Configuração de um destino para um integração ETL zero
Há várias opções oferecidas pela AWS Glue para configurar um destino para uma integração ETL zero. O destino pode ser um data warehouse criptografado do Amazon Redshift ou uma arquitetura Lakehouse do Amazon SageMaker.
Antes de selecionar o destino para a integração ETL zero, você precisa configurar um dos seguintes recursos de destino. As opções de configuração para um destino em uma integração ETL zero incluem:
Um bucket do Amazon S3 de uso geral usando a arquitetura Lakehouse do Amazon SageMaker. Consulte Configuração de um destino de bucket de uso geral do S3.
Um bucket das Tabelas do Amazon S3 usando a arquitetura Lakehouse do Amazon SageMaker. Consulte Configuração de um destino de bucket das Tabelas do Amazon S3.
Um armazenamento gerenciado do Amazon Redshift usando a arquitetura Lakehouse do Amazon SageMaker. Consulte Configuração de um destino de armazenamento gerenciado do Amazon Redshift.
Um data warehouse do Amazon Redshift identificado por um namespace do Redshift. Consulte Configurar um destino de data warehouse do Amazon Redshift.
nota
Não é possível modificar o destino de uma integração ETL zero após a criação.
Configuração de um destino de bucket de uso geral do S3
Esta seção descreve os pré-requisitos e as etapas de configuração para definir um bucket de uso geral do S3 como armazenamento para seu destino em uma integração ETL zero usando a arquitetura Lakehouse do Amazon SageMaker.
Antes de criar uma integração ETL zero com a arquitetura Lakehouse do Amazon SageMaker usando o armazenamento de uso geral do S3, você precisa concluir as seguintes tarefas de configuração:
Configurar um banco de dados do AWS Glue
Fornecer uma política RBAC do Catálogo
Criar um perfil do IAM de destino
Associe o perfil de destino, o KMS (opcional) e a conexão (opcional) ao recurso de destino
(Opcional) Configure as propriedades da tabela de destino
Configurar um banco de dados do AWS Glue
Para configurar um banco de dados de destino no Catálogo de Dados com uma localização do bucket de uso geral do Amazon S3:
Na página inicial do console do AWS Glue, selecione Banco de dados em Catálogo de Dados.
Escolha Adicionar dados no canto superior direito. Se você já criou um banco de dados, certifique-se de que o local com o URI do Amazon S3 esteja definido para o banco de dados.
Insira um nome e um Local (URI do Amazon S3). Observe que o local é necessário para a integração ETL zero. Clique em Criar banco de dados quando terminar.
nota
O bucket de uso geral do Amazon S3 deve estar na mesma região que o banco de dados do AWS Glue.
Para obter informações sobre como criar um novo banco de dados no AWS Glue, consulte Conceitos básicos do Catálogo de Dados.
Você também pode usar a CLI create-database para criar o banco de dados no AWS Glue. Observe que o LocationUri em --database-input é obrigatório.
Otimizar tabelas Iceberg
Depois que uma tabela é criada pelo AWS Glue no banco de dados de destino, é possível habilitar a compactação para acelerar as consultas no Amazon Athena. Para obter informações sobre como configurar os recursos (perfil do IAM) para compactação, consulte Pré-requisitos da otimização de tabelas.
Para obter mais informações sobre como configurar a compactação na tabela do AWS Glue criada pela integração, consulte Otimizar tabelas do Iceberg.
Fornecer uma política de acesso baseado em recursos (RBAC) do catálogo
Para integrações que usam um banco de dados do AWS Glue, adicione as seguintes permissões à política RBAC do catálogo para permitir integrações entre a origem e o destino.
nota
Para integrações entre contas, tanto o usuário que cria a política de perfil de integração quanto a política de recurso do catálogo precisam permitir glue:CreateInboundIntegration no recurso. Para a mesma conta, uma política de recursos ou uma política de perfil que permita glue:CreateInboundIntegration no recurso é suficiente. Ambos os cenários ainda precisam permitir glue.amazonaws.com em glue:AuthorizeInboundIntegration.
Você pode acessar as Configurações do catálogo em Catálogo de Dados. Em seguida, forneça as permissões a seguir e preencha as informações que faltam.
{ "Version": "2012-10-17", "Statement": [ { "Principal": { "AWS": [ "arn:aws:iam::123456789012:user/Alice" ] }, "Effect": "Allow", "Action": [ "glue:CreateInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name" ], "Condition": { "StringLike": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } }, { "Principal": { "Service": [ "glue.amazonaws.com" ] }, "Effect": "Allow", "Action": [ "glue:AuthorizeInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name" ], "Condition": { "StringEquals": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } } ] }
Criar um perfil do IAM de destino
Crie um perfil do IAM de destino com as permissões e relação de confiança a seguir.
