As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Criação de um fluxo de trabalho de correspondência baseado em regras com o tipo de regra Avançado
Pré-requisitos
Antes de criar um fluxo de trabalho de correspondência baseado em regras, você deve:
-
Crie um mapeamento de esquema. Para obter mais informações, consulte Criação de um mapeamento de esquema.
-
Se estiver usando o Connect Customer Customer Profiles como seu destino de saída, verifique se você tem as permissões apropriadas configuradas.
O procedimento a seguir demonstra como criar um fluxo de trabalho de correspondência baseado em regras com o tipo de regra Avançado usando o AWS Entity Resolution console ou a API. CreateMatchingWorkflow
- Console
-
Para criar um fluxo de trabalho de correspondência baseado em regras com o Advanced (Avançado) tipo de regra usando o console
-
Faça login no Console de gerenciamento da AWS e abra o AWS Entity Resolution console em https://console.aws.amazon.com/entityresolution/
. -
No painel de navegação esquerdo, em Fluxos de trabalho, escolha Correspondência.
-
Na página Fluxos de trabalho correspondentes, no canto superior direito, escolha Criar fluxo de trabalho correspondente.
-
Para a Etapa 1: Especificar os detalhes correspondentes do fluxo de trabalho, faça o seguinte:
-
Insira um nome de fluxo de trabalho correspondente e uma Descrição opcional.
-
Em Entrada de dados, escolha um AWS Glue banco de dados Região da AWS, a AWS Glue tabela e, em seguida, o mapeamento do esquema correspondente.
Você pode adicionar até 19 entradas de dados.
nota
Para usar regras avançadas, seus mapeamentos de esquema devem atender aos seguintes requisitos:
-
Cada campo de entrada deve ser mapeado para uma chave de correspondência exclusiva, a menos que os campos estejam agrupados.
-
Se os campos de entrada estiverem agrupados, eles poderão compartilhar a mesma chave de correspondência.
Por exemplo, o mapeamento de esquema a seguir seria válido para regras avançadas:
firstName: { matchKey: 'name', groupName: 'name' }lastName: { matchKey: 'name', groupName: 'name' }Nesse caso, os
lastNamecamposfirstNamee são agrupados e compartilham a mesma chave de correspondência de nome, o que é permitido.Revise seus mapeamentos de esquema e atualize-os para seguir essa regra de correspondência individual, a menos que os campos estejam agrupados corretamente, para usar as regras avançadas.
-
Se sua tabela de dados tiver uma coluna DELETE, o tipo do mapeamento do esquema deve ser
Stringe você não pode ter ummatchKeye.groupName
-
-
A opção Normalizar dados é selecionada por padrão, para que as entradas de dados sejam normalizadas antes da correspondência. Se você não quiser normalizar dados, desmarque a opção Normalizar dados.
nota
A normalização só é suportada nos seguintes cenários em Criar mapeamento de esquema:
-
Se os seguintes subtipos de nome estiverem agrupados: Nome, segundo nome, sobrenome.
-
Se os seguintes subtipos de endereço estiverem agrupados: Endereço 1, Endereço 2, Endereço 3, Cidade, Estado, País, Código postal.
-
Se os seguintes subtipos de telefone estiverem agrupados: Número de telefone, Código do país do telefone.
-
-
Para especificar as permissões de acesso ao serviço, escolha uma opção e execute a ação recomendada.
Opção Ação recomendada Criar e usar um novo perfil de serviço -
AWS Entity Resolution cria uma função de serviço com a política necessária para essa tabela.
-
O nome do perfil de serviço padrão é
entityresolution-matching-workflow-<timestamp>. -
Você deve ter permissões para criar perfis e anexar políticas.
-
Se seus dados de entrada estiverem criptografados, você poderá escolher a opção Esses dados são criptografados com uma chave KMS e, em seguida, inserir uma AWS KMS chave que será usada para descriptografar sua entrada de dados.
Use um perfil de serviço existente -
Escolha um nome do perfil de serviço existente na lista suspensa.
A lista de perfis é exibida se você tiver permissões para listar funções.
