Ajudar a melhorar esta página
Para contribuir com este guia de usuário, escolha o link Editar esta página no GitHub, disponível no painel direito de cada página.
Saiba mais sobre a mudança de zona do Controlador de Recuperação de Aplicações da Amazon (ARC, na sigla em inglês) no Amazon EKS
O Kubernetes tem recursos nativos que permitem que você torne suas aplicações mais resilientes a eventos como a degradação da integridade ou a deficiência de uma zona de disponibilidade (AZ). Ao executar as workloads em um cluster do Amazon EKS, é possível aumentar ainda mais a tolerância a falhas do ambiente e a recuperação da aplicação usando a mudança de zona do Controlador de Recuperação de Aplicações da Amazon (ARC, na sigla em inglês) ou a mudança de zona automática. A mudança de zona do ARC é uma medida temporária que possibilita desviar o tráfego de um recurso de uma AZ comprometida até a expiração ou o cancelamento da mudança de zona. É possível prolongar a mudança de zona, caso seja necessário.
Você pode iniciar uma mudança de zona em um cluster do EKS ou permitir que a AWS realize o deslocamento do tráfego por você ao habilitar a mudança de zona automática. Essa mudança atualiza o fluxo do tráfego de rede leste-oeste em seu cluster para considerar apenas os endpoints de rede para Pods em execução em nós de processamento em AZs íntegras. Além disso, qualquer ALB ou NLB que lide com o tráfego de entrada para aplicações no seu cluster do EKS encaminhará automaticamente o tráfego para destinos nas AZs íntegras. Para os clientes que buscam as metas de disponibilidade mais altas, no caso de uma AZ ser prejudicada, pode ser importante poder desviar todo o tráfego da AZ afetada até que ela se recupere. Para isso, você também pode habilitar um ALB ou NLB com mudança de zona do ARC.
Noções básicas sobre o fluxo de tráfego de rede leste-oeste entre pods
O diagrama a seguir ilustra dois exemplos de workloads: Pedidos e Produtos. O objetivo desse exemplo é mostrar como as workloads e os pods em diferentes AZs se comunicam.
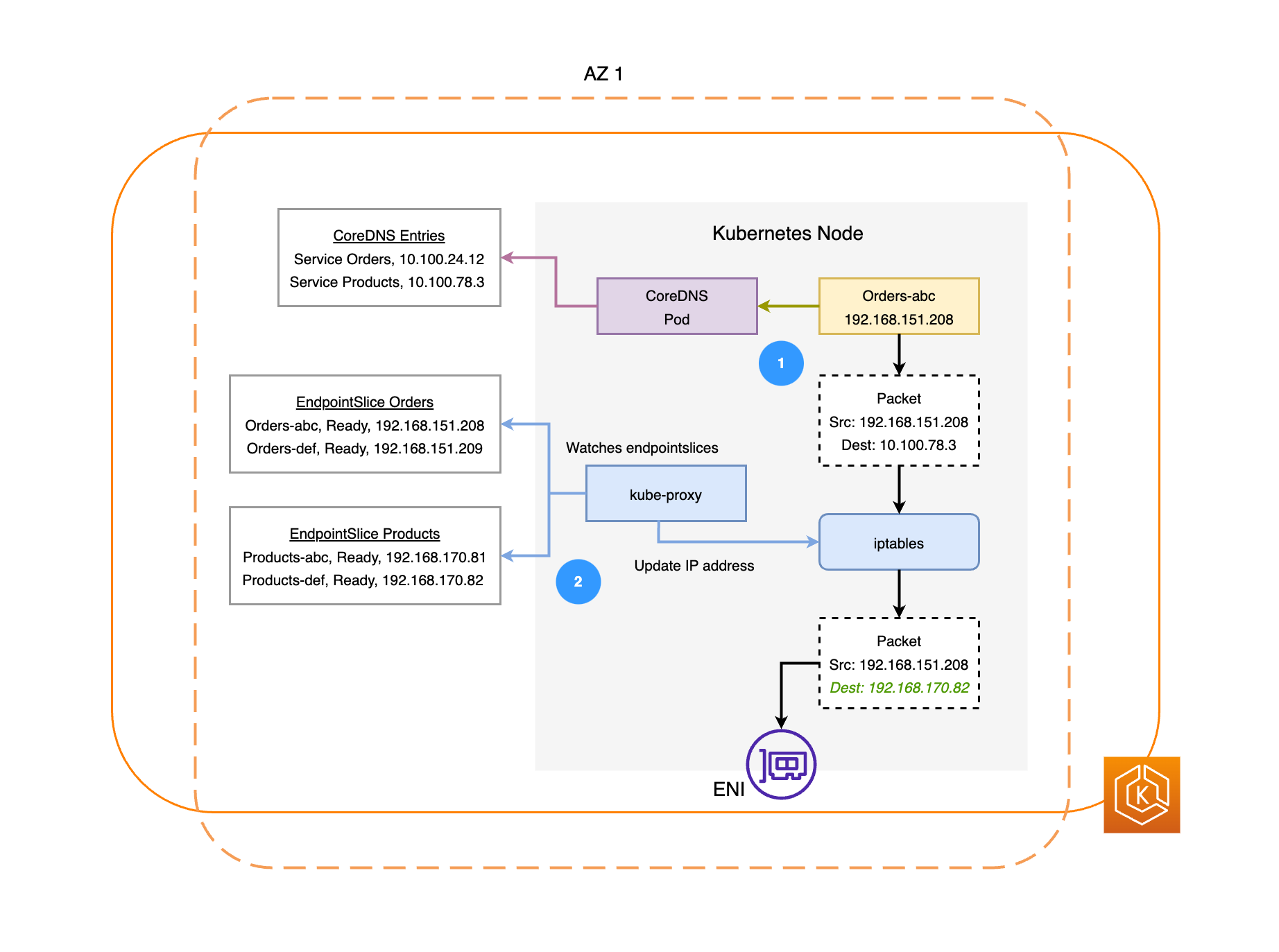
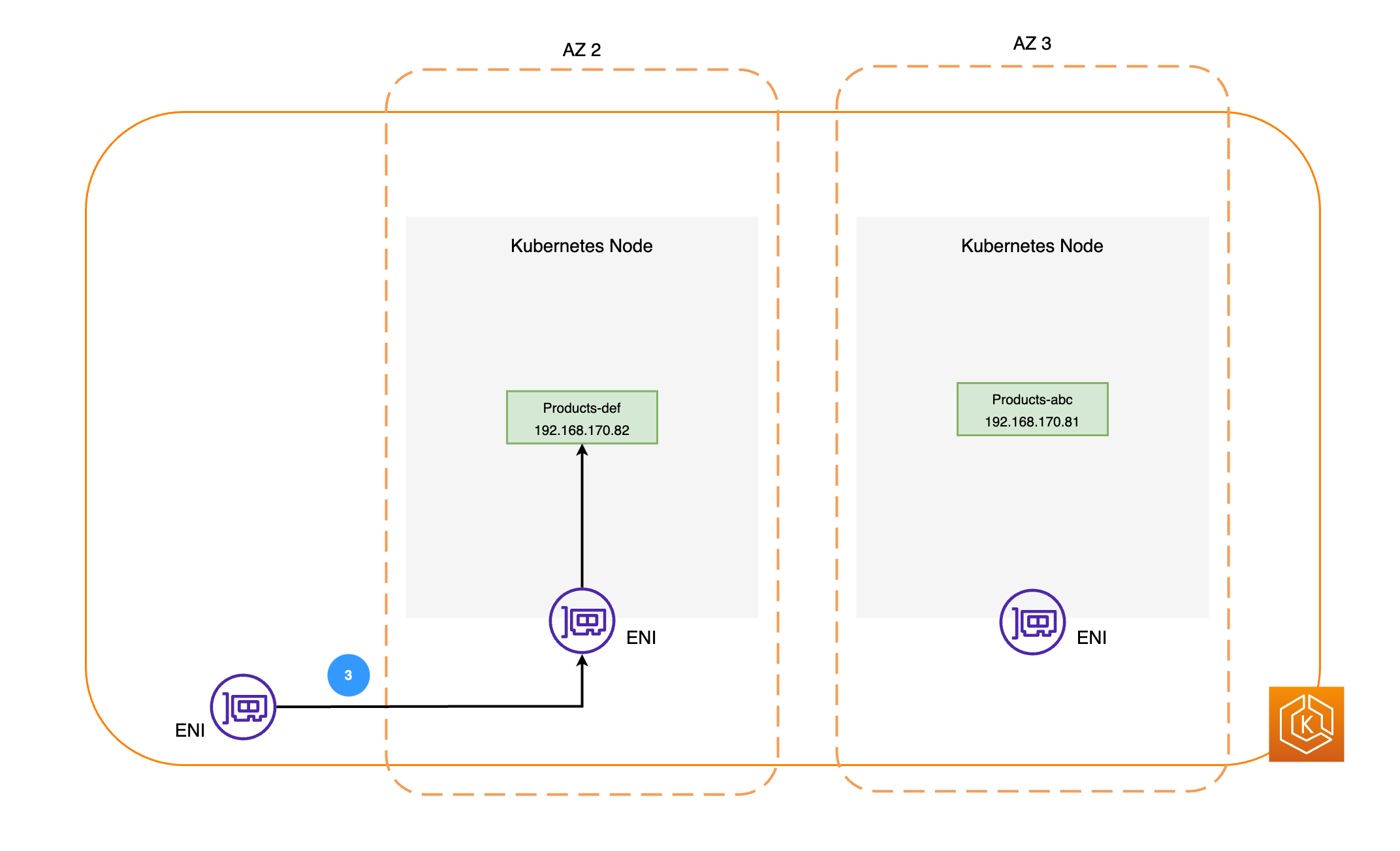
-
Para que o serviço Orders estabeleça comunicação com o Products, ele precisa primeiro resolver o nome de DNS do serviço de destino. O Orders se comunica com o CoreDNS para buscar o endereço IP virtual (IP do cluster) desse serviço. Após o Orders resolver o nome do serviço Products, ele envia o tráfego para esse endereço IP de destino.
-
O kube-proxy é executado em cada nó do cluster e monitora continuamente os EndpointSlices
