Conector do DynamoDB com suporte para Spark DataFrame
O conector do DynamoDB com suporte para Spark DataFrame permite ler e gravar em tabelas no DynamoDB usando as APIs do Spark DataFrame. As etapas de configuração do conector são as mesmas do conector baseado em DynamicFrame e podem ser encontradas aqui.
Para carregar na biblioteca de conectores baseada em DataFrame, certifique-se de conectar uma conexão do DynamoDB ao trabalho do Glue.
nota
Atualmente, a interface de usuário do console do Glue não oferece suporte à criação de uma conexão do DynamoDB. Você pode usar a CLI do Glue (CreateConnection) para criar uma conexão do DynamoDB:
aws glue create-connection \ --connection-input '{ \ "Name": "my-dynamodb-connection", \ "ConnectionType": "DYNAMODB", \ "ConnectionProperties": {}, \ "ValidateCredentials": false, \ "ValidateForComputeEnvironments": ["SPARK"] \ }'
Ao criar a conexão do DynamoDB, você pode anexá-la ao seu trabalho do Glue via CLI (CreateJob, UpdateJob) ou diretamente na página “Detalhes do trabalho”:
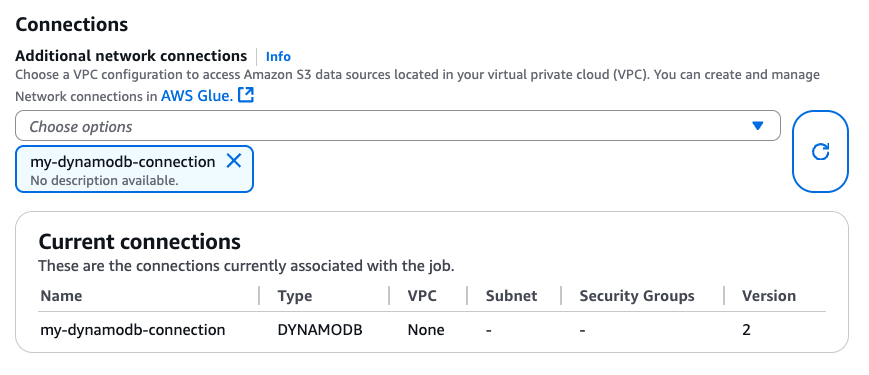
Ao garantir que uma conexão com o DYNAMODB Type esteja conectada ao seu trabalho do Glue, é possível usar as seguintes operações de leitura, gravação e exportação do conector baseado em DataFrame.
Ler e gravar no DynamoDB com o conector baseado em DataFrame
Os exemplos de código a seguir mostram como ler e gravar em tabelas do DynamoDB por meio do conector baseado em DataFrame. Eles demonstram a leitura de uma tabela e a gravação em uma outra tabela.
Usar a exportação do DynamoDB por meio do conector baseado em DataFrame
A operação de exportação é preferida à operação de leitura para tamanhos de tabela do DynamoDB maiores que 80 GB. Os exemplos de código a seguir mostram como ler de uma tabela, exportar para o S3 e imprimir o número de partições por meio do conector baseado em DataFrame.
nota
A funcionalidade de exportação do DynamoDB está disponível por meio do objeto DynamoDBExport do Scala. Os usuários do Python podem acessá-la por meio da interoperabilidade JVM do Spark ou usar o AWS SDK para Python (Boto3) com a API ExportTableToPointInTime do DynamoDB.