Se você não tiver permissões para listar perfis, insira o nome do recurso da Amazon (ARN) do perfil que você deseja usar.
Se não houver perfis de serviço existentes, a opção de Usar um perfil de serviço existente não estará disponível.
-
Para visualizar o perfil de serviço, selecione o link externo Visualizar no IAM.
Por padrão, AWS Entity Resolution não tenta atualizar a política de função existente para adicionar as permissões necessárias.
-
-
(Opcional) Para ativar tags para o recurso, escolha Adicionar nova tag e insira o par de chave e valor.
-
Escolha Próximo.
-
-
Para a Etapa 2: Escolha a técnica de correspondência:
-
Em Método de correspondência, escolha Rule-basedcorrespondência.
-
Em Tipo de regra, escolha Avançado.
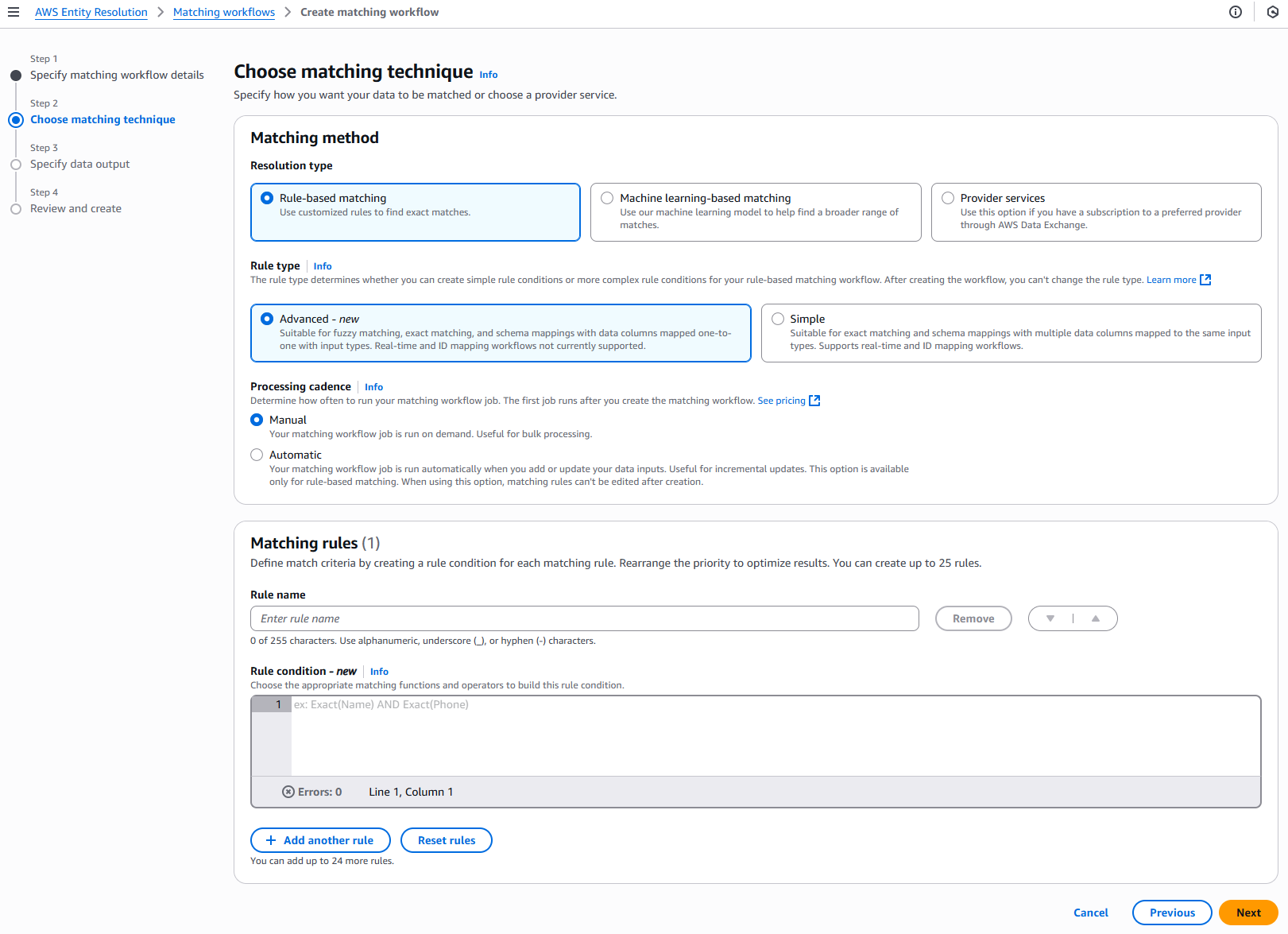
-
Em Cadência de processamento, selecione uma das opções a seguir.