{ "Version": "2012-10-17", "Statement": [ { "Action": "s3:ListBucket", "Resource": "arn:aws:s3:::amzn-s3-bucket", "Effect": "Allow" }, { "Action": [ "s3:GetObject", "s3:PutObject", "s3:DeleteObject" ], "Resource": "arn:aws:s3:::amzn-s3-demo-bucket/prefix/*", "Effect": "Allow" }, { "Action": [ "glue:GetDatabase" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name" ], "Effect": "Allow" }, { "Action": [ "glue:CreateTable", "glue:GetTable", "glue:GetTables", "glue:DeleteTable", "glue:UpdateTable", "glue:GetTableVersion", "glue:GetTableVersions", "glue:GetResourcePolicy" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name", "arn:aws:glue:us-east-1:111122223333:table/database-name/*" ], "Effect": "Allow" }, { "Action": [ "cloudwatch:PutMetricData" ], "Resource": "*", "Condition": { "StringEquals": { "cloudwatch:namespace": "AWS/Glue/ZeroETL" } }, "Effect": "Allow" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*", "Effect": "Allow" } ] }
Adicione seguinte a política de confiança para permitir que o serviço AWS Glue assuma o perfil:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
Associe o perfil de destino, o KMS (opcional) e a conexão (opcional) ao recurso de destino
Associe o perfil de destino acima ao recurso de destino, ou seja, o banco de dados do AWS Glue. Opcionalmente, o KMS para criptografar os dados antes de serem armazenados na tabela Iceberg de destino e o ARN da conexão para acessar o bucket do S3 podem ser configurados para o banco de dados de destino do AWS Glue. Isso permitirá que o AWS Glue acesse dados no local de destino do S3 usando o perfil fornecido e, opcionalmente, criptografar usando a chave do KMS fornecida. Se o bucket do S3 de destino estiver configurado para ser acessível usando uma determinada VPC, o ARN da conexão poderá ser associado para permitir que o AWS Glue execute o processamento dentro dessa VPC. Para obter mais informações sobre como configurar uma VPC, consulte Criar uma VPC.
Ou usando a API ou a CLI do AWS Glue:
aws glue create-integration-resource-property \ --resource-arn arn:aws:glue:us-east-1:123456789012:database/database-name\ --target-processing-properties '{"RoleArn": "arn:aws:iam::123456789012:role/gmi_target_role"}' \ --region us-east-1
(Opcional) Configure as propriedades da tabela de destino
Opcionalmente, as propriedades da tabela de destino podem ser configuradas para as tabelas de destino que serão sincronizadas com o destino.
Você pode definir essas configurações na seção Configurações de saída do fluxo de trabalho de criação da integração no console do AWS Glue:

Ao selecionar Especificar chaves de partição personalizadas, você pode configurar as chaves de partição e suas especificações de função e conversão:

Se a origem e o destino estiverem na mesma conta, essa configuração poderá ser feita como parte do fluxo de trabalho de criação da integração na interface do usuário do console do AWS Glue. Mas se o destino estiver em outra conta, essa configuração deverá ser concluída antes da criação da integração. Ao usar a CLI ou a API, isso deverá ser feito antes de invocar a API Create-Integration, mesmo quando a origem e o destino estiverem na mesma conta. A interface de usuário do console do AWS Glue apenas encapsula essa chamada de API para o mesmo cenário de conta.
Se isso não estiver configurado, os valores padrão serão usados ao sincronizar a tabela. Essa configuração também poderá ser alterada a qualquer momento após a criação da integração.
nota
Se essa propriedade for atualizada após a criação da integração, ela poderá acionar uma ressincronização completa da tabela quando a configuração atualizada entrar em conflito com a configuração existente. Por exemplo, atualizar a tabela “un-nesting” de “No-Unnest” para “Full-Unnest” ou alterar a coluna de partição.
Usando a CLI ou a API:
aws glue create-integration-table-properties \ --resource-arn arn:aws:glue:us-east-1:123456789012:database/database-name\ --table-nametable-name\ --target-table-config '{ "UnnestSpec":"TOPLEVEL"|"FULL"|"NOUNNEST", "PartitionSpec": [ { "FieldName":"string", "FunctionSpec":"string", "ConversionSpec":"string"} ... ], "TargetTableName":"string" }' \ --region us-east-1
Depois de configurar a arquitetura Lakehouse do Amazon SageMaker com um armazenamento de buckets de uso geral do Amazon S3, você pode prosseguir com Configurar a integração com seu destino para concluir a configuração da integração.
