Conceitos do AWS Glue
O AWS Glue é um serviço ETL (Extrair, transformar, carregar) totalmente gerenciado que permite mover dados com facilidade entre diferentes fontes de dados e destinos. Os principais componentes são:
-
Catálogo de dados: um armazenamento de metadados que contém definições de tabelas, definições de tarefas e outras informações de controle para seus fluxos de trabalho de ETL.
-
Crawlers: programas que se conectam a fontes de dados, inferem esquemas de dados e criam definições de tabelas de metadados no Catálogo de Dados.
-
Trabalhos de ETL: a lógica de negócios para extrair dados de fontes, transformá-los usando scripts do Apache Spark e carregá-los em destinos.
-
Acionadores: mecanismos para iniciar a execução de trabalhos com base em agendas ou eventos.
O fluxo de trabalho típico envolve:
-
Definir fontes e destinos de dados no Data Catalog.
-
Usar crawlers para preencher o catálogo de dados com metadados de tabela de fontes de dados.
-
Definir tarefas de ETL com scripts de transformação para mover e processar dados.
-
Executar trabalhos sob demanda ou com base em acionadores.
-
Monitorar o desempenho de trabalhos usando painéis.
O diagrama a seguir mostra a arquitetura de um ambiente do AWS Glue.
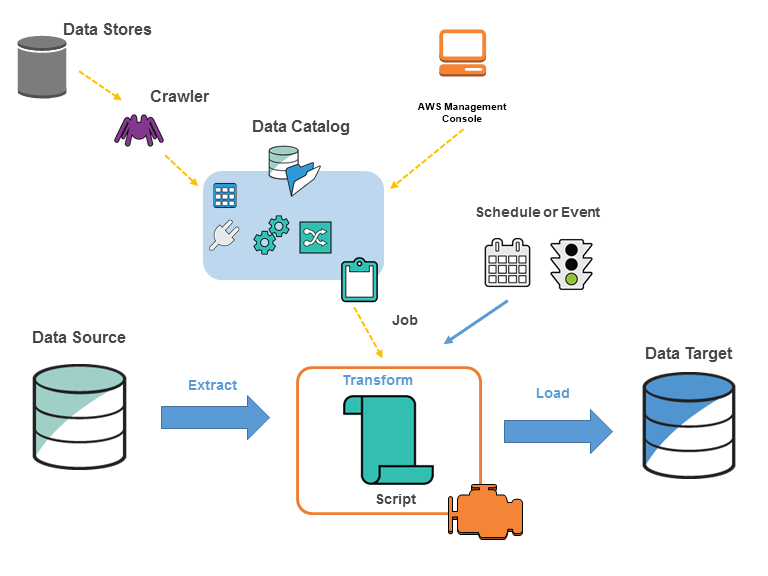
Você define os trabalhos no AWS Glue para atender aos requisitos de extração, transformação e carregamento (ETL) de dados de uma fonte de dados para um destino de dados. Você pode realizar as seguintes ações:
-
Para fontes de armazenamento de dados, defina um crawler para preencher seu AWS Glue Data Catalog com definições da tabela de metadados. Você aponta seu crawler para um armazenamento de dados e ele cria definições de tabela no Data Catalog. Para fontes de transmissão, defina manualmente as tabelas do Data Catalog e especifique as propriedades de fluxo de dados.
Além das definições de tabela, o AWS Glue Data Catalog contém outros metadados necessários para definir trabalhos de ETL. Usar esses metadados ao definir um trabalho de transformação dos seus dados.
O AWS Glue pode gerar um script para transformar seus dados. Se preferir, você pode fornecer o script no console ou na API do AWS Glue.
-
É possível executar trabalhos sob demanda ou configurá-los para iniciar quando um determinado gatilho for acionado. Os gatilhos podem ser programações ou eventos baseados em tempo.
Quando seu trabalho é executado, um script extrai os dados da sua fonte de dados, transforma esses dados e os carrega no seu destino de dados. O script é executado em um ambiente do Apache Spark no AWS Glue.
Importante
As tabelas e os bancos de dados contidos no AWS Glue são objetos no AWS Glue Data Catalog. Eles contêm metadados;, e não dados de um armazenamento físico.
|
Dados baseados em texto, como CSVs, devem ser codificados em |
Terminologia do AWS Glue
O AWS Glue depende da interação de vários componentes para criar e gerenciar o fluxo de trabalho de extração, transformação e carregamento (ETL).
AWS Glue Data Catalog
O armazenamento persistente de metadados no AWS Glue. Ele contém definições de tabela, definições de trabalho e outras informações de controle para o gerenciamento do ambiente do AWS Glue. Cada conta da AWS tem um AWS Glue Data Catalog por região.
Classificador
Determina o esquema dos seus dados. O AWS Glue fornece classificadores para tipos de arquivo comuns, como CSV, JSON, XML, AVRO e outros. Ele também fornece classificadores para sistemas comuns de gerenciamento do banco de dados relacional usando uma conexão JDBC. Você pode escrever seu próprio classificador usando um padrão grok ou especificando uma linha de tag em um documento XML.