para os serviços. Quando um serviço é criado, um EndpointSlice é criado e gerenciado em segundo plano pelo controlador de EndpointSlice. Cada EndpointSlice conta com uma lista ou com uma tabela de endpoints que contém um subconjunto de endereços de pods, juntamente com os nós em que eles estão sendo executados. O kube-proxy configura regras de roteamento para cada um desses endpoints de Pod usando iptablesnos nós. O kube-proxy também é responsável por uma forma básica de balanceamento de carga, redirecionando o tráfego destinado ao endereço IP do cluster de um serviço para que seja enviado diretamente ao endereço IP de um pod. O kube-proxy realiza esse processo ao reescrever o endereço IP de destino na conexão de saída. -
Em seguida, os pacotes de rede são enviados ao pod do Products na AZ 2 por meio das ENIs nos respectivos nós, como ilustrado no diagrama anterior.
Noções básicas sobre a mudança de zona do ARC no Amazon EKS
Se houver um comprometimento de uma AZ em seu ambiente, você poderá iniciar uma mudança de zona para o ambiente do cluster do EKS. Como alternativa, é possível permitir que a AWS gerencie o deslocamento do tráfego para você com a mudança de zona automática. Com a mudança de zona automática, a AWS monitora a integridade geral das AZs e responde a um possível comprometimento de AZ mudando automaticamente o tráfego para fora da AZ comprometida no ambiente de cluster.
Após habilitar a mudança de zona com o ARC em seu cluster do Amazon EKS, você pode iniciar uma mudança de zona ou habilitar a mudança de zona automática pelo console do ARC, pela AWS CLI ou pelas APIs de mudança de zona e de mudança de zona automática. Durante uma mudança de zona do EKS, as seguintes ações são realizadas automaticamente:
-
Todos os nós da AZ comprometida serão isolados. Isso impede que o Agendador do Kubernetes agende novos pods em nós na AZ não íntegra.
-
Se você estiver usando grupos de nós gerenciados, o rebalanceamento de zonas de disponibilidade será suspenso e o grupo do Auto Scaling será atualizado para garantir que novos nós do plano de dados do EKS sejam iniciados apenas em AZs íntegras.
-
Os nós na AZ não íntegra não serão encerrados, e os pods não são removidos desses nós. Isso garante que, quando uma mudança de zona expirar ou for cancelada, o tráfego possa ser retornado com segurança à AZ para obter capacidade total.
-
O controlador de EndpointSlice identifica todos os endpoints de Pods na AZ comprometida e os remove dos EndpointSlices correspondentes. Isso garantirá que somente os endpoints do pod em AZs íntegras sejam direcionados para receber tráfego de rede. Quando uma mudança de zona for cancelada ou expirar, o controlador de EndpointSlice atualizará os EndpointSlices para incluir os endpoints da AZ restaurada.
Os diagramas a seguir fornecem uma visão geral de alto nível sobre como a mudança de zona do EKS garante que apenas endpoints de pod íntegros sejam selecionados em seu ambiente de cluster.
