Ajudar a melhorar esta página
Para contribuir com este guia de usuário, escolha o link Editar esta página no GitHub, disponível no painel direito de cada página.
Início rápido: inferência de LLM de alto throughput usando vLLM no Amazon EKS
Introdução
Este guia de início rápido fornece um passo a passo para implantar grandes modelos de linguagem (LLMs) no Amazon EKS usando vLLM e GPUs para aplicações de inferência textual em tempo real.
A solução emprega o Amazon EKS para orquestração de contêiner e o vLLM para disponibilizar modelos de forma eficiente, permitindo o desenvolvimento de aplicações baseadas em IA escaláveis com aceleração por GPU e inferência de alto throughput. Para demonstração, utiliza-se o modelo Llama 3.1 8B Instruct, mas é possível implantar qualquer outro LLM compatível com o vLLM (consulte a documentação do vLLM
Arquitetura do vLLM no EKS

Ao concluir este procedimento, você terá um endpoint de inferência vLLM otimizado para throughput e baixa latência e poderá interagir com um modelo do Llama por meio de uma aplicação frontend de chat, demonstrando um caso de uso típico para assistentes de chatbot e outras aplicações baseadas em LLMs.
Para obter orientação adicional e recursos avançados de implantação, consulte nosso Guia de práticas recomendadas do EKS para workloads de IA/ML e a página AI on EKS inference charts
Antes de começar
Antes de começar, verifique se você conta com:
-
Um cluster do Amazon EKS com os seguintes componentes principais: grupos de nós do Karpenter usando instâncias do EC2 das famílias G5 ou G6, o plug-in de dispositivo da NVIDIA instalado nos nós de processamento com a GPU habilitada e o driver CSI para o ponto de montagem do S3 instalado. Para criar essa configuração básica, siga as etapas apresentadas em Guia de configuração de cluster do melhores práticas para inferência em tempo real no Amazon EKS até concluir a Etapa 4.
-
Uma conta do Hugging Face. Para se cadastrar, acesse https://huggingface.co/login.
Configuração do armazenamento de modelos com o Amazon S3
Armazene arquivos grandes de LLM de forma eficiente no Amazon S3, separando o armazenamento dos recursos de computação. Essa abordagem agiliza as atualizações de modelos, reduz os custos e simplifica o gerenciamento em ambientes de produção. O S3 garante armazenamento confiável de arquivos massivos, e a integração com Kubernetes, usando o driver CSI para o ponto de montagem, permite que os pods acessem os modelos como se fossem armazenamento local, sem necessidade de downloads demorados a cada inicialização. Siga estas etapas para criar um bucket do S3, fazer upload de um LLM e montá-lo como um volume no seu contêiner de inferência.
Outras soluções de armazenamento também estão disponíveis no EKS para o armazenamento em cache de modelos, como o EFS e o FSx para Lustre. Para obter mais informações, consulte Práticas recomendadas do EKS.
Definição de variáveis de ambiente
Crie um nome exclusivo para um novo bucket do Amazon S3, que será criado posteriormente neste guia. Uma vez criado, use este mesmo nome de bucket em todas as etapas. Por exemplo:
MY_BUCKET_NAME=model-store-$(date +%s)
Defina variáveis de ambiente e armazene-as em um arquivo:
cat << EOF > .env-quickstart-vllm export BUCKET_NAME=${MY_BUCKET_NAME} export AWS_REGION=us-east-1 export AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text) EOF
Carregue as variáveis de ambiente no seu ambiente de shell. Se você fechar o ambiente de shell atual e abrir um novo, certifique-se de recarregar as variáveis de ambiente usando este mesmo comando:
source .env-quickstart-vllm
Criação de um bucket do S3 para armazenar os arquivos do modelo
Crie um bucket do S3 para armazenar os arquivos do modelo:
aws s3 mb s3://${BUCKET_NAME} --region ${AWS_REGION}
Download do modelo do Hugging Face
O Hugging Face é um dos principais hubs de modelos para acessar modelos de LLM. Para fazer o download do modelo Llama, é necessário aceitar a licença do modelo e configurar a autenticação via token:
-
Para continuar, aceite a licença do modelo Llama 3.1 8B Instruct em https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct.