-
Escolha Manual para executar um fluxo de trabalho sob demanda para uma atualização em massa
-
Escolha Automático para executar um fluxo de trabalho assim que novos dados estiverem em seu bucket do S3
nota
Se você escolher Automático, certifique-se de ter EventBridge as notificações da Amazon ativadas para seu bucket do S3. Para obter instruções sobre como habilitar a Amazon EventBridge usando o console do S3, consulte Habilitando a Amazon EventBridge no Guia do usuário do Amazon S3.
-
-
Em Regras de correspondência, insira um nome de regra e, em seguida, crie a condição da regra escolhendo as funções e operadores de correspondência apropriados na lista suspensa com base em sua meta.
Você pode criar até 25 regras.
nota
AWS Entity Resolution também oferece suporte à correspondência transitiva, que processa registros em todos os níveis de regras para conectar grupos de correspondência de forma transitiva. A correspondência transitiva está disponível como um API-only recurso. Quando a correspondência transitiva está ativada, o modificador EmptyValues=Ignorar não é suportado. Para obter mais informações, consulte Usando correspondência transitiva.
Você deve combinar uma função de correspondência difusa (Cosine, Levenshtein ou Soundex) com uma função de correspondência exata (Exact,) usando o operador AND. ExactManyToMany
Você pode usar a tabela a seguir para ajudar a decidir que tipo de função ou operador deseja usar, dependendo da sua meta.
Seu objetivo Função ou operador recomendados Modificador opcional recomendado Prós Combine cadeias de caracteres idênticas em dados precisos, mas não corresponda a valores vazios. Exato EmptyValues=Processo Combine cadeias idênticas em dados precisos e ignore valores vazios. Exato ( matchKey)EmptyValues=Ignorar Combine vários registros nas teclas de partida. Adequado para emparelhamentos flexíveis. Limite: 15 teclas de partida ExactManyToMany( matchKey,matchKey, ...)n/a Meça a semelhança entre as representações numéricas dos dados, mas não faça a correspondência em valores vazios. Adequado para texto, números ou uma combinação de ambos. Cosseno EmptyValues=Processo Simples e eficiente.
Funciona bem com texto longo quando combinado com TF-IDF ponderação.
Bom para correspondência exata baseada em palavras.
Meça a semelhança entre representações numéricas de dados e ignore valores vazios. Cosseno ( matchKey,threshold,...)EmptyValues=Ignorar Lida bem com erros de digitação, erros ortográficos e transposições.
Eficaz em uma ampla variedade de tipos de PII.
Bom para sequências curtas (por exemplo, nomes ou números de telefone).
Conte o número mínimo de alterações necessárias para transformar uma palavra em outra, mas não corresponda aos valores vazios. Adequado para texto com pequenas diferenças na ortografia. Levenshtein EmptyValues=Processo Conte o número mínimo de alterações necessárias para transformar uma palavra em outra e ignore valores vazios. Levenshtein (,,...) matchKeythresholdEmptyValues=Ignorar Compare e combine cadeias de texto com base em quão parecidas elas soam, mas não coincidem em valores vazios. Adequado para texto com variações na ortografia ou pronúncia. Soundex EmptyValues=Processo Eficaz para correspondência fonética, identificando palavras com sons semelhantes.
Rápido e computacionalmente barato.
Bom para combinar nomes com pronúncias semelhantes, mas com grafias diferentes.