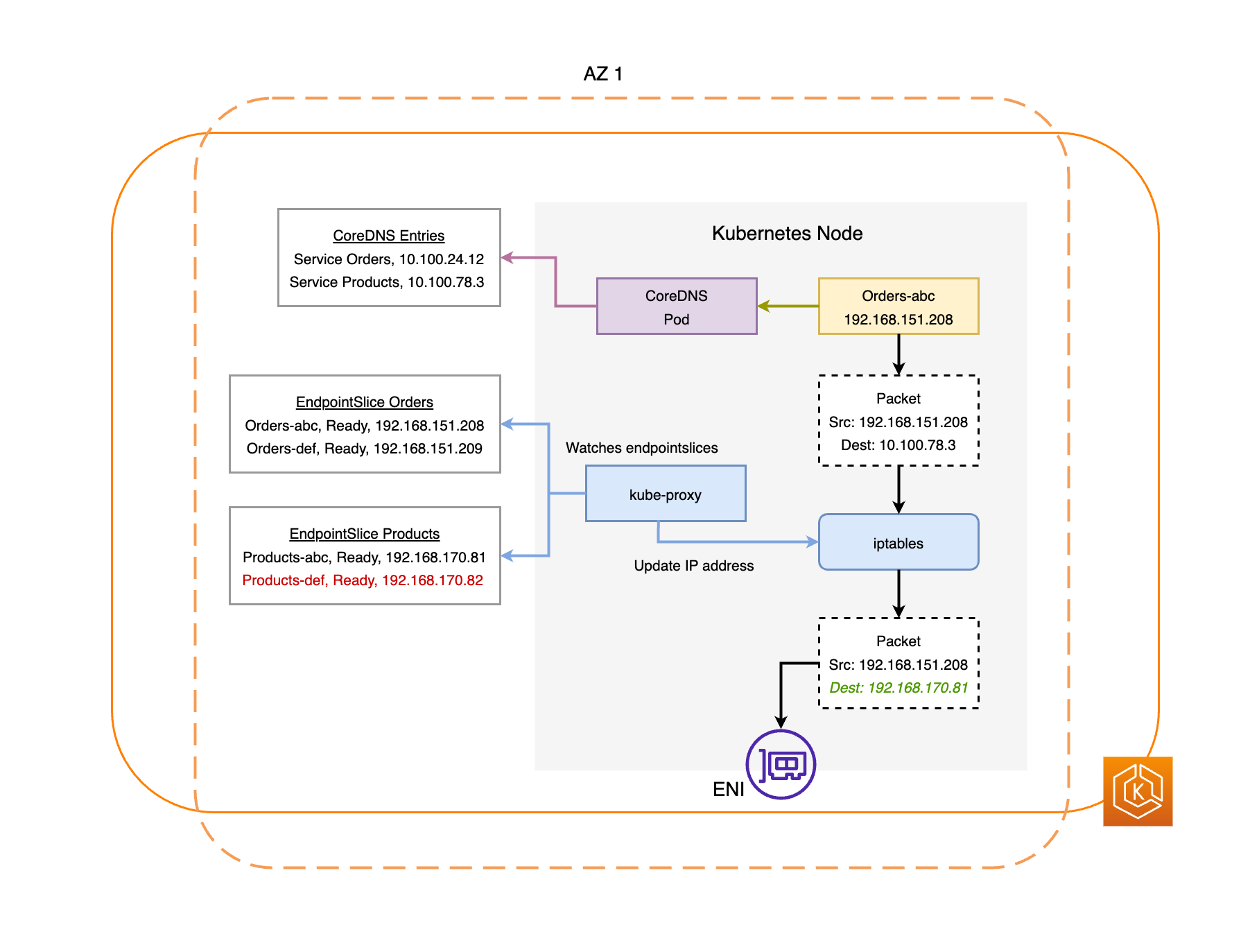
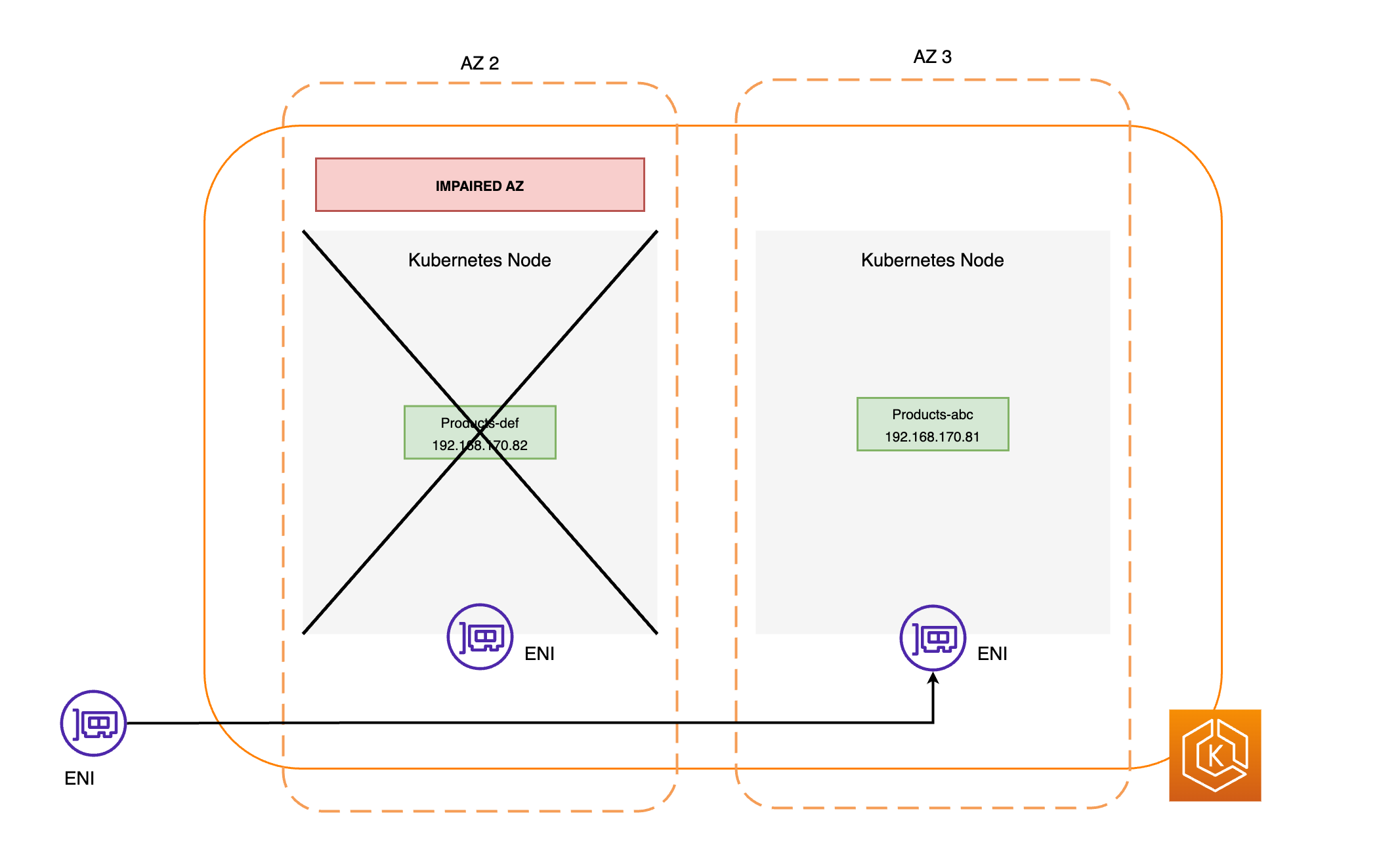
Requisitos de mudança de zona do EKS
Para garantir o funcionamento da mudança de zona no EKS, é necessário configurar previamente o ambiente do cluster para que ele seja resiliente ao comprometimento de uma AZ. A seguir, apresentamos uma lista de opções de configuração que ajudam a garantir a resiliência.
-
Provisionar os nós de processamento do seu cluster em várias AZs
-
Provisionamento de capacidade de computação suficiente para atender à remoção de uma única AZ.