-
Gere um token de acesso (acesse seu Perfil > Configurações > Tokens de acesso, e, em seguida, crie um novo token usando o tipo Leitura).
Configure uma variável de ambiente usando o token do Hugging Face:
export HF_TOKEN=your_token_here
Instale o pacote pip3, caso ele ainda não esteja presente em seu ambiente. Comando de exemplo no Amazon Linux 2023:
sudo dnf install -y python3-pip
Faça a instalação da CLI do Hugging Face
pip install huggingface-hub
Faça o download do modelo Llama-3.1-8B-Instruct do Hugging Face (que tem aproximadamente 15 GB) usando o sinalizador --exclude para ignorar o formato legado PyTorch e fazer download apenas dos arquivos em formato safetensors otimizado, reduzindo o tamanho do download sem perder compatibilidade com os mecanismos de inferência mais usados:
huggingface-cli download meta-llama/Meta-Llama-3.1-8B-Instruct \ --exclude "original/*" \ --local-dir ./llama-3.1-8b-instruct \ --token $HF_TOKEN
Verifique os arquivos que foram baixados:
$ ls llama-3.1-8b-instruct
A saída esperada deve ser semelhante a essa:
LICENSE config.json model-00002-of-00004.safetensors model.safetensors.index.json tokenizer_config.json README.md generation_config.json model-00003-of-00004.safetensors special_tokens_map.json USE_POLICY.md model-00001-of-00004.safetensors model-00004-of-00004.safetensors tokenizer.json
Upload dos arquivos do modelo
Habilite o AWS Common Runtime (CRT) para melhorar a performance de transferências no S3. O cliente de transferência baseado em CRT garante maior throughput e confiabilidade ao lidar com arquivos de grande porte:
aws configure set s3.preferred_transfer_client crt
Faça o upload do modelo:
aws s3 cp ./llama-3.1-8b-instruct s3://$BUCKET_NAME/llama-3.1-8b-instruct \ --recursive
A saída esperada deve ser semelhante a essa:
... upload: llama-3.1-8b-instruct/tokenizer.json to s3://model-store-1753EXAMPLE/llama-3.1-8b-instruct/tokenizer.json upload: llama-3.1-8b-instruct/model-00004-of-00004.safetensors to s3://model-store-1753890326/llama-3.1-8b-instruct/model-00004-of-00004.safetensors upload: llama-3.1-8b-instruct/model-00002-of-00004.safetensors to s3://model-store-1753890326/llama-3.1-8b-instruct/model-00002-of-00004.safetensors upload: llama-3.1-8b-instruct/model-00003-of-00004.safetensors to s3://model-store-1753890326/llama-3.1-8b-instruct/model-00003-of-00004.safetensors upload: llama-3.1-8b-instruct/model-00001-of-00004.safetensors to s3://model-store-1753890326/llama-3.1-8b-instruct/model-00001-of-00004.safetensors
Configuração de permissões da CSI para o ponto de montagem do S3
O driver CSI para o ponto de montagem do S3 possibilita uma integração nativa entre o Kubernetes e o S3, permitindo que os pods acessem diretamente os arquivos do modelo como se fossem armazenamento local e eliminando a necessidade de cópias locais durante a inicialização do contêiner.
