafana com este comando:
kubectl get pods -n grafana-operatorIsso retornará o nome do operador, por exemplo:
NAME READY STATUS RESTARTS AGEgrafana-operator-1234abcd5678ef901/1 Running 0 1h2mUse o nome do operador no seguinte comando:
kubectl logsgrafana-operator-1234abcd5678ef90-n grafana-operatorMensagens de erro como as seguintes indicam uma chave de API expirada:
ERROR error reconciling datasource {"controller": "grafanadatasource", "controllerGroup": "grafana.integreatly.org", "controllerKind": "GrafanaDatasource", "GrafanaDatasource": {"name":"grafanadatasource-sample-amp","namespace":"grafana-operator"}, "namespace": "grafana-operator", "name": "grafanadatasource-sample-amp", "reconcileID": "72cfd60c-a255-44a1-bfbd-88b0cbc4f90c", "datasource": "grafanadatasource-sample-amp", "grafana": "external-grafana", "error": "status: 401, body: {\"message\":\"Expired API key\"}\n"} github.com/grafana-operator/grafana-operator/controllers.(*GrafanaDatasourceReconciler).ReconcileNesse caso, crie uma chave de API e implante a solução novamente. Se o problema persistir, você pode forçar a sincronização usando o seguinte comando antes da nova implantação:
kubectl delete externalsecret/external-secrets-sm -n grafana-operator -
Falta o parâmetro SSM. Se você encontrar um erro como a seguir, execute
cdk bootstrape tente novamente.Deployment failed: Error: aws-observability-solution-kafka-eks-$EKS_CLUSTER_NAME: SSM parameter /cdk-bootstrap/xxxxxxx/version not found. Has the environment been bootstrapped? Please run 'cdk bootstrap' (see https://docs.aws.amazon.com/cdk/latest/ guide/bootstrapping.html)