-
Escalabilidade prévia dos pods em todas as AZs, incluindo o CoreDNS.
-
Distribuição de várias réplicas de pods entre todas as AZs, auxiliando na garantia de que você ainda terá capacidade de escalabilidade suficiente após a mudança de zona de uma AZ individual.
-
Colocalização de pods interdependentes ou relacionados na mesma AZ.
-
Verificação se o ambiente de cluster opera conforme previsto na ausência de uma AZ, ao iniciar manualmente uma mudança de zona de uma AZ. Como alternativa, você pode habilitar a mudança de zona automática e contar com as execuções de teste de mudança de zona automática. Realizar testes com mudanças de zona manuais ou de prática não é obrigatório para que a mudança de zona funcione no EKS, mas é uma prática fortemente recomendada.
Provisionamento de nós de processamento do EKS em várias zonas de disponibilidade
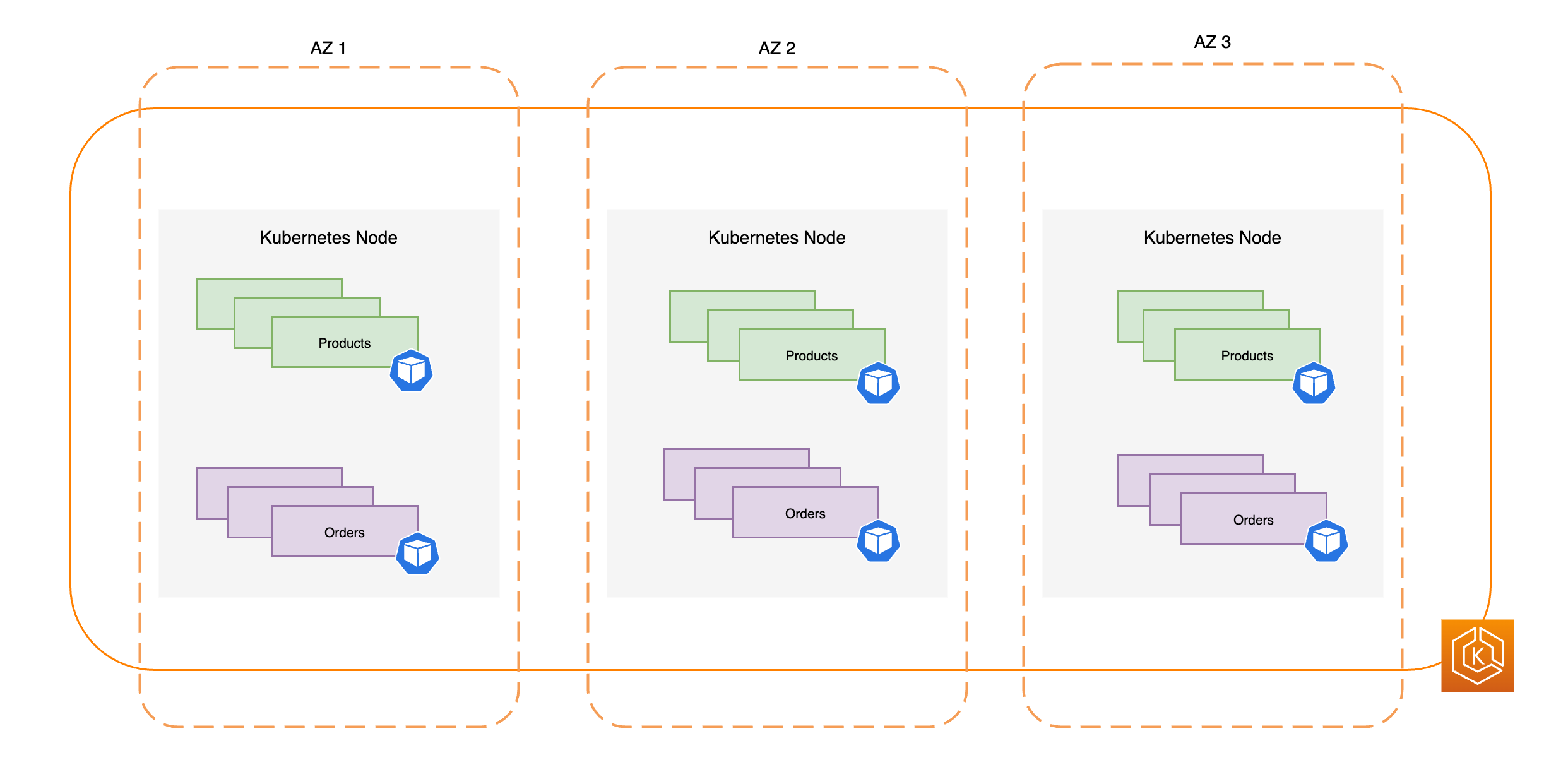
As regiões da AWS contam com diversos locais distintos que abrigam data centers físicos, conhecidos como zonas de disponibilidade (AZs). As AZs são projetadas para serem fisicamente isoladas umas das outras a fim de evitar impactos simultâneos que possam afetar toda uma região. Ao realizar o provisionamento de um cluster do EKS, a recomendação é implantar os nós de processamento por diversas AZs em uma região. Essa prática contribui para que o ambiente de cluster seja mais resiliente em caso do comprometimento de uma única AZ, permitindo que você mantenha a alta disponibilidade das aplicações em execução nas demais AZs. Quando você inicia uma mudança de zona para fora da AZ impactada, a rede interna do cluster do ambiente do EKS é atualizada automaticamente para usar apenas AZs íntegras, para ajudar a manter a alta disponibilidade do cluster.
Garantir que você tenha uma configuração multi-AZ no ambiente do EKS aumenta a confiabilidade geral do sistema. Contudo, ambientes multi-AZ influenciam o processamento e a transferência de dados das aplicações, resultando em um impacto nos custos de rede do ambiente. Especificamente, o tráfego de saída frequente entre zonas (ou seja, o tráfego distribuído entre AZs) pode ter um grande impacto nos custos relacionados à rede. É possível aplicar estratégias diferentes para controlar a quantidade de tráfego entre zonas entre os pods no cluster do EKS e reduzir os custos associados. Para obter mais informações sobre como otimizar os custos de rede ao executar ambientes do EKS de alta disponibilidade, consulte estas práticas recomendadas
O diagrama apresentado a seguir ilustra um ambiente do EKS de alta disponibilidade com três AZs íntegras.