Crie uma política do IAM para permitir que o ponto de montagem do S3 realize a leitura do bucket do S3:
aws iam create-policy \ --policy-name S3BucketAccess-${BUCKET_NAME} \ --policy-document "{\"Version\": \"2012-10-17\", \"Statement\": [{\"Effect\": \"Allow\", \"Action\": [\"s3:GetObject\", \"s3:GetObjectVersion\", \"s3:ListBucket\", \"s3:GetBucketLocation\"], \"Resource\": [\"arn:aws:s3:::${BUCKET_NAME}\", \"arn:aws:s3:::${BUCKET_NAME}/*\"]}]}"
Localize o nome do perfil do IAM utilizado pela CSI para o ponto de montagem do S3 conferindo as anotações da conta de serviço do driver CSI do S3:
ROLE_NAME=$(kubectl get serviceaccount s3-csi-driver-sa -n kube-system -o jsonpath='{.metadata.annotations.eks\.amazonaws\.com/role-arn}' | cut -d'/' -f2)
Anexe a política do IAM ao perfil da CSI para o ponto de montagem do S3:
aws iam attach-role-policy \ --role-name ${ROLE_NAME} \ --policy-arn arn:aws:iam::${AWS_ACCOUNT_ID}:policy/S3BucketAccess-${BUCKET_NAME}
Caso a CSI para o ponto de montagem do S3 não esteja instalada no cluster, siga as etapas de implantação apresentadas em Guia de configuração de cluster do melhores práticas para inferência em tempo real no Amazon EKS.
Montagem do bucket do S3 como um volume do Kubernetes
Crie um volume persistente (PV, na sigla em inglês) e uma solicitação de volume persistente (PVC, na sigla em inglês) para fornecer acesso somente à leitura ao bucket do S3 em diversos pods de inferência. O modo de acesso ReadOnlyMany permite que vários pods acessem simultaneamente os arquivos do modelo, com o driver CSI cuidando da montagem do bucket do S3:
cat <<EOF | envsubst | kubectl apply -f - apiVersion: v1 kind: PersistentVolume metadata: name: model-store spec: storageClassName: "" capacity: storage: 100Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain mountOptions: - region ${AWS_REGION} csi: driver: s3.csi.aws.com volumeHandle: model-store volumeAttributes: bucketName: ${BUCKET_NAME} --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: model-store spec: storageClassName: "" volumeName: model-store accessModes: - ReadOnlyMany resources: requests: storage: 100Gi EOF
Configuração da infraestrutura de GPU
Nós do cluster
Estamos usando o cluster do EKS criado no Guia de configuração de cluster do melhores práticas para inferência em tempo real no Amazon EKS. Este cluster inclui grupos de nós do Karpenter capazes de provisionar nós com GPU e armazenamento suficiente para fazer download da imagem do contêiner vLLM. Se estiver usando um cluster do EKS personalizado, certifique-se de que ele consegue iniciar nós com GPU.
Seleção de instância
A seleção adequada da instância para inferência de LLM requer garantir que a memória disponível da GPU seja suficiente para carregar os pesos do modelo. Os pesos do modelo Llama 3.1 8B Instruct ocupam cerca de 16 GB (tamanho dos arquivos de modelo .safetensor). Portanto, é necessário disponibilizar, pelo menos, essa quantidade de memória para que o processo vLLM realize o carregamento do modelo.
As instâncias G5 do Amazon EC2
Drivers de dispositivos da NVIDIA
Os drivers da NVIDIA fornecem o ambiente de runtime necessário para que os contêineres acessem os recursos da GPU de forma eficiente. Esses drivers permitem a alocação e o gerenciamento de recursos de GPU no Kubernetes, tornando as GPUs disponíveis como recursos que podem ser agendados.
O cluster usa AMIs para o EKS no Bottlerocket, que já incluem todos os drivers e plug-ins da NVIDIA necessários em todos os nós com GPU, permitindo que as workloads em contêineres acessem as GPUs imediatamente, sem necessidade de configurações adicionais. Caso esteja usando outros tipos de nós no EKS, certifique-se de que todos os drivers e os plug-ins necessários estejam devidamente instalados.
Teste da infraestrutura de GPU
Teste as funcionalidades de GPU do cluster executando as etapas abaixo para garantir que os pods possam acessar os recursos da GPU da NVIDIA e sejam agendados corretamente em nós com GPU.
