As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Uso de cadernos Jupyter de hospedagem própria
Você pode hospedar e gerenciar o Jupyter ou JupyterLab notebooks em uma instância do Amazon EC2 ou em seu próprio cluster Amazon EKS como um notebook Jupyter auto-hospedado. Em seguida, é possível executar workloads interativas com seus cadernos Jupyter de hospedagem própria. As seções apresentadas a seguir descrevem o processo de configuração e de implantação de um caderno Jupyter de hospedagem própria em um cluster do Amazon EKS.
Criação de um caderno Jupyter de hospedagem própria em um cluster do EKS
Criar um grupo de segurança
Antes de criar um endpoint interativo e executar um Jupyter ou JupyterLab notebook auto-hospedado, você deve criar um grupo de segurança para controlar o tráfego entre seu notebook e o endpoint interativo. Para usar o console do Amazon EC2 ou o SDK do Amazon EC2 para criar o grupo de segurança, consulte as etapas em Create a security group no Guia do usuário do Amazon EC2. Você deve criar o grupo de segurança na VPC em que deseja implantar seu servidor de cadernos.
Para seguir o exemplo deste guia, use a mesma VPC do cluster do Amazon EKS. Se você quiser hospedar seu notebook em uma VPC diferente da VPC do seu cluster Amazon EKS, talvez seja necessário criar uma conexão de emparelhamento entre essas duas. VPCs Para ver as etapas para criar uma conexão de emparelhamento entre duas VPCs, consulte Criar uma conexão de emparelhamento de VPC no Amazon VPC Getting Started Guide.
Você precisará do ID do grupo de segurança para criar um endpoint interativo do Amazon EMR no EKS na próxima etapa.
Criação de um endpoint interativo do Amazon EMR no EKS
Após criar o grupo de segurança para o seu caderno, use as etapas fornecidas em Criação de um endpoint interativo para o cluster virtual para criar um endpoint interativo. Você deve fornecer o ID do grupo de segurança criado para o seu caderno em Criar um grupo de segurança.
Insira o ID de segurança no lugar das your-notebook-security-group-id seguintes configurações de substituição de configuração:
--configuration-overrides '{ "applicationConfiguration": [ { "classification": "endpoint-configuration", "properties": { "notebook-security-group-id": "your-notebook-security-group-id" } } ], "monitoringConfiguration": { ...'
Recuperação do URL do servidor de gateway do endpoint interativo
Após criar um endpoint interativo, recupere o URL do servidor de gateway usando o comando describe-managed-endpoint na AWS CLI. Você precisa desse URL para conectar seu caderno ao endpoint. O URL do servidor de gateway é um endpoint privado.
aws emr-containers describe-managed-endpoint \ --regionregion\ --virtual-cluster-idvirtualClusterId\ --idendpointId
Inicialmente, seu endpoint está no estado CREATING. Após alguns minutos, ele passa para o estado ACTIVE. Quando o endpoint estiver ACTIVE, ele estará pronto para uso.
Anote o atributo serverUrl que o comando aws emr-containers
describe-managed-endpoint retorna do endpoint ativo. Você precisa dessa URL para conectar seu notebook ao endpoint ao implantar seu Jupyter ou notebook auto-hospedado. JupyterLab
Recuperação de um token de autenticação para a conexão com o endpoint interativo
Para se conectar a um endpoint interativo a partir de um Jupyter ou JupyterLab notebook, você deve gerar um token de sessão com a API. GetManagedEndpointSessionCredentials O token atua como prova de autenticação para a conexão com o servidor de endpoint interativo.
O comando apresentado a seguir é explicado com mais detalhes com um exemplo de saída abaixo.
aws emr-containers get-managed-endpoint-session-credentials \ --endpoint-identifierendpointArn\ --virtual-cluster-identifiervirtualClusterArn\ --execution-role-arnexecutionRoleArn\ --credential-type "TOKEN" \ --duration-in-secondsdurationInSeconds\ --regionregion
endpointArn-
O ARN do seu endpoint. Você pode descobrir o ARN no resultado de uma chamada
describe-managed-endpoint. virtualClusterArn-
O ARN do cluster virtual.
executionRoleArn-
O ARN do perfil de execução.
durationInSeconds-
A duração, em segundos, pela qual o token é válido. A duração padrão é de 15 minutos (
900) e a duração máxima é de 12 horas (43200). region-
A mesma região do seu endpoint.
A saída deve ser semelhante ao exemplo apresentado a seguir. Anote o session-token
{
"id": "credentialsId",
"credentials": {
"token": "session-token"
},
"expiresAt": "2022-07-05T17:49:38Z"
}Exemplo: implantar um JupyterLab notebook
Depois de concluir as etapas acima, você pode tentar este procedimento de exemplo para implantar um JupyterLab notebook no cluster Amazon EKS com seu endpoint interativo.