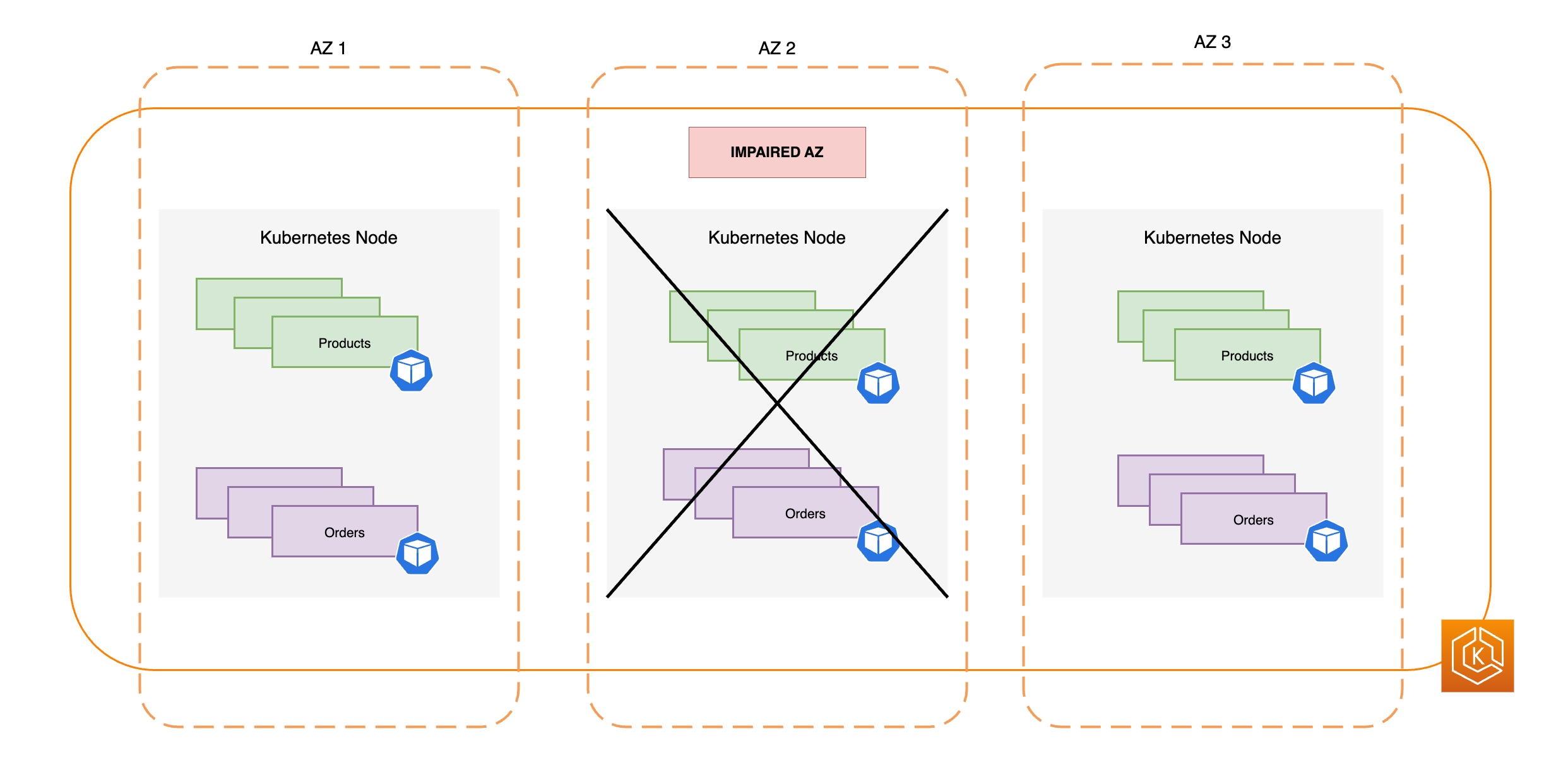
O diagrama abaixo demonstra como um ambiente do EKS com três AZs é resiliente ao comprometimento de uma das zonas, mantendo a alta disponibilidade por meio das duas AZs íntegras remanescentes.
Provisionamento de capacidade de computação suficiente para resistir à remoção de uma única zona de disponibilidade
A fim de otimizar a utilização de recursos e os custos da infraestrutura de computação no plano de dados do EKS, recomenda-se garantir a escalabilidade da capacidade de computação para que ela esteja alinhada às necessidades das workloads. No entanto, se todos os seus nós de processamento estiverem com capacidade máxima, você dependerá da adição de novos nós de processamento ao plano de dados do EKS antes que novos pods da workload possam ser agendados. Ao executar workloads críticas, geralmente é uma boa prática operar com capacidade redundante ativa para lidar com cenários como aumentos repentinos de carga e problemas de integridade dos nós. Ao optar pelo uso da mudança de zona, você está planejando a remoção da capacidade de uma zona de disponibilidade completa no caso do comprometimento. Isso implica ajustar a capacidade redundante de computação para que haja escalabilidade suficiente para suportar a carga, mesmo que uma das AZs não esteja ativa.
Ao escalar os recursos de computação, a inclusão de novos nós no plano de dados do EKS não é instantânea e requer um tempo de provisionamento. Isso pode ter implicações na performance em tempo real e na disponibilidade das aplicações, especialmente no caso do comprometimento da zona. O ambiente do EKS deve conseguir suportar a carga de trabalho caso uma AZ fique indisponível, sem comprometer a experiência dos seus usuários finais ou clientes. Isso significa minimizar ou eliminar o atraso entre o momento em que um novo pod é necessário e o momento em que ele é efetivamente agendado em um nó de processamento.
Além disso, em casos de comprometimento de uma zona, o objetivo deve ser evitar limitações de capacidade de computação que possam impedir que novos nós sejam integrados ao plano de dados do EKS nas zonas de disponibilidade que estiverem operando normalmente.
Para reduzir o risco desses possíveis impactos negativos, é recomendável provisionar capacidade de computação extra em alguns nós de processamento em cada AZ. Ao fazer isso, o Agendador do Kubernetes dispõe de capacidade disponível antecipadamente para novas alocações de pods, o que é especialmente importante quando você perde uma das AZs no ambiente.