Configuração de um destino de bucket das Tabelas do Amazon S3
Esta seção descreve os pré-requisitos e as etapas de configuração para configurar as Tabelas do Amazon S3 como um destino para sua integração ETL zero usando a arquitetura Lakehouse do Amazon SageMaker.
Antes de criar uma integração ETL zero com as Tabelas do Amazon S3 como destino, você precisa concluir as seguintes tarefas de configuração:
Configurar o bucket das Tabelas do Amazon S3 (e a integração dos serviços de analytics)
Fornecer uma política RBAC do Catálogo
Criar um perfil do IAM de destino
Associe o perfil de destino, o KMS (opcional) e a conexão (opcional) ao recurso de destino
(Opcional) Configure as propriedades da tabela de destino
Configurar o bucket das Tabelas do Amazon S3 (com a integração dos serviços de analytics)
Crie um bucket de tabelas do S3 em sua conta seguindo as instruções em Introdução às Tabelas do Amazon S3.
Habilite as integrações do Analytics com seu bucket das Tabelas do S3 seguindo estas instruções: Integração de serviços da AWS com as Tabelas do Amazon S3.
Isso criará um novo catálogo das Tabelas do S3 no AWS Lake Formation.
Fornecer uma política RBAC do Catálogo
As seguintes permissões devem ser adicionadas à política RBAC do Catálogo para permitir integrações entre o destino do catálogo de origem e das Tabelas do Amazon S3.
A política de recursos do Catálogo do AWS Glue de destino precisa incluir as permissões do serviço do AWS Glue para AuthorizeInboundIntegration. Além disso, a permissão CreateInboundIntegration é necessária na entidade principal da origem que cria a integração ou no destino da política de recursos do AWS Glue.
nota
Para um cenário entre contas, tanto a política de recursos do Catálogo do AWS Glue de destino quanto da entidade principal de origem precisam incluir as permissões glue:CreateInboundIntegration no recurso.
{ "Version": "2012-10-17", "Statement": [ { "Principal": { "AWS": [ "arn:aws:iam::123456789012:user/Alice" ] }, "Effect": "Allow", "Action": [ "glue:CreateInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog/s3tablescatalog/*" ], "Condition": { "StringLike": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } }, { "Principal": { "Service": [ "glue.amazonaws.com" ] }, "Effect": "Allow", "Action": [ "glue:AuthorizeInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog/s3tablescatalog/*" ], "Condition": { "StringEquals": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } } ] }
nota
Substitua s3tablescatalogs3tablescatalog.
Criar um perfil do IAM de destino
Crie um perfil do IAM de destino com as permissões e relação de confiança a seguir.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3tables:ListTableBuckets", "s3tables:GetTableBucket", "s3tables:GetTableBucketEncryption", "s3tables:GetNamespace", "s3tables:CreateNamespace", "s3tables:ListNamespaces", "s3tables:CreateTable", "s3tables:DeleteTable", "s3tables:GetTable", "s3tables:GetTableEncryption", "s3tables:ListTables", "s3tables:GetTableMetadataLocation", "s3tables:UpdateTableMetadataLocation", "s3tables:GetTableData", "s3tables:PutTableData" ], "Resource": "arn:aws:s3tables:us-east-1:111122223333:bucket/s3-table-bucket", "Effect": "Allow" }, { "Action": [ "cloudwatch:PutMetricData" ], "Resource": "*", "Condition": { "StringEquals": { "cloudwatch:namespace": "AWS/Glue/ZeroETL" } }, "Effect": "Allow" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*", "Effect": "Allow" } ] }
Adicione a seguinte política de confiança no perfil do IAM de destino para permitir que o serviço do AWS Glue assuma:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
nota
Certifique-se de que não haja uma declaração DENY explícita para esse perfil do IAM de destino na política de recursos do bucket das Tabelas do S3. Uma declaração DENY explícita substituiria todas as permissões ALLOW e impediria que a integração funcionasse corretamente.