-
Crie um namespace para executar o servidor de cadernos.
-
Crie um arquivo localmente, chamado
notebook.yaml, com o conteúdo apresentado a seguir. O conteúdo para o arquivo é descrito abaixo.apiVersion: v1 kind: Pod metadata: name: jupyter-notebook namespace:namespacespec: containers: - name: minimal-notebook image: jupyter/all-spark-notebook:lab-3.1.4 # open source image ports: - containerPort: 8888 command: ["start-notebook.sh"] args: ["--LabApp.token=''"] env: - name: JUPYTER_ENABLE_LAB value: "yes" - name: KERNEL_LAUNCH_TIMEOUT value: "400" - name: JUPYTER_GATEWAY_URL value: "serverUrl" - name: JUPYTER_GATEWAY_VALIDATE_CERT value: "false" - name: JUPYTER_GATEWAY_AUTH_TOKEN value: "session-token"Se você estiver implantando o caderno Jupyter em um cluster somente do Fargate, rotule o pod do Jupyter com um rótulo
role, conforme mostrado no seguinte exemplo:... metadata: name: jupyter-notebook namespace: default labels: role:example-role-name-labelspec: ...namespace-
O namespace do Kubernetes no qual o caderno é implantado.
serverUrl-
O atributo
serverUrlque o comandodescribe-managed-endpointretornou em Recuperação do URL do servidor de gateway do endpoint interativo. session-token-
O atributo
session-tokenque o comandoget-managed-endpoint-session-credentialsretornou em Recuperação de um token de autenticação para a conexão com o endpoint interativo. KERNEL_LAUNCH_TIMEOUT-
A quantidade de tempo, em segundos, que o endpoint interativo aguarda até que o kernel chegue ao estado RUNNING. Garanta tempo suficiente para a inicialização do kernel ser concluída ao definir o tempo limite de inicialização do kernel para um valor apropriado (máximo de 400 segundos).
KERNEL_EXTRA_SPARK_OPTS-
Como opção, você pode transferir configurações adicionais do Spark para os kernels do Spark. Defina essa variável de ambiente com os valores da propriedade de configuração do Spark, conforme mostrado no seguinte exemplo:
- name: KERNEL_EXTRA_SPARK_OPTS value: "--conf spark.driver.cores=2 --conf spark.driver.memory=2G --conf spark.executor.instances=2 --conf spark.executor.cores=2 --conf spark.executor.memory=2G --conf spark.dynamicAllocation.enabled=true --conf spark.dynamicAllocation.shuffleTracking.enabled=true --conf spark.dynamicAllocation.minExecutors=1 --conf spark.dynamicAllocation.maxExecutors=5 --conf spark.dynamicAllocation.initialExecutors=1 "
-
Implante a especificação do pod no cluster do Amazon EKS:
kubectl apply -f notebook.yaml -nnamespaceIsso iniciará um JupyterLab notebook mínimo conectado ao seu Amazon EMR no endpoint interativo EKS. Aguarde até que o pod esteja RUNNING. Você pode verificar seu status com o seguinte comando:
kubectl get pod jupyter-notebook -nnamespaceQuando o pod estiver pronto, o comando
get podretornará uma saída semelhante a esta:NAME READY STATUS RESTARTS AGE jupyter-notebook 1/1 Running 0 46s -
Anexe o grupo de segurança do caderno ao nó em que o caderno está programado.
-
Primeiro, identifique o nó em que o pod
jupyter-notebookestá programado com o comandodescribe pod.kubectl describe pod jupyter-notebook -nnamespace Abra o console do Amazon EKS em https://console.aws.amazon.com/eks/home#/clusters
. -
Navegue até a guia Computação do cluster do Amazon EKS e selecione o nó identificado pelo comando
describe pod. Selecione o ID da instância para o nó. -
No menu Ações, selecione Segurança > Alterar grupos de segurança para anexar o grupo de segurança que você criou em Criar um grupo de segurança.