Implante um pod de teste NVIDIA SMI:
cat <<EOF | envsubst | kubectl apply -f - apiVersion: v1 kind: Pod metadata: name: gpu-nvidia-smi-test spec: restartPolicy: OnFailure tolerations: - key: "nvidia.com/gpu" operator: "Exists" effect: "NoSchedule" nodeSelector: role: gpu-worker # Matches GPU NodePool's label containers: - name: cuda-container image: nvidia/cuda:12.9.1-base-ubuntu20.04 command: ["nvidia-smi"] resources: requests: memory: "24Gi" limits: nvidia.com/gpu: 1 EOF
Analise os logs do pod para confirmar que os detalhes da GPU estão listados, de forma semelhante à saída abaixo (não necessariamente o mesmo modelo de GPU):
$ kubectl wait --for=jsonpath='{.status.phase}'=Succeeded pod/gpu-nvidia-smi-test $ kubectl logs gpu-nvidia-smi-test
Wed Jul 30 15:39:58 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 570.172.08 Driver Version: 570.172.08 CUDA Version: 12.9 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA A10G On | 00000000:00:1E.0 Off | 0 | | 0% 30C P8 9W / 300W | 0MiB / 23028MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | No running processes found | +-----------------------------------------------------------------------------------------+
Esta saída mostra que os pods conseguem acessar os recursos de GPU com êxito.
IMPORTANTE: este pod utiliza uma configuração nodeSelector que corresponde aos grupos de nós do Karpenter descritos no Guia de configuração de cluster do melhores práticas para inferência em tempo real no Amazon EKS. Se você estiver usando grupos de nós diferentes, certifique-se de que o pod corresponda corretamente ao nodeSelector e às Tolerations.
Implantação do contêiner de inferência
A pilha de serviço determina tanto a performance quanto as funcionalidades de escalabilidade da infraestrutura de inferência. O vLLM surgiu como uma das principais soluções para implantações em ambientes de produção. A arquitetura do vLLM oferece agrupamento em lotes contínuo de solicitações para processamento dinâmico, otimizações de kernel para inferência mais ágil e gerenciamento eficiente da memória da GPU por meio do PagedAttention. Esses recursos, combinados com uma API REST pronta para uso em produção e suporte a formatos de modelos amplamente utilizados, tornam essa solução uma escolha ideal para implantações de inferência com alta performance.
Seleção da imagem do contêiner de deep learning da AWS
Os contêineres de deep learning da AWS
Nesta implantação, usaremos o AWS DLC para vLLM 0.9, que inclui bibliotecas da NVIDIA e configurações de performance da GPU otimizadas, ajustadas especificamente para a inferência de modelos tipo transformador em instâncias de GPU da AWS.
image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/vllm:0.9-gpu-py312-ec2
Aplicação dos manifestos do vLLM com o Kubernetes
Existem várias formas de implantar o vLLM no EKS. Este guia demonstra a implantação do vLLM usando uma implantação do Kubernetes, que é uma abordagem nativa do Kubernetes e uma forma simples de começar. Para obter opções avançadas de implantação, consulte a documentação do vLLM
Defina os parâmetros de implantação por meio de manifestos do Kubernetes para controlar a alocação de recursos, o posicionamento dos nós, as verificações de integridade, a exposição do serviço, entre outros aspectos. Configure a implantação para executar um pod com GPU usando a imagem do contêiner de deep learning da AWS para vLLM. Defina parâmetros otimizados para a inferência de LLM e exponha o endpoint do vLLM compatível com OpenAPI por meio do serviço AWS Load Balancer:
cat <<EOF | envsubst | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: vllm-inference-app spec: replicas: 1 selector: matchLabels: app: vllm-inference-app template: metadata: labels: app: vllm-inference-app spec: tolerations: - key: "nvidia.com/gpu" operator: "Exists" effect: "NoSchedule" nodeSelector: role: gpu-worker containers: - name: vllm-inference image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/vllm:0.9-gpu-py312-ec2 ports: - containerPort: 8000 env: - name: MODEL_PATH value: "/mnt/models/llama-3.1-8b-instruct" args: - "--model=/mnt/models/llama-3.1-8b-instruct" - "--host=0.0.0.0" - "--port=8000" - "--tensor-parallel-size=1" - "--gpu-memory-utilization=0.9" - "--max-model-len=8192" - "--max-num-seqs=1" readinessProbe: httpGet: path: /health port: 8000 initialDelaySeconds: 30 periodSeconds: 5 timeoutSeconds: 10 resources: limits: nvidia.com/gpu: 1 requests: memory: "24Gi" cpu: "4" ephemeral-storage: "25Gi" # Ensure enough node storage for vLLM container image volumeMounts: - name: models mountPath: /mnt/models readOnly: true volumes: - name: models persistentVolumeClaim: claimName: model-store --- apiVersion: v1 kind: Service metadata: name: vllm-inference-svc annotations: service.beta.kubernetes.io/aws-load-balancer-type: nlb service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing spec: type: LoadBalancer ports: - port: 80 targetPort: 8000 protocol: TCP selector: app: vllm-inference-app EOF
Verifique se o pod do vLLM está no estado Ready 1/1:
kubectl get pod -l app=vllm-inference-app -w
Saída esperada:
NAME READY UP-TO-DATE AVAILABLE AGE vllm-inference-app-65df5fddc8-5kmjm 1/1 1 1 5m
Pode demorar alguns minutos para que a imagem do contêiner seja baixada e o vLLM carregue os arquivos do modelo na memória da GPU. Avance apenas quando o pod estiver nos estados Pronto e Disponível.
Exposição do serviço
Deixe o endpoint de inferência acessível localmente por meio do encaminhamento de portas do Kubernetes, que facilita o desenvolvimento e os testes. Mantenha este comando em execução em uma janela de terminal separada:
export POD_NAME=$(kubectl get pod -l app=vllm-inference-app -o jsonpath='{.items[0].metadata.name}') kubectl port-forward pod/$POD_NAME 8000:8000
O AWS Load Balancer Controller cria automaticamente um Network Load Balancer (NLB) que expõe o endpoint do serviço do vLLM externamente. Para recuperar o endpoint do NLB, execute:
NLB=$(kubectl get service vllm-inference-svc -o jsonpath='{.status.loadBalancer.ingress[0].hostname}')
Ainda não instalou o AWS Load Balancer Controller? Siga as etapas de implantação apresentadas em Direcionar o tráfego da Internet com o AWS Load Balancer Controller.
Execute a inferência
Validação do pod de inferência
Valide a funcionalidade do contêiner de inferência localmente por meio da porta encaminhada. Envie uma solicitação de conexão e confirme que a resposta inclua o código HTTP 200:
$ curl -IX GET "http://localhost:8000/v1/models"
HTTP/1.1 200 OK date: Mon, 13 Oct 2025 23:24:57 GMT server: uvicorn content-length: 516 content-type: application/json
Teste as funcionalidades de inferência e valide a conectividade externa enviando uma solicitação de conclusão para o LLM pelo endpoint do NLB:
curl -X POST "http://$NLB:80/v1/completions" \ -H "Content-Type: application/json" \ -d '{ "model": "/mnt/models/llama-3.1-8b-instruct", "prompt": "Explain artificial intelligence:", "max_tokens": 512, "temperature": 0.7 }'
Este endpoint segue o formato da API OpenAI, tornando-o compatível com aplicações existentes, ao mesmo tempo em que oferece parâmetros configuráveis de geração, como tamanho da resposta e temperatura, para controlar a diversidade da saída.
