As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Usando o EMR Serverless comAWS Lake Formationpara controle de acesso refinado
Visão geral do
Com as versões 7.2.0 e superiores do Amazon EMR, aproveite AWS Lake Formation para aplicar controles de acesso refinados em tabelas do catálogo de dados que são apoiadas pelo S3. Esse recurso permite configurar controles de acesso em nível de tabela, linha, coluna e célula para consultas de read nos trabalhos do Spark no Amazon EMR Sem Servidor. Para configurar um controle de acesso refinado para trabalhos em lote e sessões interativas do Apache Spark, use o EMR Studio. Consulte as seções a seguir para saber mais sobre o Lake Formation e como usá-lo com o EMR Sem Servidor.
O uso do Amazon EMR Serverless incorre em cobranças adicionais. AWS Lake Formation Para obter mais informações, consulte Preço do Amazon EMR
Como o EMR Serverless funciona comAWS Lake Formation
Usar o EMR Sem Servidor com o Lake Formation permite impor uma camada de permissões em cada trabalho do Spark para aplicar o controle de permissões do Lake Formation quando o EMR Sem Servidor executa trabalhos. O EMR Sem Servidor usa perfis de recursos do Spark
Ao usar a capacidade pré-inicializada com o Lake Formation, sugerimos que você tenha no mínimo dois drivers do Spark. Cada Formation-enabled tarefa do Lake utiliza dois drivers Spark, um para o perfil do usuário e outro para o perfil do sistema. Para obter o melhor desempenho, use o dobro do número de drivers para Formation-enabled trabalhos em Lake em comparação com se você não usa Lake Formation.
Ao executar trabalhos do Spark no EMR Sem Servidor, considere também o impacto da alocação dinâmica no gerenciamento de recursos e na performance do cluster. A configuração spark.dynamicAllocation.maxExecutors do número máximo de executores por perfil de recurso se aplica aos executores do usuário e do sistema. Se você configurar esse número para ser igual ao número máximo permitido de executores, a execução do trabalho poderá ficar paralisada devido a um tipo de executor que usa todos os recursos disponíveis, o que impede o outro executor ao executar trabalhos.
Para que você não fique sem recursos, o EMR Sem Servidor define o número máximo padrão de executores por perfil de recurso como 90% do valor de spark.dynamicAllocation.maxExecutors. Você pode substituir essa configuração ao especificar spark.dynamicAllocation.maxExecutorsRatio com um valor entre 0 e 1. Além disso, configure as seguintes propriedades para otimizar a alocação de recursos e a performance geral:
-
spark.dynamicAllocation.cachedExecutorIdleTimeout -
spark.dynamicAllocation.shuffleTracking.timeout -
spark.cleaner.periodicGC.interval
Confira a seguir uma visão geral de alto nível sobre como o EMR Sem Servidor obtém acesso aos dados protegidos pelas políticas de segurança do Lake Formation.
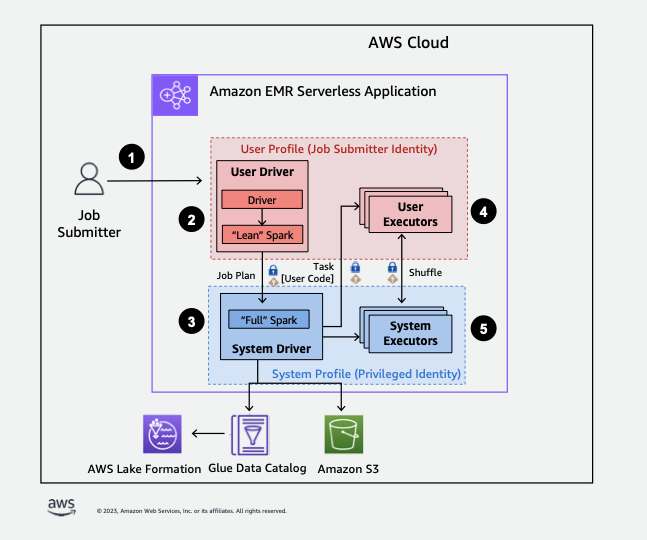
-
Um usuário envia uma tarefa do Spark para um aplicativo AWS Lake Formation EMR Serverless habilitado.
-
O EMR Sem Servidor envia o trabalho para um driver de usuário e executa o trabalho no perfil do usuário. O driver do usuário executa uma versão enxuta do Spark que não tem a capacidade de iniciar tarefas, solicitar executores, acessar o S3 ou o Glue Catalog. Ele cria um plano de trabalho.
-
O EMR Sem Servidor configura um segundo driver chamado driver do sistema e o executa no perfil do sistema (com uma identidade privilegiada). O EMR Sem Servidor configura um canal TLS criptografado entre os dois drivers para comunicação. O driver do usuário usa o canal para enviar os planos de trabalho ao driver do sistema. O driver do sistema não executa o código enviado pelo usuário. Ele executa o Spark completo e se comunica com o S3 e com o Data Catalog para acesso aos dados. Ele solicita executores e compila o plano de trabalho em uma sequência de estágios de execução.
-
Em seguida, o EMR Sem Servidor executa os estágios nos executores com o driver do usuário ou o driver do sistema. O código do usuário em qualquer estágio é executado exclusivamente nos executores do perfil do usuário.
-
Os estágios que lêem dados das tabelas do Catálogo de Dados protegidas por AWS Lake Formation ou que aplicam filtros de segurança são delegados aos executores do sistema.