Associe o perfil de destino, o KMS (opcional) e a conexão (opcional) ao recurso de destino
Associe o perfil de destino acima ao recurso de destino. Opcionalmente, o KMS para criptografar os dados antes de serem armazenados na tabela Iceberg de destino e o ARN da conexão para acessar o bucket de destino do S3 podem ser configurados. Se o bucket do S3 de destino estiver configurado para ser acessível usando uma determinada VPC, o ARN da conexão poderá ser associado para permitir que o AWS Glue execute o processamento dentro dessa VPC. Para obter mais informações sobre como configurar uma VPC, consulte Criar uma VPC.
Usando a API ou a CLI do AWS Glue:
aws glue create-integration-resource-property \ --resource-arn arn:aws:glue:us-east-1:123456789012:catalog/s3tablescatalog/S3 table bucket name\ --target-processing-properties '{ "RoleArn": "arn:aws:iam::123456789012:role/target_role" }' \ --region us-east-1
(Opcional) Configure as propriedades da tabela de destino
Opcionalmente, as propriedades da tabela de destino podem ser configuradas para as tabelas de destino que serão sincronizadas com o destino. As mesmas regras se aplicam, conforme descrito na seção de destino de uso geral do S3.
Usando a CLI ou a API:
aws glue create-integration-table-properties \ --resource-arn arn:aws:glue:us-east-1:123456789012:catalog/s3tablescatalog/S3 table bucket name\ --table-nametable-name\ --target-table-config '' \ --region us-east-1
Depois de configurar o armazenamento das Tabelas do Amazon S3 usando a arquitetura Lakehouse do Amazon SageMaker, você pode prosseguir com Configurar a integração com seu destino para concluir a configuração da integração.
Configuração de um destino de armazenamento gerenciado do Amazon Redshift
Esta seção descreve os pré-requisitos e as etapas de configuração para configurar um armazenamento gerenciado (RMS) do Amazon Redshift como destino para sua integração ETL zero usando a arquitetura Lakehouse do Amazon SageMaker.
Antes de criar uma integração ETL zero com uma arquitetura Lakehouse do Amazon SageMaker usando o armazenamento gerenciado do Redshift, você precisa concluir as seguintes tarefas de configuração:
Configurar um cluster do Amazon Redshift ou grupo de trabalho do Serverless
Registrar a integração do Amazon Redshift com o Lake Formation
Criar um catálogo gerenciado no Lake Formation
Configurar permissões do IAM
Configurar o armazenamento gerenciado do Amazon Redshift
Para configurar um armazenamento gerenciado do Amazon Redshift para sua integração ETL zero:
Crie ou use um cluster existente do Amazon Redshift ou um grupo de trabalho sem servidor. Confirme se o grupo de trabalho ou cluster de destino do Amazon Redshift tem o parâmetro
enable_case_sensitive_identifierativado para que a integração tenha êxito. Para obter mais informações sobre como habilitar a diferenciação de maiúsculas e minúsculas, consulte Ativar a diferenciação entre letras maiúsculas e minúsculas no data warehouse no Guia de gerenciamento do Amazon Redshift.Registre uma integração do Redshift no catálogo no AWS Lake Formation. Consulte Registrar clusters e namespaces do Amazon Redshift no Catálogo de dados.
Crie um catálogo federado ou gerenciado no AWS Lake Formation. Para obter mais informações, consulte:
Configurar permissões do IAM para o perfil de destino. O perfil precisa de permissões para acessar os recursos do Redshift e do Lake Formation. No mínimo, o perfil deve ter:
Permissões para acessar o cluster ou grupo de trabalho do Redshift
Permissões para acessar o catálogo do Lake Formation
Permissões para criar e gerenciar tabelas no catálogo
Permissões do CloudWatch e do CloudWatch Logs para monitoramento
Depois de configurar o catálogo do Amazon SageMaker Lakehouse com o armazenamento gerenciado do Amazon Redshift, você pode prosseguir para Configurar a integração com seu destino para concluir a configuração da integração.
Configurar um destino de data warehouse do Amazon Redshift
Esta seção descreve os pré-requisitos e as etapas de configuração para configurar o data warehouse do Amazon Redshift como um destino para sua integração ETL zero.
Antes de criar uma integração ETL zero com um destino de data warehouse do Amazon Redshift, você precisa concluir as seguintes tarefas de configuração:
Configurar um cluster do Amazon Redshift ou grupo de trabalho do Serverless
Configurar a diferenciação de maiúsculas e minúsculas
Configurar permissões do IAM
Configurar o data warehouse do Amazon Redshift
Para configurar um data warehouse do Amazon Redshift para sua integração ETL zero:
Navegue até o console do Amazon Redshift
e clique em Criar cluster ou use um cluster existente. Para criar um cluster do Amazon Redshift, consulte Criar um cluster. No Amazon Redshift sem servidor, clique em Criar grupo de trabalho. Para criar um grupo de trabalho do Amazon Redshift sem servidor, consulte Criar um grupo de trabalho com um namespace. Ao criar um novo cluster, escolha um tamanho de cluster apropriado e garanta que seu cluster esteja criptografado. Para o Serverless, defina as configurações do grupo de trabalho de acordo com seus requisitos.