Conexão
Um objeto do Data Catalog que contém as propriedades necessárias para se conectar a um armazenamento de dados específico.
Crawler
Um programa que se conecta a um armazenamento de dados (origem ou destino), passa por uma lista prioritária de classificadores para determinar o esquema dos dados e cria tabelas de metadados no AWS Glue Data Catalog.
Banco de dados
Um conjunto de definições da tabela associada do Data Catalog organizadas em um grupo lógico.
Datastore, fonte de dados, destino de dados
Um datastore é um repositório para armazenar seus dados persistentemente. Os exemplos incluem buckets do Amazon S3 e bancos de dados relacionais. Uma fonte de dados é um datastore que é usado como entrada para um processo ou transformação. Um destino de dados é um datastore no qual um processo ou transformação grava.
Endpoint de desenvolvimento
Um ambiente que pode ser usado para desenvolver e testar seus scripts de ETL do AWS Glue.
Quadro dinâmico
Uma tabela distribuída que oferece suporte a dados aninhados, como estruturas e matrizes. Cada registro é autodescritivo, projetado para flexibilidade de esquema com dados semiestruturados. Cada registro contém os dados e o esquema que descreve esses dados. Você pode usar quadros dinâmicos e DataFrames do Apache Spark em seus scripts de ETL, bem como converter entre eles. Os quadros dinâmicos fornecem um conjunto de transformações avançadas para limpeza de dados e ETL.
Trabalho
A lógica de negócios que é necessária para executar o trabalho de ETL. Ela é composta por um script de transformação, fonte de dados e destinos de dados. As execuções de trabalho são iniciadas por gatilhos que podem ser programados ou acionados por eventos.
Painel de performance do trabalho
O AWS Glue fornece um painel de execução abrangente para seus trabalhos de ETL. O painel exibe informações sobre execuções de trabalhos a partir de um período de tempo específico.
Interface do bloco de anotações
Uma experiência aprimorada de bloco de anotações com configuração com um clique para facilitar a criação de trabalhos e a exploração de dados. O bloco de anotações e as conexões são configurados automaticamente para você. Você pode usar a interface de caderno baseada na Juypter Notebook para desenvolver, depurar e implantar interativamente scripts e fluxos de trabalho usando a infraestrutura Apache Spark de ETL com tecnologia sem servidor do AWS Glue. Você pode realizar também consultas ad-hoc, análise de dados e visualização (por exemplo, tabelas e gráficos) no ambiente do bloco de anotações.
Script
Código que extrai dados de origens, transforma esses dados e os carrega em destinos. O AWS Glue gera scripts PySpark ou Scala.
Tabela
A definição de metadados que representa seus dados. Não importa se os seus dados estão em um arquivo do Amazon Simple Storage Service (Amazon S3), uma tabela do Amazon Relational Database Service (Amazon RDS) ou em outro conjunto de dados, uma tabela definirá o esquema dos seus dados. Uma tabela no AWS Glue Data Catalog consiste em nomes de colunas, definições de tipos de dados, informações de partição e outros metadados relacionados a um conjunto de dados de base. O esquema de dados é representado na sua definição da tabela do AWS Glue. Os dados reais permanecem no seu armazenamento de dados original, em um arquivo ou uma tabela de banco de dados relacional. O AWS Glue cataloga seus arquivos e tabelas de banco de dados relacional no AWS Glue Data Catalog. Eles são usados como fontes e destinos quando você cria um trabalho de ETL.
Transformação
A lógica de código que é usada para manipular seus dados em um formato diferente.
Trigger
Inicia um trabalho de ETL. Os gatilhos podem ser definidos com base em um horário/evento programado.
Editor de trabalho visual
O editor visual de tarefas é uma interface gráfica que facilita a criação, a execução e o monitoramento de tarefas de extração, transformação e carregamento (ETL) em AWS Glue. Você pode compor visualmente fluxos de trabalho de transformação de dados e executá-los perfeitamente no mecanismo de ETL com tecnologia sem servidor no Apache Spark do AWS Glue e inspecionar o esquema e os resultados de dados em cada etapa do trabalho.
Operador
Com o AWS Glue, você só paga pelo tempo que seu trabalho de ETL leva para ser executado. Não há recursos para gerenciar, nenhum custo inicial e você não será cobrado pelo tempo de inicialização ou desligamento. É cobrada uma taxa por hora com base no número de unidades de processamento de dados (ou DPUs) usadas para executar seu trabalho de ETL. Uma única unidade de processamento de dados (DPU) também é chamada de operador. O AWS Glue oferece vários tipos de operador para ajudar você a selecionar uma configuração que atenda aos requisitos de latência do trabalho e custo. Os operadores estão disponíveis nas configurações Padrão, G.1X, G.2X, G.4X, G.8X, G.12X, G.16X, G.025X e nas configurações otimizadas para memória R.1X, R.2X, R.4X, R.8X.