Execução do aplicativo de chatbot
Para fins de demonstração, este guia executa uma aplicação de chatbot de amostra usando o projeto nextjs-vllm-ui
Execute a interface do chatbot como um contêiner do Docker, mapeando a porta 3000 para o localhost e conectando-se ao endpoint de NLB do vLLM:
docker run --rm \ -p 3000:3000 \ -e VLLM_URL="http://${NLB}:80" \ --name nextjs-vllm-ui-demo \ ghcr.io/yoziru/nextjs-vllm-ui:latest
Abra seu navegador e acesse: http://localhost:3000/
A interface de chat será exibida, permitindo que você interaja com o modelo Llama.
Interface da interface do usuário do chat

Otimização da performance de inferência
Mecanismos de inferência especializados, como o vLLM, oferecem recursos avançados que aumentam significativamente a performance da inferência, incluindo o agrupamento em lotes contínuo, o armazenamento KV eficiente e os mecanismos otimizados de atenção à memória. É possível ajustar os parâmetros de configuração do vLLM para melhorar a performance da inferência, atendendo aos requisitos específicos do seu caso de uso e aos padrões de workloads. A configuração adequada é essencial para atingir a saturação da GPU, garantindo que você extraia o máximo valor dos recursos de GPU, que são caros, ao mesmo tempo em que oferece alto throughput, baixa latência e operações econômicas. As otimizações apresentadas a seguir ajudarão você a maximizar a performance da implantação do vLLM no EKS.
Avaliação comparativa das configurações do vLLM
Para ajustar os parâmetros de configuração do vLLM ao seu caso de uso, compare diferentes configurações empregando uma ferramenta abrangente de avaliação comparativa de inferência, como o GuideLLM
Configuração de linha de base do vLLM
Esta é a configuração básica usada para executar o vLLM:
| Parâmetro do vLLM | Descrição |
|---|---|
|
tensor_parallel_size: 1 |
Distribuição do modelo em 1 GPU |
|
gpu_memory_utilization: 0,90 |
Reserva 10% da memória da GPU para sobrecarga do sistema |
|
max_sequence_length: 8.192 |
Comprimento máximo total da sequência (entrada + saída) |
|
max_num_seqs: 1 |
Número máximo de solicitações simultâneas por GPU (agrupamento em lotes) |
Execute o GuideLLM com essa configuração de linha de base para estabelecer uma linha de base para a performance. Neste teste, o GuideLLM está configurado para gerar 1 solicitação por segundo, com solicitações de 256 tokens e respostas de 128 tokens.
guidellm benchmark \ --target "http://${NLB}:80" \ --processor meta-llama/Llama-3.1-8B-Instruct \ --rate-type constant \ --rate 1 \ --max-seconds 30 \ --data "prompt_tokens=256,output_tokens=128"
Saída esperada:
Resultados da avaliação comparativa de referência

Configuração otimizada do vLLM
Ajuste os parâmetros do vLLM para melhor utilizar os recursos da GPU e a paralelização:
| Parâmetro do vLLM | Descrição |
|---|---|
|
tensor_parallel_size: 1 |
Mantenha em 1 GPU. A paralelização de tensores deve corresponder ao número de GPUs a serem usadas pelo vLLM. |
|
gpu_memory_utilization: 0,92 |
Reduza a sobrecarga de memória da GPU, se possível, ao mesmo tempo em que garante que o vLLM continua a ser executado sem erros. |
|
max_sequence_length: 4.096 |
Ajuste o comprimento máximo da sequência de acordo com os requisitos do seu caso de uso. Um comprimento máximo menor libera recursos que podem ser usados para aumentar a paralelização. |
|
max_num_seqs: 8 |
Aumentar o número máximo de sequências aumenta o throughput, mas também a latência. Aumente este valor para maximizar o throughput, garantindo que a latência permaneça dentro dos requisitos do seu caso de uso. |
Aplique essas alterações à implantação em execução usando o comando kubectl patch:
kubectl patch deployment vllm-inference-app --type='json' -p='[ {"op": "replace", "path": "/spec/template/spec/containers/0/args/4", "value": "--gpu-memory-utilization=0.92"}, {"op": "replace", "path": "/spec/template/spec/containers/0/args/5", "value": "--max-model-len=4096"}, {"op": "replace", "path": "/spec/template/spec/containers/0/args/6", "value": "--max-num-seqs=8"} ]'
Verifique se o pod do vLLM está no estado Ready 1/1:
kubectl get pod -l app=vllm-inference-app -w
Saída esperada:
NAME READY UP-TO-DATE AVAILABLE AGE vllm-inference-app-65df5fddc8-5kmjm 1/1 1 1 5m
Em seguida, execute o GuideLLM novamente usando os mesmos valores da avaliação comparativa realizada anteriormente:
guidellm benchmark \ --target "http://${NLB}:80" \ --processor meta-llama/Llama-3.1-8B-Instruct \ --rate-type constant \ --rate 1 \ --max-seconds 30 \ --data "prompt_tokens=256,output_tokens=128"
Saída esperada:
Resultados da avaliação comparativa otimizados
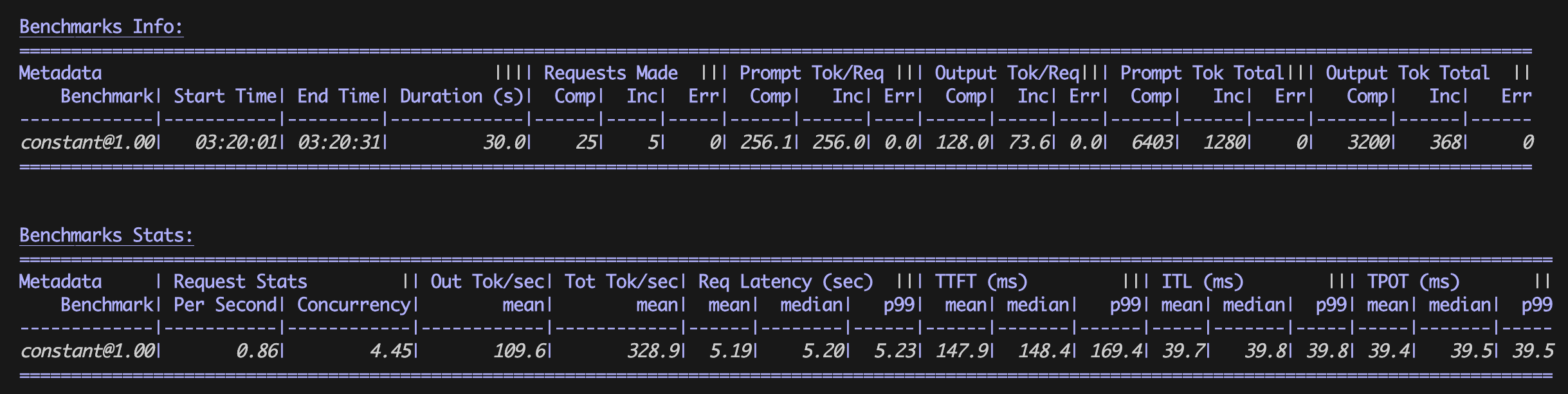
Resultados da avaliação comparativa
Os resultados da avaliação comparativa em uma tabela para as configurações de linha de base e otimizadas do vLLM são:
| Valores médios | Configuração de linha de base | Configuração otimizada |
|---|---|---|
|
RPS |
0,23 solicitações por segundo |
0,86 solicitações por segundo |
|
E2E |
12,99 s |
5,19 s |
|
TTFT |
8.637,2 ms |
147,9 ms |
|
TPOT |
34,0 ms |
39,5 ms |
As configurações otimizadas do vLLM melhoraram significativamente o throughput de inferência (RPS) e reduziram a latência (E2E e TTFT) com apenas um pequeno aumento de milissegundos no tempo por token de saída (TPOT). Esses resultados demonstram como o vLLM melhora significativamente a performance da inferência, permitindo que cada contêiner processe mais solicitações em menos tempo, resultando em uma operação com melhor custo-benefício.