Execução e distribuição de diversas réplicas de pods entre as zonas de disponibilidade
O Kubernetes permite que você pré-escale suas workloads executando várias instâncias (réplicas de pod) de uma única aplicação. Executar diversas réplicas de pods para uma aplicação elimina pontos únicos de falha e aumenta a performance geral ao reduzir a sobrecarga de recursos em uma única réplica. No entanto, para garantir alta disponibilidade e tolerância a falhas aprimorada para as aplicações, recomendamos que você execute várias réplicas da aplicação e distribua essas réplicas por diferentes domínios de falha, também chamados de domínios de topologia. Os domínios de falha neste cenário são as zonas de disponibilidade. Ao utilizar restrições de distribuição de topologia
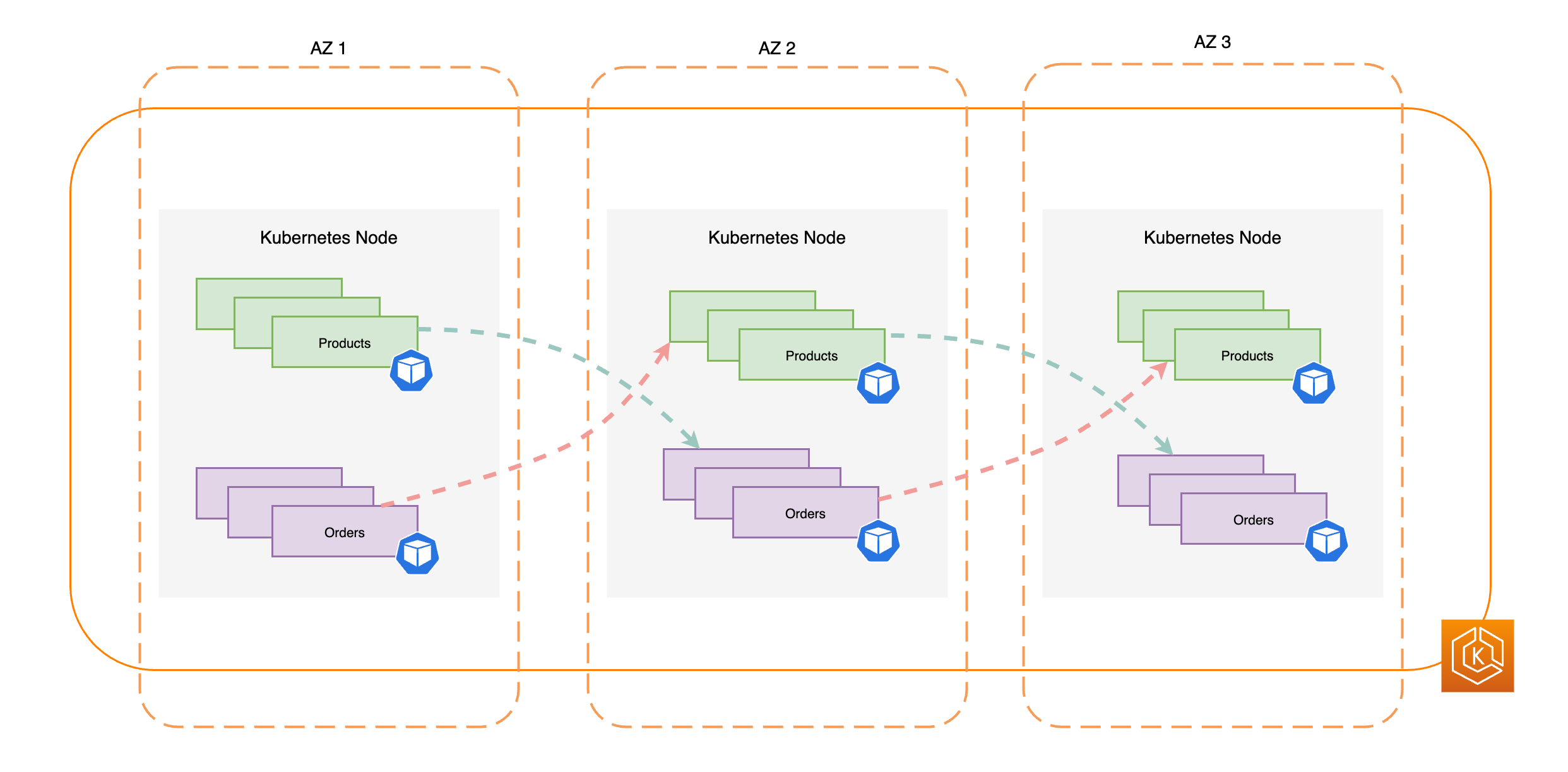
O diagrama apresentado a seguir ilustra um ambiente do EKS com fluxo de tráfego leste-oeste quando todas as AZs estão íntegras.
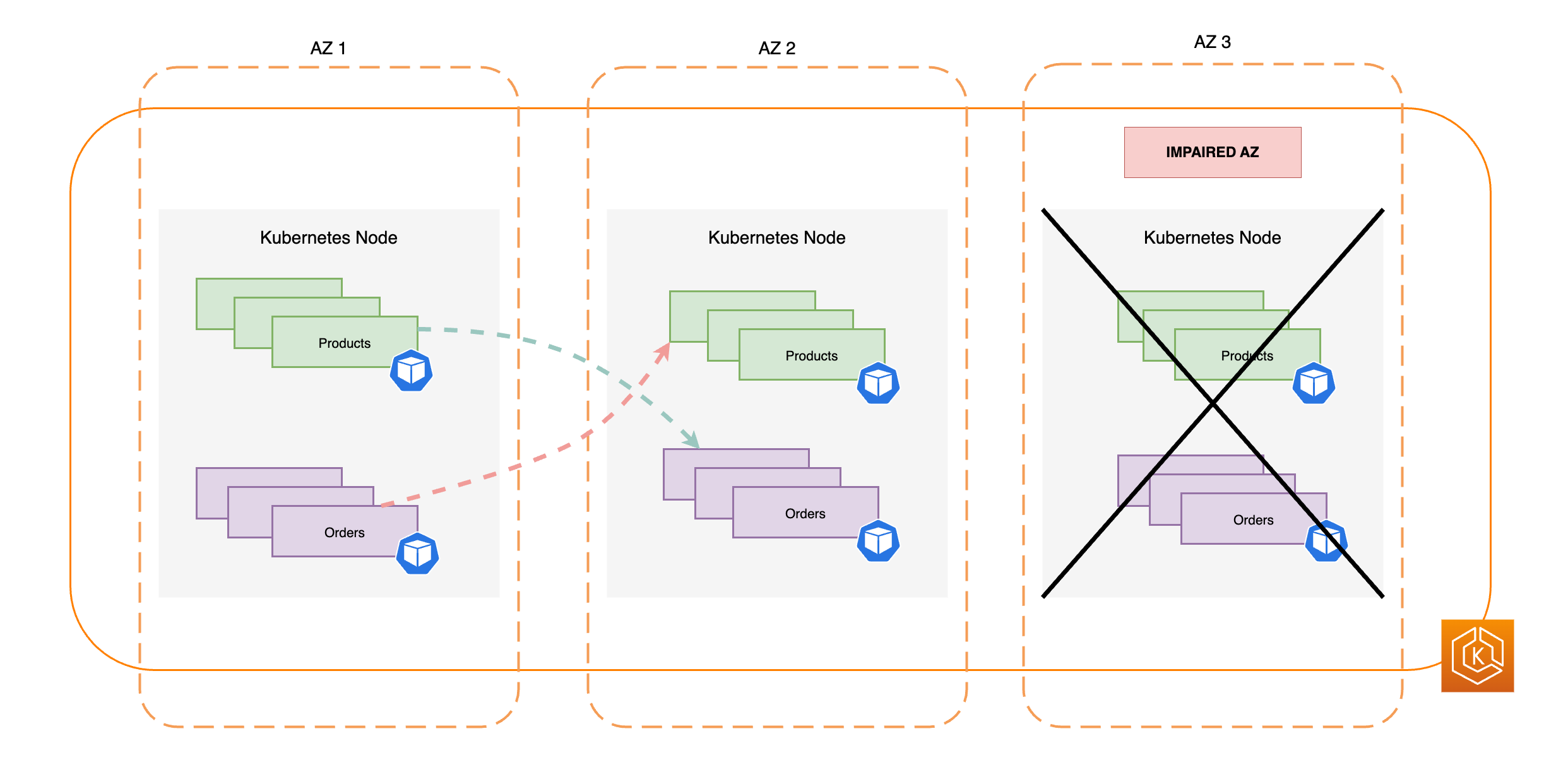
O diagrama abaixo demonstra um ambiente do EKS com fluxo de tráfego leste-oeste em um cenário de falha em uma única AZ e início da mudança de zona por parte do usuário.