Confirme se o grupo de trabalho ou cluster de destino do Amazon Redshift tem o parâmetro
enable_case_sensitive_identifierativado para que a integração tenha êxito. Para obter mais informações sobre como habilitar a diferenciação de maiúsculas e minúsculas, consulte Ativar diferenciação de maiúsculas e minúsculas para seu data warehouse no guia de gerenciamento do Amazon Redshift.Configure as permissões do IAM para permitir que a integração ETL zero acesse seu data warehouse do Amazon Redshift. Você precisará criar um perfil do IAM com as permissões a seguir:
Permissões para acessar o cluster ou grupo de trabalho do Amazon Redshift
Permissões para criar e gerenciar bancos de dados e tabelas no Amazon Redshift
Permissões do CloudWatch e do CloudWatch Logs para monitoramento
Depois que a configuração do grupo de trabalho ou cluster do Amazon Redshift estiver concluída, você precisará configurar o data warehouse ou as integrações ETL zero. Consulte Introdução a integrações ETL zero no Guia de gerenciamento do Amazon Redshift para obter mais informações.
nota
Ao usar um data warehouse do Amazon Redshift como destino, a integração cria um esquema no banco de dados especificado para armazenar os dados replicados. O nome do esquema é derivado do nome da integração.
nota
O grupo de trabalho ou cluster de destino do Amazon Redshift deve ter o parâmetro enable_case_sensitive_identifier ativado para que a integração seja bem-sucedida.
Depois de configurar o data warehouse do Amazon Redshift, você pode prosseguir para Configurar a integração com seu destino para concluir a configuração da integração.
Configurar a integração com seu destino
Depois de configurar os recursos de origem e destino, siga estas etapas para concluir a configuração da integração:
Navegue até a página “Integrações ETL zero” e inicie o fluxo de trabalho de criação da integração.
Selecione o recurso de origem configurado nas etapas anteriores.
Selecione ou especifique o recurso de destino (mesma conta ou conta cruzada) configurado nas etapas anteriores.
Selecione o perfil de destino do IAM configurado anteriormente.
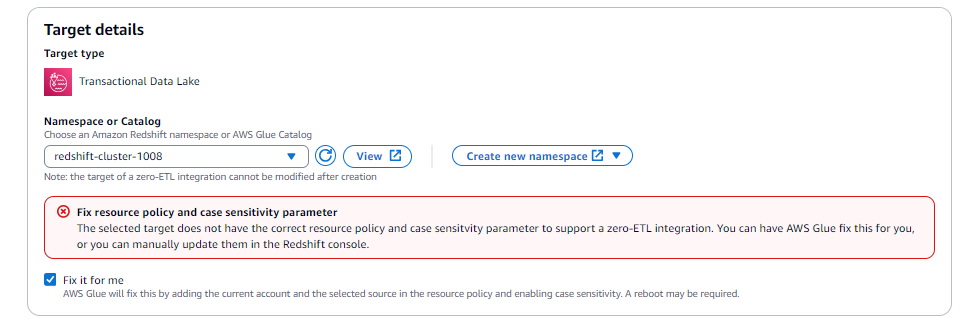
Selecione a opção Corrigir para mim (disponível somente quando o destino está na mesma conta).
Para o destino normal do Amazon S3 (banco de dados do AWS Glue) e das Tabelas do S3 (catálogo), isso será:
Aplique uma entidade principal de serviço autorizada na política de recursos do Catálogo de destino.
Aplique um ARN da entidade principal de origem autorizada do AWS Glue à política de recursos do catálogo de destino.
Para o Amazon Redshift de destino, isso fará:
Aplicar uma entidade principal autorizada no cluster Amazon Redshift ou grupo de trabalho do Serverless.
Aplicar um ARN de origem autorizado do AWS Glue ao cluster do Amazon Redshift ou ao grupo de trabalho do Serverless.
Associar um novo grupo de parâmetros a
enable_case_sensitive_identifier = true.
Use o seguinte para criar a integração via API ou CLI: API CreateIntegration.