Compare e combine cadeias de texto com base na semelhança entre elas e ignore valores vazios. Som (1) matchKeyEmptyValues=Ignorar Combine funções. E n/a Funções separadas. OU n/a Agrupe as condições para criar condições aninhadas. (…) n/a exemplo Condição de regra que corresponde aos números de telefone e e-mail
Veja a seguir um exemplo de uma condição de regra que corresponde a registros em números de telefone (chave de correspondência de telefone) e endereços de e-mail (chave de correspondência de endereço de e-mail):
Exact(Phone,EmptyValues=Process) AND Levenshtein("Email address",2)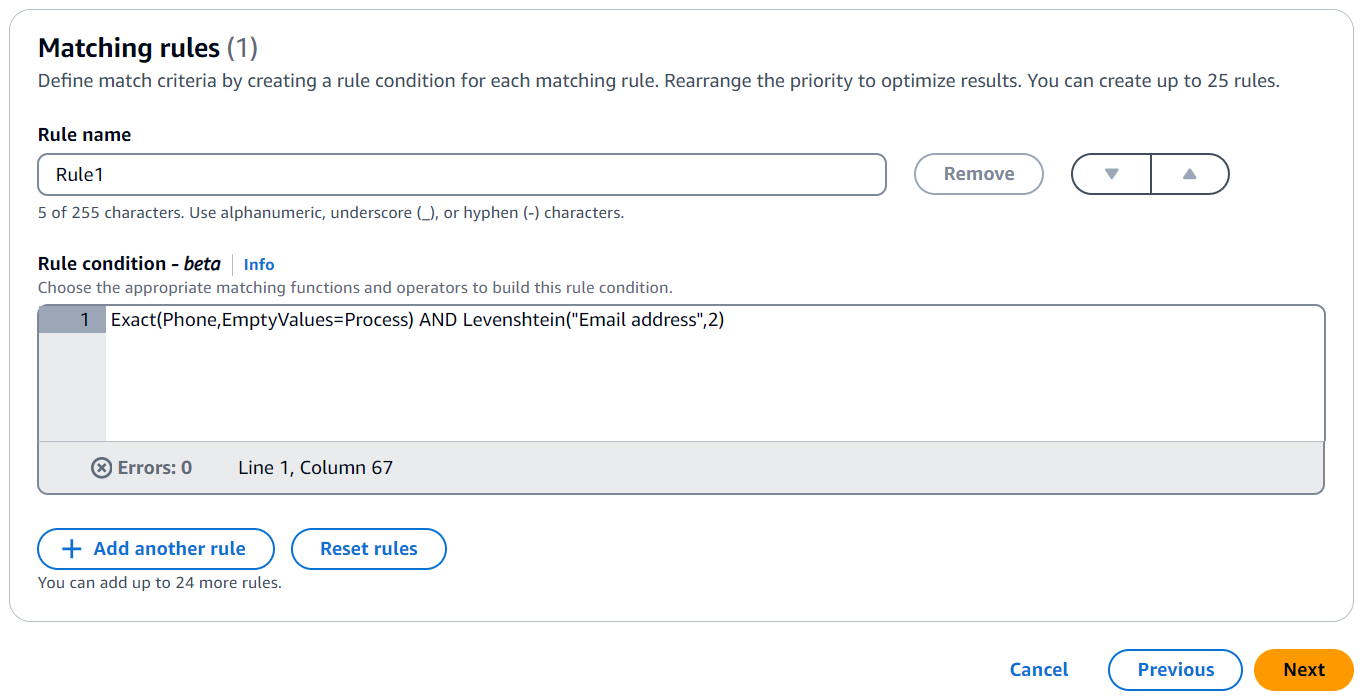
A tecla Phone match usa a função de correspondência exata para combinar sequências idênticas. A tecla Phone match processa valores vazios na correspondência usando o modificador EmptyValues=Process.
A chave de correspondência de endereço de e-mail usa a função de correspondência Levenshtein para combinar dados com erros ortográficos usando o limite padrão do algoritmo de distância Levenshtein de 2. A tecla de correspondência de e-mail não usa nenhum modificador opcional.