O trecho de código a seguir é um exemplo de como configurar a workload com várias réplicas no Kubernetes.
apiVersion: apps/v1 kind: Deployment metadata: name: orders spec: replicas: 9 selector: matchLabels: app: orders template: metadata: labels: app: orders tier: backend spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: orders
Mais importante ainda, você deve executar várias réplicas do software do servidor de DNS (CoreDNS/kube-dns) e aplicar restrições de distribuição de topologia semelhantes, caso elas não estejam configuradas por padrão. Essa prática ajuda a assegurar que, se houver um comprometimento de uma única AZ, você tenha pods de DNS suficientes em AZs íntegras para continuar processando as solicitações de descoberta de serviços para outros pods em comunicação no cluster. O complemento do CoreDNS para EKS conta com configurações padrão para os pods do CoreDNS que garantem que, se houver nós disponíveis em diversas AZs, eles sejam distribuídos entre as zonas de disponibilidade do cluster. Se desejar, você pode substituir essas definições padrão por configurações personalizadas.
Ao instalar o CoreDNS usando o HelmreplicaCount no arquivo values.yamltopologySpreadConstraints no mesmo arquivo values.yaml. O trecho de código a seguir ilustra como configurar o CoreDNS para este propósito.
CoreDNS Helm values.yaml
replicaCount: 6 topologySpreadConstraints: - maxSkew: 1 topologyKey: topology.kubernetes.io/zone whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: k8s-app: kube-dns
Caso ocorra o comprometimento de uma AZ, é possível absorver o aumento de carga nos pods do CoreDNS ao usar um sistema de ajuste de escala automático para o CoreDNS. A quantidade de instâncias de DNS necessária dependerá do volume de workloads em execução no cluster. O CoreDNS é limitado pela CPU, o que permite que ele seja escalado com base no uso de processamento, por meio do autoescalador de pod horizontal (HPA, na sigla em inglês)
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: coredns namespace: default spec: maxReplicas: 20 minReplicas: 2 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: coredns targetCPUUtilizationPercentage: 50
Como alternativa, o EKS pode gerenciar o ajuste de escala automático da implantação do CoreDNS na versão do complemento do CoreDNS para o EKS. Esse autoscaler do CoreDNS monitora continuamente o estado do cluster, incluindo o número de nós e núcleos de CPU. Com base nessas informações, o controlador ajusta dinamicamente o número de réplicas da implantação do CoreDNS em um cluster do EKS.
Para habilitar a configuração de ajuste de escala automático no complemento do CoreDNS para EKS, use a seguinte definição de configuração:
{ "autoScaling": { "enabled": true } }
Você também pode usar o DNS NodeLocal
Colocalização de pods interdependentes na mesma zona de disponibilidade
Geralmente, as aplicações têm workloads distintas que precisam se comunicar entre si para concluir um processo de ponta a ponta com êxito. Caso essas aplicações distintas estejam distribuídas em várias AZs e não sejam alocadas na mesma zona, um problema em apenas uma dessas AZs poderá comprometer todo o processo de ponta a ponta. Por exemplo, se a Aplicação A tiver várias réplicas nas zonas de disponibilidade 1 e 2, mas a Aplicação B tiver todas as suas réplicas na zona de disponibilidade 3, a perda da zona 3 afetará os processos de ponta a ponta entre as duas workloads, Aplicação A e Aplicação B. Se você combinar restrições de distribuição de topologia com afinidade de pods, poderá aumentar a resiliência da aplicação distribuindo os pods por todas as zonas de disponibilidade. Além disso, essa definição estabelece uma conexão entre determinados pods para assegurar que sejam alocados no mesmo local.
Com regras de afinidade de pod
apiVersion: apps/v1 kind: Deployment metadata: name: products namespace: ecommerce labels: app.kubernetes.io/version: "0.1.6" spec: serviceAccountName: graphql-service-account affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname"
O diagrama apresentado a seguir mostra vários pods que foram alocados no mesmo local, no mesmo nó, com as regras de afinidade de pods.
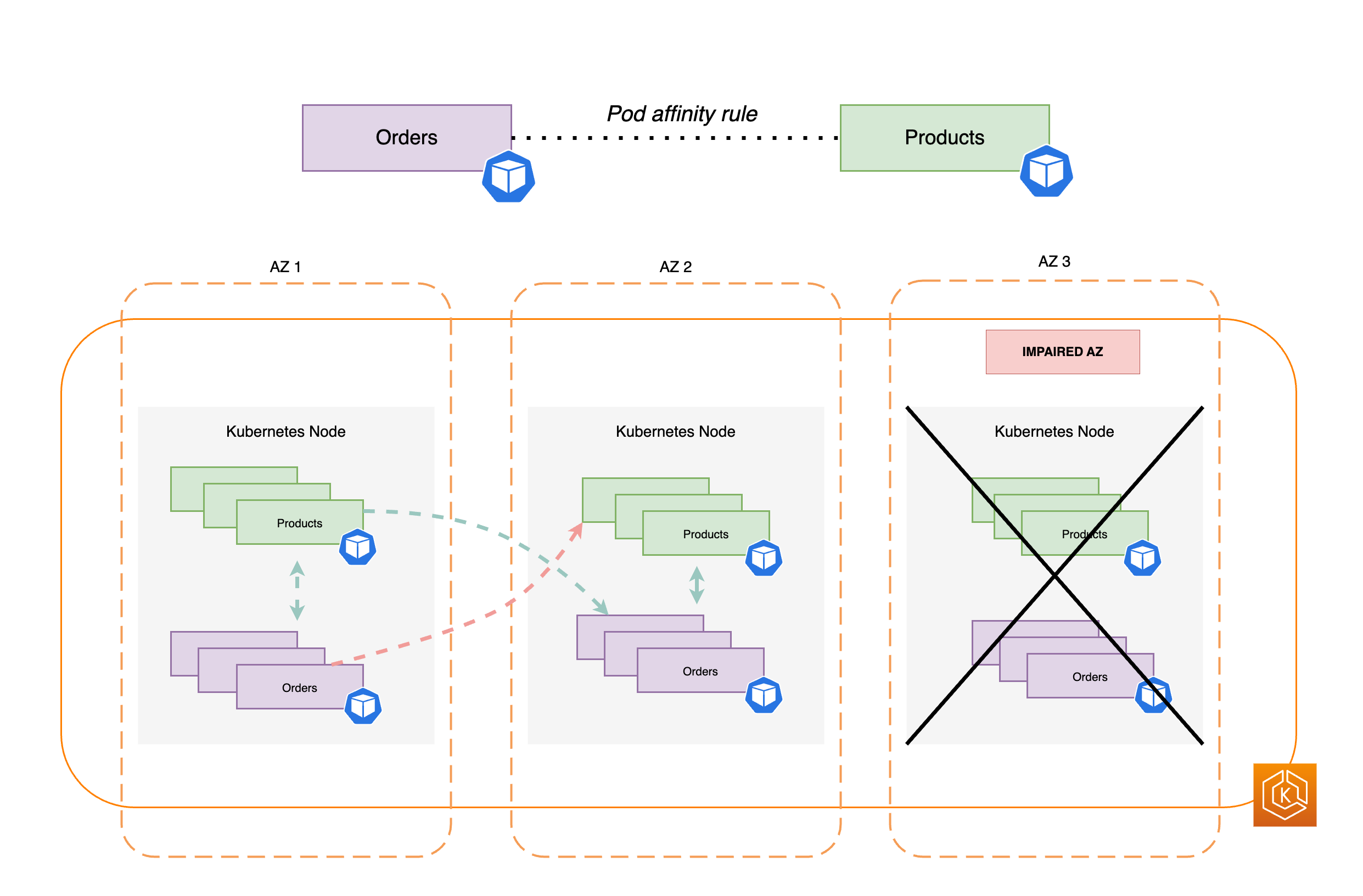
Teste para validar se o ambiente de cluster consegue lidar com a perda de uma AZ
Após concluir os requisitos descritos nas seções anteriores, a próxima etapa consiste em testar se você conta com capacidade de computação e de workload suficientes para lidar com a perda de uma AZ. Isso pode ser feito ao iniciar manualmente uma mudança de zona no EKS. Como alternativa, você pode habilitar a mudança de zona automática e configurar execuções práticas, que também verificam se as aplicações funcionam conforme o esperado com uma AZ a menos no ambiente do cluster.