-
Se você estiver implantando o pod do notebook Jupyter AWS Fargate, crie um
SecurityGroupPolicypara aplicar ao pod do notebook Jupyter com o rótulo de função:cat >my-security-group-policy.yaml <<EOF apiVersion: vpcresources.k8s.aws/v1beta1 kind: SecurityGroupPolicy metadata: name:example-security-group-policy-namenamespace: default spec: podSelector: matchLabels: role:example-role-name-labelsecurityGroups: groupIds: -your-notebook-security-group-idEOF
-
-
Agora, encaminhe a porta para que você possa acessar localmente a JupyterLab interface:
kubectl port-forward jupyter-notebook 8888:8888 -nnamespaceQuando estiver em execução, navegue até o navegador local e visite
localhost:8888para ver a JupyterLab interface: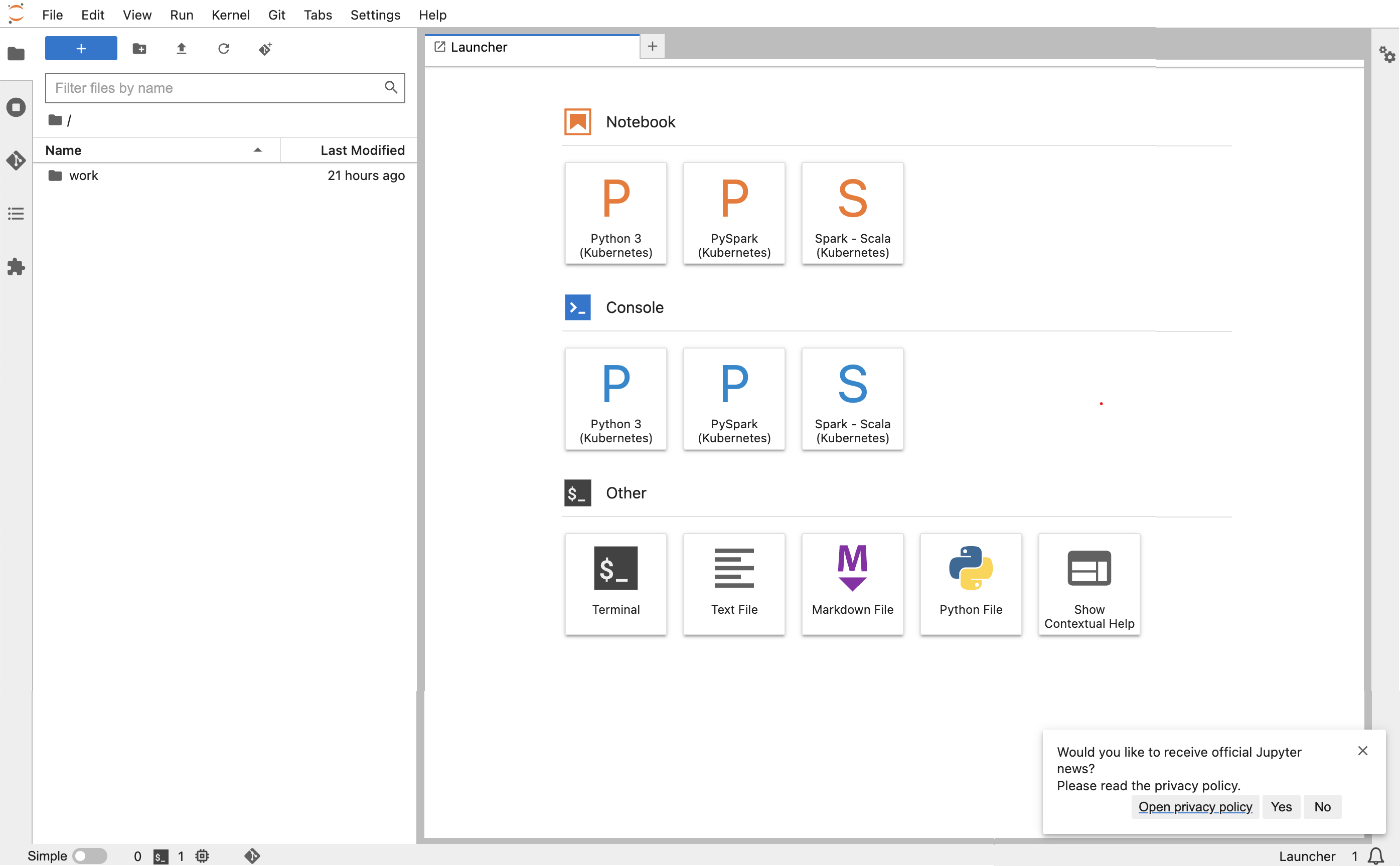
-
JupyterLabEm, crie um novo notebook Scala. Confira um exemplo de trecho de código que você pode executar para aproximar o valor de Pi:
import scala.math.random import org.apache.spark.sql.SparkSession /** Computes an approximation to pi */ val session = SparkSession .builder .appName("Spark Pi") .getOrCreate() val slices = 2 // avoid overflow val n = math.min(100000L * slices, Int.MaxValue).toInt val count = session.sparkContext .parallelize(1 until n, slices) .map { i => val x = random * 2 - 1 val y = random * 2 - 1 if (x*x + y*y <= 1) 1 else 0 }.reduce(_ + _) println(s"Pi is roughly ${4.0 * count / (n - 1)}") session.stop()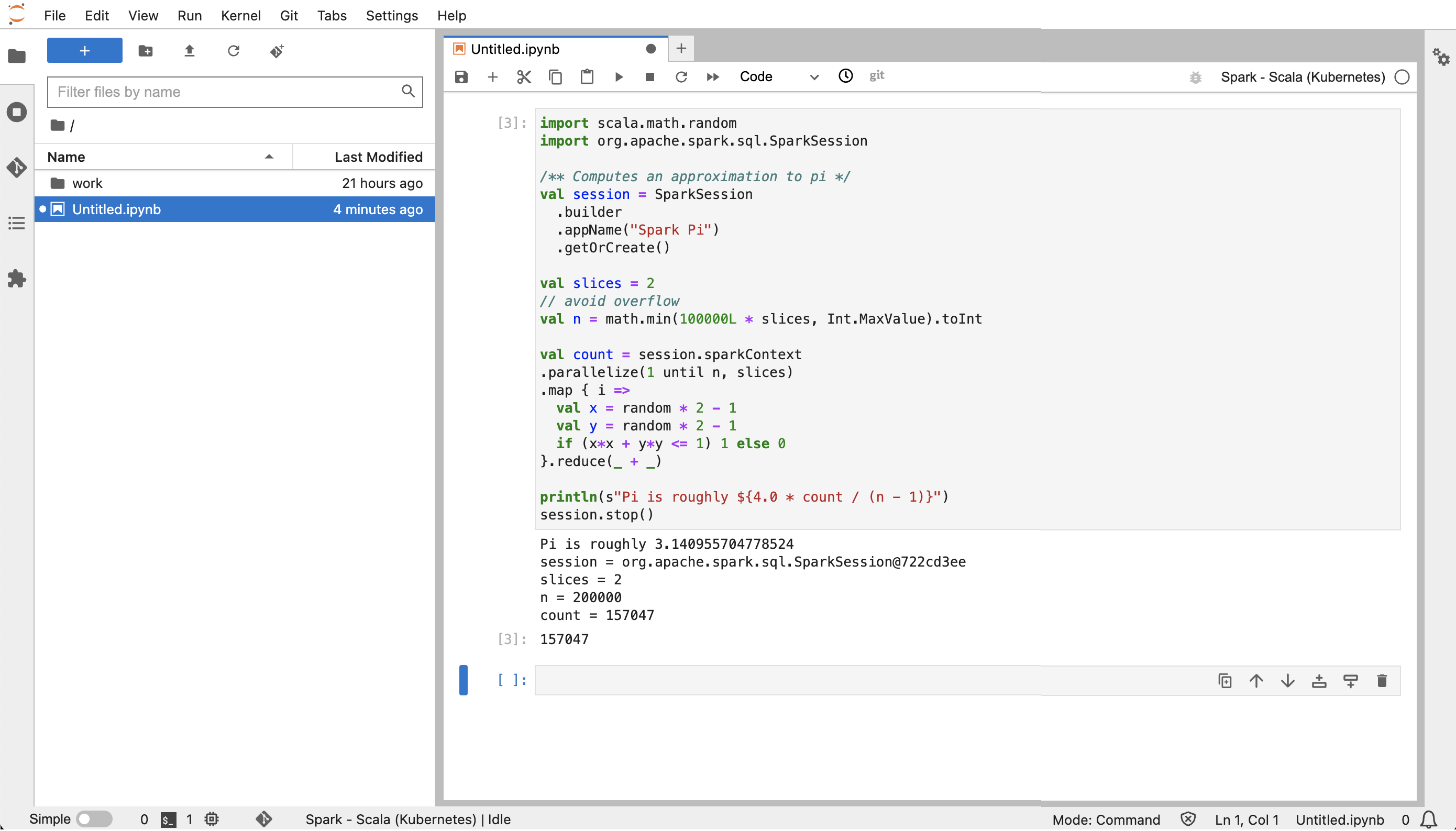
Exclusão de um caderno Jupyter de hospedagem própria
Quando estiver com tudo pronto para excluir seu caderno de hospedagem própria, você também poderá excluir o endpoint interativo e o grupo de segurança. Execute as ações na seguinte ordem:
-
Use o seguinte comando para excluir o pod
jupyter-notebook:kubectl delete pod jupyter-notebook -nnamespace -
Em seguida, exclua o endpoint interativo com o comando
delete-managed-endpoint. Para obter as etapas para a exclusão de um endpoint interativo, consulte Exclusão de um endpoint interativo. Inicialmente, seu endpoint estará no estado TERMINATING. Depois que todos os recursos forem limpos, ele transitará para o estado TERMINATED. -
Caso não planeje usar o grupo de segurança de cadernos criado em Criar um grupo de segurança para outras implantações de caderno Jupyter, você poderá excluí-lo. Consulte Excluir um grupo de segurança no Guia do usuário do Amazon EC2 para obter mais informações.