O operador AND combina a função de correspondência exata e a função de correspondência Levenshtein.
exemplo Condição de regra usada ExactManyToMany para realizar a correspondência de teclas de correspondência
Veja a seguir um exemplo de uma condição de regra que combina registros em três campos de endereço (HomeAddresschave de BillingAddresscorrespondência, chave de ShippingAddresscorrespondência e chave de correspondência) para encontrar possíveis correspondências verificando se alguma delas tem valores idênticos.
O
ExactManyToManyoperador avalia todas as combinações possíveis dos campos de endereço especificados para identificar correspondências exatas entre dois ou mais endereços. Por exemplo, ele detectaria se os endereçosHomeAddresscorrespondem aBillingAddressouShippingAddressou se todos os três endereços correspondem exatamente.ExactManyToMany(HomeAddress, BillingAddress, ShippingAddress)exemplo Condição de regra que usa agrupamento
Na correspondência avançada baseada em regras com condições difusas, o sistema primeiro agrupa os registros em clusters com base nas correspondências exatas. Depois que esses clusters iniciais são formados, o sistema aplica filtros de correspondência difusa para identificar correspondências adicionais em cada cluster. Para um desempenho ideal, você deve selecionar condições de correspondência exatas com base em seus padrões de dados para criar clusters iniciais bem definidos.
Veja a seguir um exemplo de uma condição de regra que combina várias correspondências exatas com um requisito de correspondência difusa. Ele usa
ANDoperadores para verificar se três campos —FullName, Data de nascimento (DOB) eAddress— coincidem exatamente entre os registros. Também permite pequenas variações noInternalIDcampo usando uma distância de Levenshtein de.1A distância de Levenshtein mede o número mínimo de edições de um único caractere necessárias para transformar uma string em outra. Uma distância de 1 significaInternalIDsque ela corresponderá à diferença em apenas um caractere (como um único erro de digitação, exclusão ou inserção). Essa combinação de condições ajuda a identificar registros que provavelmente representarão a mesma entidade, mesmo que haja pequenas discrepâncias no identificador.Exact(FullName) AND Exact(DOB) AND Exact(Address) and Levenshtein(InternalID, 1) -
Escolha Próximo.
-
-
Para a Etapa 3: Especifique a saída e o formato dos dados:
-
Em Destino e formato de saída de dados, escolha a localização do Amazon S3 para a saída de dados e se o formato dos dados será dados normalizados ou dados originais.
-
Em Criptografia, se você optar por Personalizar as configurações de criptografia, insira o ARN da AWS KMS chave.
-
Visualize a saída gerada pelo sistema.
-
Para Saída de dados, decida quais campos você deseja incluir, ocultar ou mascarar e, em seguida, execute as ações recomendadas com base em suas metas.
Seu objetivo Ação recomendada Incluir campos Mantenha o estado de saída como Incluído. Ocultar campos (excluir da saída) Escolha o campo Saída e escolha Ocultar. Campos de máscara Escolha o campo Saída e, em seguida, escolha Saída de hash. Redefinir as configurações anteriores Escolha Redefinir. -
Escolha Próximo.
-
-
Para a Etapa 4: Revise e crie:
-
Revise as seleções feitas nas etapas anteriores e edite, se necessário.
-
Escolha Criar e executar.
Uma mensagem aparece indicando que o fluxo de trabalho correspondente foi criado e que o trabalho foi iniciado.
-
-
Na página de detalhes do fluxo de trabalho correspondente, na guia Métricas, veja o seguinte em Métricas do último trabalho:
-
O Job ID.
-
O status da tarefa de fluxo de trabalho correspondente: Em fila, em andamento, concluída, com falha
-
O tempo concluído para o trabalho do fluxo de trabalho.
-
O número de registros processados.
-
O número de registros não processados.
-
Os IDs de correspondência exclusivos gerados.
-
O número de registros de entrada.
Você também pode visualizar as métricas de trabalho para trabalhos de fluxo de trabalho correspondentes que foram executados anteriormente no Histórico de trabalhos.
-
-
Após a conclusão do trabalho de fluxo de trabalho correspondente (o status é concluído), você pode acessar a guia Saída de dados e selecionar sua localização no Amazon S3 para visualizar os resultados.