Perguntas frequentes
Por que devo usar esse recurso?
Ao usar a mudança de zona do ARC ou a mudança de zona automática no cluster do EKS, você pode manter melhor a disponibilidade das aplicações Kubernetes automatizando o processo de recuperação rápida de deslocamento do tráfego de rede no cluster para longe de uma AZ afetada. Com o ARC, é possível evitar etapas extensas e complexas que podem resultar em um período de recuperação prolongado durante eventos de AZ com falhas.
Como esse recurso funciona com outros serviços do AWS?
O EKS se integra ao ARC, que fornece a interface principal para você realizar operações de recuperação na AWS. Para garantir que o tráfego dentro do cluster seja direcionado corretamente para fora de uma AZ comprometida, o EKS faz alterações na lista de endpoints de rede dos pods que estão em execução no plano de dados do Kubernetes. Se você estiver usando o Elastic Load Balancing para direcionar tráfego externo para o cluster, é possível registrar os balanceadores de carga no ARC e iniciar uma mudança de zona neles para evitar que o tráfego seja enviado para a AZ degradada. Além disso, a mudança de zona é compatível com grupos do Amazon EC2 Auto Scaling criados por grupos de nós gerenciados do EKS. Para impedir que uma AZ degradada seja usada para criar novos pods do Kubernetes ou para iniciar novos nós, o EKS exclui a AZ comprometida dos grupos do Auto Scaling.
Como esse recurso é diferente das proteções padrão do Kubernetes?
Esse recurso funciona em conjunto com diversas proteções nativas do Kubernetes que ajudam na resiliência das aplicações dos clientes. Você pode configurar a prontidão do pod e as sondas de atividade que decidem quando um pod deve receber tráfego. Se essas sondas falharem, o Kubernetes retira esses pods da lista de destinos de um serviço, e o tráfego não é mais direcionado ao pod. Embora isso seja útil, não é simples para os clientes configurar essas verificações de integridade de modo que elas falhem garantidamente quando uma AZ estiver degradada. O recurso de mudança de zona do ARC oferece uma camada adicional de segurança que ajuda a isolar completamente uma AZ degradada quando as proteções nativas do Kubernetes não foram suficientes. Além disso, a mudança de zona fornece um método simples para verificar a prontidão operacional e a resiliência da arquitetura.
A AWS pode iniciar uma mudança de zona em meu nome?
Sim, se você quiser uma maneira totalmente automatizada de usar a mudança de zona do ARC, poderá habilitar a mudança de zona automática do ARC. Com a mudança de zona automática, você pode contar com a AWS para monitorar a integridade das AZs do cluster do EKS e iniciar automaticamente uma mudança de zona quando o comprometimento de uma AZ for detectado.
O que acontecerá se eu usar esse recurso e meus nós de processamento e workloads não forem pré-escalonados?
Caso não tenha escalado os recursos antecipadamente e precise provisionar nós ou pods adicionais durante uma mudança de zona, a recuperação do sistema poderá sofrer atrasos. O processo de adição de novos nós ao plano de dados do Kubernetes demora algum tempo, o que pode afetar a performance em tempo real e a disponibilidade das aplicações, especialmente quando há o comprometimento de uma AZ. Além disso, durante o comprometimento de uma AZ, pode haver uma restrição de capacidade de computação que impeça a inclusão de nós recém-requeridos nas AZs que estão operando normalmente.
Se as workloads não estiverem com recursos escalados antecipadamente e distribuídos por todas as AZs do cluster, um comprometimento de zona poderá afetar a disponibilidade de uma aplicação que esteja sendo executada apenas em nós de processamento na AZ impactada. Para reduzir o risco de uma interrupção completa da disponibilidade da sua aplicação, o EKS tem uma proteção contra falhas para que o tráfego seja enviado aos endpoints do Pod em uma zona afetada se essa workload tiver todos os seus endpoints na AZ não íntegra. Contudo, é altamente recomendável escalar recursos antecipadamente e distribuir aplicações entre todas as AZs, garantindo que o serviço mantenha a disponibilidade se houver falha em uma das zonas.
Como isso funciona caso eu esteja executando uma aplicação com estado?
Se você estiver executando uma aplicação com estado, deverá avaliar a tolerância a falhas com base no caso de uso e na arquitetura. Caso use um padrão ou uma arquitetura com ativo e em espera, pode haver situações em que o recurso ativo esteja em uma AZ comprometida. No nível da aplicação, se o recurso em espera não for devidamente ativado, você poderá enfrentar problemas com a aplicação. Você também pode enfrentar problemas quando novos pods do Kubernetes forem iniciados em AZs íntegras, já que esses pods não conseguirão se conectar aos volumes persistentes vinculados à AZ comprometida.
Esse recurso funciona com o Karpenter?
O suporte para o Karpenter está disponível com a mudança de zona e a mudança de zona automática do ARC no EKS na versão 1.12 ou versões posteriores do Karpenter
Esse recurso funciona com o EKS Fargate?
Esse recurso não funciona com o EKS Fargate. Por padrão, quando o EKS Fargate reconhecer um evento de integridade de zona, os pods preferirão ser executados nas outras AZs.
O ambiente de gerenciamento do Kubernetes gerenciado pelo EKS será afetado?
Não, por padrão, o Amazon EKS executa e dimensiona o ambiente de gerenciamento do Kubernetes em várias AZs para garantir alta disponibilidade. A mudança de zona e a mudança de zona automática do ARC operam somente no plano de dados do Kubernetes.
Há algum custo associado a esse novo recurso?
Você pode usar a mudança de zona do ARC e a mudança de zona automática no seu cluster do EKS sem custo adicional. No entanto, você continuará pagando pelas instâncias provisionadas. Portanto, recomendamos que realize a escala antecipada de recursos para o plano de dados do Kubernetes antes de utilizá-los. Você deve considerar um equilíbrio entre o custo e a disponibilidade da aplicação.
Recursos adicionais