Como habilitar o Lake Formation no Amazon EMR
Para habilitar o Lake Formation, defina spark.emr-serverless.lakeformation.enabled como true na classificação spark-defaults do parâmetro de configuração de runtime ao criar uma aplicação do EMR Sem Servidor.
aws emr-serverless create-application \ --release-label emr-7.13.0 \ --runtime-configuration '{ "classification": "spark-defaults", "properties": { "spark.emr-serverless.lakeformation.enabled": "true" } }' \ --type "SPARK"
Você também pode habilitar o Lake Formation ao criar uma aplicação no EMR Studio. Escolha Usar Lake Formation para um controle de acesso refinado, disponível em Configurações adicionais.
Inter-worker a criptografia é ativada por padrão quando você usa o Lake Formation com o EMR Serverless, portanto, você não precisa habilitar explicitamente a criptografia entre trabalhadores novamente.
Como habilitar o Lake Formation para trabalhos no Spark
Para habilitar o Lake Formation em trabalhos individuais do Spark, defina spark.emr-serverless.lakeformation.enabled como verdadeiro ao usar spark-submit.
--conf spark.emr-serverless.lakeformation.enabled=true
Permissões do IAM do perfil de runtime do trabalho
As permissões do Lake Formation controlam o acesso aos recursos do AWS Glue Data Catalog, aos locais do Amazon S3 e aos dados subjacentes nesses locais. As permissões do IAM controlam o acesso às APIs e aos recursos do Lake Formation e do AWS Glue. Embora você possa ter a permissão do Lake Formation para acessar uma tabela no Data Catalog (SELECT), a operação falhará se você não tiver a permissão do IAM na operação de API glue:Get*.
Confira a seguir um exemplo de política de como fornecer permissões do IAM para acesso a um script no S3, upload de logs no S3, permissões da API do AWS Glue e permissão para acessar o Lake Formation.
Configuração de permissões do Lake Formation para perfil de runtime do trabalho
Primeiro, registre a localização da tabela do Hive no Lake Formation. Em seguida, crie permissões para o perfil de runtime do trabalho na tabela desejada. Para obter mais detalhes sobre Lake Formation, consulte O que éAWS Lake Formation? no Guia do AWS Lake Formation desenvolvedor.
Depois de configurar as permissões do Lake Formation, envie trabalhos do Spark no Amazon EMR Sem Servidor. Para obter mais informações sobre os trabalhos do Spark, consulte os Exemplos do Spark.
Envio da execução de um trabalho
Depois de concluir a configuração das concessões do Lake Formation, você pode enviar trabalhos do Spark no EMR Sem Servidor. A seção a seguir mostra exemplos de como configurar e enviar propriedades de execução de trabalho.
Requisitos de permissão
Tabelas não registradas emAWS Lake Formation
Para tabelas não registradasAWS Lake Formation, a função de tempo de execução do trabalho acessa o AWS Glue Data Catalog e os dados da tabela subjacente no Amazon S3. Isso exige que a função de tempo de execução do trabalho tenha as permissões apropriadas do IAM para as operações do AWS Glue e do Amazon S3.
Tabelas cadastradas emAWS Lake Formation
Para tabelas registradas comAWS Lake Formation, a função de tempo de execução do trabalho acessa os metadados do AWS Glue Data Catalog, enquanto as credenciais temporárias fornecidas pela Lake Formation acessam os dados da tabela subjacente no Amazon S3. As permissões do Lake Formation necessárias para executar uma operação dependem do AWS Glue Data Catalog e das chamadas de API do Amazon S3 iniciadas pelo trabalho do Spark e podem ser resumidas da seguinte forma:
-
A permissão DESCRIBE permite que a função de tempo de execução leia os metadados da tabela ou do banco de dados no Catálogo de Dados
-
A permissão ALTER permite que a função de tempo de execução modifique os metadados da tabela ou do banco de dados no Catálogo de Dados
-
A permissão DROP permite que a função de tempo de execução exclua metadados da tabela ou do banco de dados do Catálogo de Dados
-
A permissão SELECT permite que a função de tempo de execução leia os dados da tabela do Amazon S3
-
A permissão INSERT permite que a função de tempo de execução grave dados de tabela no Amazon S3
-
A permissão DELETE permite que a função de tempo de execução exclua dados da tabela do Amazon S3
nota
O Lake Formation avalia as permissões preguiçosamente quando um trabalho do Spark chama o AWS Glue para recuperar os metadados da tabela e o Amazon S3 para recuperar os dados da tabela. Trabalhos que usam uma função de tempo de execução com permissões insuficientes não falharão até que o Spark faça uma chamada ao AWS Glue ou ao Amazon S3 que exija a permissão ausente.
nota
Na seguinte matriz de tabela suportada:
-
As operações marcadas como Suportadas usam exclusivamente as credenciais do Lake Formation para acessar os dados das tabelas registradas no Lake Formation. Se as permissões do Lake Formation forem insuficientes, a operação não retornará às credenciais da função de tempo de execução. Para tabelas não registradas no Lake Formation, as credenciais da função de tempo de execução do trabalho acessam os dados da tabela.
-
As operações marcadas como compatíveis com permissões do IAM na localização do Amazon S3 não usam as credenciais do Lake Formation para acessar os dados da tabela subjacente no Amazon S3. Para executar essas operações, a função de tempo de execução do trabalho deve ter as permissões necessárias do Amazon S3 IAM para acessar os dados da tabela, independentemente de a tabela estar registrada no Lake Formation.