Opções de configuração
Opções de leitura
| Opção | Descrição | Padrão |
|---|---|---|
dynamodb.input.tableName |
Nome da tabela do DynamoDB (obrigatório) | - |
dynamodb.throughput.read |
As unidades de capacidade de leitura (RCU) a serem usadas. Se não for especificada, dynamodb.throughput.read.ratio é usado para cálculo. |
- |
dynamodb.throughput.read.ratio |
A proporção de unidades de capacidade de leitura (RCU) para uso | 0,5 |
dynamodb.table.read.capacity |
A capacidade de leitura da tabela sob demanda usada para calcular o throughput. Esse parâmetro é efetivo somente em tabelas de capacidade sob demanda. O padrão é aquecer as unidades de leitura de throughput. | - |
dynamodb.splits |
Define quantos segmentos são usados em operações de verificação paralela. Se não for fornecido, o conector calculará um valor padrão razoável. | - |
dynamodb.consistentRead |
Se deve usar leituras altamente consistentes | FALSE |
dynamodb.input.retry |
Define quantas tentativas fazemos quando há uma exceção que pode ser repetida. | 10 |
Opções de gravação
| Opção | Descrição | Padrão |
|---|---|---|
dynamodb.output.tableName |
Nome da tabela do DynamoDB (obrigatório) | - |
dynamodb.throughput.write |
Unidades de capacidade de gravação (WCU) a serem usadas. Se não for especificada, dynamodb.throughput.write.ratio é usado para cálculo. |
- |
dynamodb.throughput.write.ratio |
A proporção de unidades de capacidade de gravação (WCU) a serem usadas | 0,5 |
dynamodb.table.write.capacity |
A capacidade de gravação da tabela sob demanda usada para calcular o throughput. Esse parâmetro é efetivo somente em tabelas de capacidade sob demanda. O padrão é aquecer as unidades de gravação de throughput. | - |
dynamodb.item.size.check.enabled |
Se verdadeiro, o conector calcula o tamanho do item e aborta se o tamanho exceder o tamanho máximo, antes de gravar na tabela do DynamoDB. | TRUE |
dynamodb.output.retry |
Define quantas tentativas fazemos quando há uma exceção que pode ser repetida. | 10 |
Opções de exportação
| Opção | Descrição | Padrão |
|---|---|---|
dynamodb.export |
Se definido como ddb, habilita o conector de exportação para DynamoDB do AWS Glue, onde um novo ExportTableToPointInTimeRequet será invocado durante o trabalho do AWS Glue. Uma nova exportação será gerada com o local repassado de dynamodb.s3.bucket e dynamodb.s3.prefix. Se definido como s3, habilita o conector de exportação do AWS Glue DynamoDB, mas ignora a criação de uma nova exportação do DynamoDB. Em vez disso, usa o dynamodb.s3.bucket e dynamodb.s3.prefix como o local do Amazon S3 de uma exportação anterior dessa tabela. |
ddb |
dynamodb.tableArn |
A tabela do DynamoDB da qual se deseja ler os dados. Necessário se dynamodb.export estiver definido como ddb. |
|
dynamodb.simplifyDDBJson |
Se definido como true, executa uma transformação para simplificar o esquema da estrutura JSON do DynamoDB que está presente nas exportações. |
FALSE |
dynamodb.s3.bucket |
O bucket do S3 para armazenar dados temporários durante a exportação do DynamoDB (obrigatório) | |
dynamodb.s3.prefix |
O prefixo do S3 para armazenar dados temporários durante a exportação do DynamoDB | |
dynamodb.s3.bucketOwner |
Indica o proprietário do bucket necessário para acesso entre contas do Amazon S3 | |
dynamodb.s3.sse.algorithm |
Tipo de criptografia usada no bucket em que os dados temporários serão armazenados. Os valores válidos são AES256 e KMS. |
|
dynamodb.s3.sse.kmsKeyId |
O ID da chave gerenciada do AWS KMS usada para criptografar o bucket do S3 onde os dados temporários serão armazenados (se aplicável). | |
dynamodb.exportTime |
Um momento no qual a exportação deve ser feita. Valores válidos: strings representando instantes ISO-8601. |
Opções gerais
| Opção | Descrição | Padrão |
|---|---|---|
dynamodb.sts.roleArn |
O ARN do perfil do IAM a ser assumido para acesso entre contas. | - |
dynamodb.sts.roleSessionName |
Nome da sessão do STS | glue-dynamodb-sts-session |
dynamodb.sts.region |
Região do cliente STS (para suposição de perfil entre regiões) | Igual à opção region |
