Habilitar o otimizador de compactação
Você pode usar o console do AWS Glue, a AWS CLI, ou a API da AWS para habilitar a compactação de tabelas Apache Iceberg no Catálogo de Dados do AWS Glue. Para novas tabelas, você pode escolher o Apache Iceberg como formato de tabela e ativar a compactação ao criar a tabela. A compactação está desabilitada por padrão para novas tabelas.
- Console
-
Para habilitar compactação
-
Abra o console do AWS Glue em https://console.aws.amazon.com/glue/ e faça login como administrador do data lake, criador da tabela ou um usuário que tenha recebido as permissões glue:UpdateTable e lakeformation:GetDataAccess na tabela.
-
No painel de navegação, em Catálogo de dados, escolha Tabelas.
Na página Tabelas, escolha uma tabela em formato de tabela aberta para a qual você deseja habilitar a compactação e, em seguida, no menu Ações, escolha Optimização e Habilitar.
Você também pode habilitar a compactação selecionando a tabela Otimização de tabela e abrindo a página Detalhes da tabela. Escolha a guia Otimização de tabela na seção inferior da página e escolha Ativar compactação.
A opção Ativar otimização também está disponível ao criar uma nova tabela Iceberg no Catálogo de Dados.
-
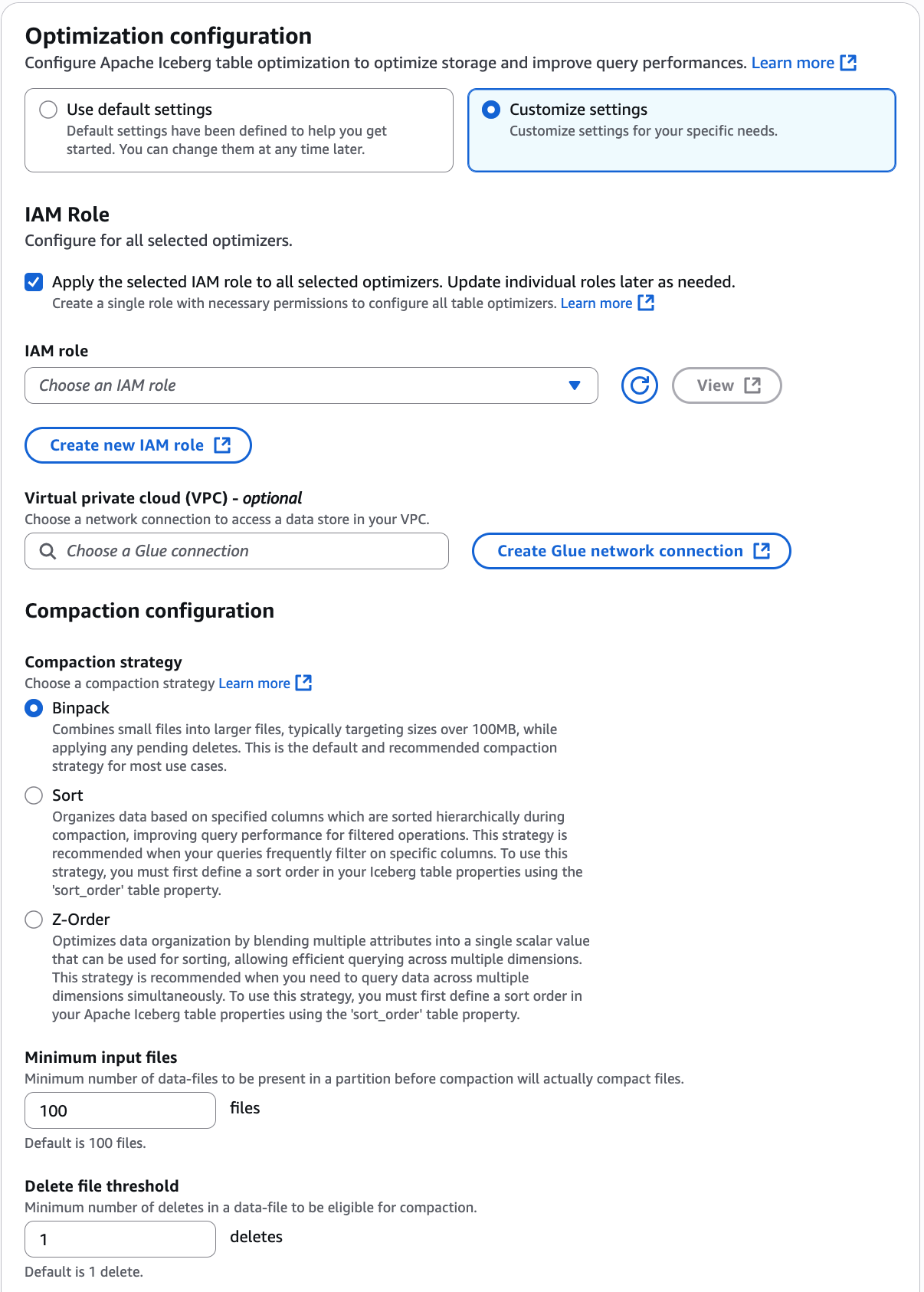
Na página Habilitar otimização, escolha Compactação em Opções de otimização.