-
(Somente tipo de processamento manual) Se você criou um fluxo de trabalho Rule-based correspondente com o tipo de processamento manual, você pode executar o fluxo de trabalho correspondente a qualquer momento escolhendo Executar fluxo de trabalho na página de detalhes do fluxo de trabalho correspondente.
-
(Somente tipo de processamento automático) Se sua tabela de dados tiver uma coluna DELETE, então:
-
Os registros definidos
truena coluna DELETE são excluídos. -
Os registros definidos
falsena coluna DELETE são ingeridos no S3.
Para obter mais informações, consulte Etapa 1: Preparar tabelas de dados primárias.
-
-
- API
-
Para criar um fluxo de trabalho de correspondência baseado em regras com o Advanced (Avançado) tipo de regra usando a API
nota
Por padrão, o fluxo de trabalho usa processamento padrão (em lote). Para usar o processamento incremental (automático), você deve configurá-lo explicitamente.
-
Abra um terminal ou prompt de comando para fazer a solicitação da API.
-
Crie uma solicitação POST para o seguinte endpoint:
/matchingworkflows -
No cabeçalho da solicitação, Content-type defina application/json o.
nota
Para obter uma lista completa das linguagens de programação compatíveis, consulte a Referência AWS Entity Resolution da API.
-
Para o corpo da solicitação, forneça os seguintes parâmetros JSON necessários:
{ "description": "string", "incrementalRunConfig": { "incrementalRunType": "string" }, "inputSourceConfig": [ { "applyNormalization":boolean, "inputSourceARN": "string", "schemaName": "string" } ], "outputSourceConfig": [ { "applyNormalization":boolean, "KMSArn": "string", "output": [ { "hashed": boolean, "name": "string" } ], "outputS3Path": "string" } ], "resolutionTechniques": { "providerProperties": { "intermediateSourceConfiguration": { "intermediateS3Path": "string" }, "providerConfiguration":JSON value, "providerServiceArn": "string" }, "resolutionType": "RULE_MATCHING", "ruleBasedProperties": { "attributeMatchingModel": "string", "matchPurpose": "string", "rules": [ { "matchingKeys": [ "string" ], "ruleName": "string" } ] }, "ruleConditionProperties": { "rules": [ { "condition": "string", "ruleName": "string" } ] } }, "roleArn": "string", "tags": { "string" : "string" }, "workflowName": "stringEm que:
-
workflowName(obrigatório) — Deve ser exclusivo e ter entre 1—255 caracteres que correspondam ao padrão [a-z A-Z _0-9-] * -
inputSourceConfig(obrigatório) — Lista de 1—20 configurações de fonte de entrada -
outputSourceConfig(obrigatório) — Exatamente uma configuração de fonte de saída -
resolutionTechniques(obrigatório) — Defina como “RULE_MATCHING” como o tipo de resolução para correspondência baseada em regras -
roleArn(obrigatório) — ARN da função do IAM para execução do fluxo de trabalho -
ruleConditionProperties(obrigatório) — Lista de condições da regra e o nome da regra correspondente.
Os parâmetros opcionais incluem:
-
description— Até 255 caracteres -
incrementalRunConfig— Configuração incremental do tipo de execução -
tags— Até 200 pares de valores-chave
-
-
(Opcional) Para usar o processamento incremental em vez do processamento padrão (em lote), adicione o seguinte parâmetro ao corpo da solicitação:
"incrementalRunConfig": { "incrementalRunType": "AUTOMATIC" } -
Envie a solicitação .
-
Se for bem-sucedido, você receberá uma resposta com o código de status 200 e um corpo JSON contendo:
{ "workflowArn": "string", "workflowName": "string", // Plus all configured workflow details } -
Se a chamada não for bem-sucedida, você poderá receber um destes erros:
-
400 — ConflictException se o nome do fluxo de trabalho já existir
-
400 — ValidationException se a entrada falhar na validação
-
402 — ExceedsLimitException se os limites da conta forem excedidos
-
403 — AccessDeniedException se você não tiver acesso suficiente
-
429 — ThrottlingException se a solicitação foi limitada
-
500 — InternalServerException se houver uma falha de serviço interno
-
-