-
Em seguida, selecione um perfil do IAM na lista suspensa com as permissões mostradas na seção Pré-requisitos de otimização de tabelas.
Você também pode escolher a opção Criar um novo perfil do IAM para criar um perfil personalizado com as permissões necessárias para executar a compactação.
Siga as etapas abaixo para atualizar um perfil do IAM existente:
-
Para atualizar a política de permissões para o perfil do IAM, no console do IAM, acesse a função do IAM que está sendo usada para executar a compactação.
-
Na seção Adicionar permissões, escolha Criar política. Na janela recém-aberta do navegador, crie uma nova política para usar com sua função.
-
Na página Criar política, escolha a guia JSON. Copie o código JSON mostrado nos Pré-requisitos no campo do editor de políticas.
-
Se você tiver configurações de política de segurança em que o otimizador de tabelas do Iceberg precise acessar buckets do Amazon S3 de uma Nuvem Privada Virtual (VPC) específica, crie uma conexão de rede do AWS Glue ou use uma existente.
Se você ainda não tiver uma conexão VPC do AWS Glue configurada, crie uma seguindo as etapas na seção Creating connections for connectors usando o console do AWS Glue ou a AWS CLI/o SDK.
-
Escolha uma estratégia de compactação. As opções disponíveis são:
Binpack: binpack é a estratégia de compactação padrão no Apache Iceberg. Ela combina arquivos de dados menores em arquivos maiores para um desempenho ideal.
-
Sort: a classificação no Apache Iceberg é uma técnica de organização de dados que agrupa em cluster informações em arquivos com base em colunas especificadas, melhorando significativamente o desempenho da consulta ao reduzir o número de arquivos que precisam ser processados. Você define a ordem de classificação nos metadados do Iceberg usando o campo sort-order e, quando houver a especificação de várias colunas, os dados são classificados na sequência em que as colunas aparecem na ordem de classificação, garantindo que registros com valores semelhantes sejam armazenados juntos nos arquivos. A estratégia de compactação de classificação promove ainda mais otimização ao classificar os dados em todos os arquivos dentro de uma partição.
Z-order: a ordenação Z é uma forma de organizar dados quando você precisa classificar por várias colunas com importância igual. Diferentemente da classificação tradicional que prioriza uma coluna em detrimento de outras, a ordenação Z dá um peso equilibrado a cada coluna, ajudando seu mecanismo de consulta a ler menos arquivos ao pesquisar dados.
A técnica funciona entrelaçando os dígitos binários dos valores de diferentes colunas. Por exemplo, se você tiver os números 3 e 4 de duas colunas, primeiro a ordenação Z os converte em binário (3 vira 011 e 4 vira 100) e, em seguida, intercala esses dígitos para criar um novo valor: 011010. Essa intercalação cria um padrão que mantém os dados relacionados fisicamente próximos uns dos outros.
A ordenação Z é particularmente eficaz para consultas multidimensionais. Por exemplo, uma tabela de clientes com ordenação em Z por renda, estado e código postal pode oferecer desempenho superior em comparação à classificação hierárquica ao fazer consultas em várias dimensões. Essa organização permite que consultas direcionadas a combinações específicas de renda e localização geográfica localizem rapidamente dados relevantes e, ao mesmo tempo, minimizem varreduras desnecessárias de arquivos.
-
Arquivos de entrada mínimos: o número de arquivos de dados necessários em uma partição antes que a compactação seja acionada.
-
Limite de exclusão de arquivos: operações mínimas de exclusão necessárias em um arquivo de dados antes que ele se torne elegível para compactação.
-
Escolha Habilitar otimização.
- AWS CLI
-
O exemplo a seguir mostra como habilitar a compactação. Substitua o ID da conta por um ID de conta da AWS válido. Substitua o nome do banco de dados e o nome da tabela pelo nome real da tabela do Iceberg e pelo nome do banco de dados. Substitua o roleArn pelo nome do recurso (ARN) AWS do perfil do IAM e o nome do perfil do IAM que tem as permissões necessárias para executar a compactação. Você pode substituir a estratégia de compactação sort por outras estratégias compatíveis, como z-order ou binpack.
order” dependendo dos seus requisitos.
aws glue create-table-optimizer \
--catalog-id 123456789012 \
--database-name iceberg_db \
--table-name iceberg_table \
--table-optimizer-configuration '{
"roleArn": "arn:aws:iam::123456789012:role/optimizer_role",
"enabled": true,
"vpcConfiguration": {"glueConnectionName": "glue_connection_name"},
"compactionConfiguration": {
"icebergConfiguration": {"strategy": "sort"}
}
}'\
--type compaction
- AWS API
-
Chame a operação CreateTableOptimizer para ativar a compactação de uma tabela.
Após habilitar a compactação, a guia Otimização da tabela mostrará os seguintes detalhes da compactação após a conclusão da execução da compactação:
- Hora de início
-
A hora em que o processo de compactação iniciou no Catálogo de Dados. O valor é um timestamp no horário UTC.
- End Time
-
A hora em que o processo de compactação terminou no catálogo de dados. O valor é um timestamp no horário UTC.
- Status
-
O status de execução da compactação. Os valores são sucesso ou falha.
- Arquivos compactados
Número total de arquivos compactados.
- Bytes compactados
-
Número total de bytes compactados.