As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Migração do Couchbase Server
Introdução
Este guia apresenta os principais pontos a serem considerados ao migrar do Couchbase Server para o Amazon DocumentDB. Ele explica as considerações sobre as fases de descoberta, planejamento, execução e validação de sua migração. Também explica como realizar migrações offline e online.
Comparação com o Amazon DocumentDB
| Servidor Couchbase | Amazon DocumentDB | |
|---|---|---|
| Organização de dados | Nas versões 7.0 e posteriores, os dados são organizados em compartimentos, escopos e coleções. Nas versões anteriores, os dados são organizados em compartimentos. | Os dados são organizados em bancos de dados e coleções. |
| Compatibilidade | Existem separados APIs para cada serviço (por exemplo, dados, índice, pesquisa etc.). As pesquisas secundárias usam SQL++ (anteriormente conhecido como N1QL); uma linguagem de consulta baseada no SQL padrão ANSI, por isso é familiar para muitos desenvolvedores. | O Amazon DocumentDB é compatível com a API do MongoDB. |
| Arquitetura | O armazenamento é anexado a cada instância do cluster. Você não pode escalar a computação independentemente do armazenamento. | O Amazon DocumentDB foi projetado para a nuvem e para evitar as limitações das arquiteturas tradicionais de banco de dados. As camadas de computação e armazenamento são separadas no Amazon DocumentDB e a camada de computação pode ser escalada independentemente do armazenamento. |
| Adicione capacidade de leitura sob demanda | Os clusters podem ser expandidos adicionando instâncias. Como o armazenamento é anexado à instância em que o serviço está sendo executado, o tempo necessário para escalar depende da quantidade de dados que precisam ser movidos para a nova instância ou rebalanceados. | Você pode obter escalabilidade de leitura para seu cluster Amazon DocumentDB criando até 15 réplicas do Amazon DocumentDB no cluster. Não há impacto na camada de armazenamento. |
| Recupere-se rapidamente da falha do nó | Os clusters têm recursos de failover automático, mas o tempo necessário para que o cluster volte à força total depende da quantidade de dados que precisa ser movida para a nova instância. | O Amazon DocumentDB pode fazer o failover do primário normalmente em 30 segundos e restaurar a força total do cluster em 8 a 10 minutos, independentemente da quantidade de dados no cluster. |
| Dimensione o armazenamento à medida que os dados crescem | Para armazenamento de clusters autogerenciados e IOs não escale automaticamente. | Armazenamento e IOs escalabilidade automáticos do Amazon DocumentDB. |
| Faça backup de dados sem afetar o desempenho | Os backups são executados pelo serviço de backup e não são habilitados por padrão. Como o armazenamento e a computação não estão separados, pode haver um impacto no desempenho. | Os backups do Amazon DocumentDB estão habilitados por padrão e não podem ser desativados. Os backups são gerenciados pela camada de armazenamento, portanto, não têm impacto na camada de computação. O Amazon DocumentDB oferece suporte à restauração a partir de um snapshot de cluster e à restauração em um momento específico. |
| Durabilidade dos dados | Pode haver no máximo 3 cópias de réplicas de dados em um cluster para um total de 4 cópias. Cada instância em que o serviço de dados está sendo executado terá cópias ativas e 1, 2 ou 3 réplicas dos dados. | O Amazon DocumentDB mantém 6 cópias dos dados, não importa quantas instâncias computacionais existam, com um quorum de gravação de 4 e persistem como verdadeiras. Os clientes recebem uma confirmação após a camada de armazenamento persistir em 4 cópias dos dados. |
| Consistência | A consistência imediata das K/V operações é suportada. O SDK do Couchbase encaminha as K/V solicitações para a instância específica que contém a cópia ativa dos dados. Assim que uma atualização for confirmada, o cliente terá a garantia de ler essa atualização. A replicação de atualizações em outros serviços (índice, pesquisa, análise, eventos) acaba sendo consistente. | Eventualmente, as réplicas do Amazon DocumentDB são consistentes. Se forem necessárias leituras de consistência imediata, o cliente poderá ler a partir da instância primária. |
| Replicação | A replicação entre data centers (XDCR) fornece replicação filtrada, ativa-passiva/ativa-ativa de dados em muitas:muitas topologias. | Os clusters globais do Amazon DocumentDB fornecem replicação ativa-passiva em topologias de 1:muitas (até 10). |
Descoberta
A migração para o Amazon DocumentDB exige uma compreensão completa da carga de trabalho do banco de dados existente. A descoberta da carga de trabalho é o processo de analisar a configuração do cluster e as características operacionais do Couchbase — conjunto de dados, índices e carga de trabalho — para ajudar a garantir uma transição perfeita com o mínimo de interrupção.
Configuração do cluster
O Couchbase usa uma arquitetura centrada em serviços em que cada recurso corresponde a um serviço. Execute o comando a seguir em seu cluster do Couchbase para determinar quais serviços estão sendo usados (consulte Obter informações sobre nós
curl -v -u <administrator>:<password> \ http://<ip-address-or-hostname>:<port>/pools/nodes | \ jq '[.nodes[].services[]] | unique'
Exemplo de saída:
[ "backup", "cbas", "eventing", "fts", "index", "kv", "n1ql" ]
Os serviços do Couchbase incluem o seguinte:
Serviço de dados (kv)
O serviço de dados fornece read/write acesso aos dados na memória e no disco.
O Amazon DocumentDB suporta K/V operações em dados JSON por meio da API MongoDB.
Serviço de consulta (n1ql)
O serviço de consulta oferece suporte à consulta de dados JSON via SQL++.
O Amazon DocumentDB suporta a consulta de dados JSON por meio da API do MongoDB.
Serviço de indexação (índice)
O serviço de indexação cria e mantém índices nos dados, permitindo consultas mais rápidas.
O Amazon DocumentDB oferece suporte a um índice primário padrão e à criação de índices secundários em dados JSON por meio da API do MongoDB.
Serviço de pesquisa (fts)
O serviço de pesquisa suporta a criação de índices para pesquisa de texto completo.
O recurso nativo de pesquisa de texto completo do Amazon DocumentDB permite que você realize pesquisas de texto em grandes conjuntos de dados textuais usando índices de texto para fins especiais por meio da API do MongoDB. Para casos de uso de pesquisa avançada, a integração zero ETL do Amazon DocumentDB com o OpenSearch Amazon
Serviço de análise (cbas)
O serviço de análise oferece suporte à análise de dados JSON quase em tempo real.
O Amazon DocumentDB oferece suporte a consultas ad-hoc em dados JSON por meio da API MongoDB. Você também pode executar consultas complexas em seus dados JSON no Amazon DocumentDB usando o Apache Spark executado no Amazon
Serviço de eventos (eventos)
O serviço de eventos executa a lógica de negócios definida pelo usuário em resposta às alterações nos dados.
O Amazon DocumentDB automatiza cargas de trabalho orientadas por eventos invocando AWS Lambda funções sempre que os dados são alterados em seu cluster Amazon DocumentDB.
Serviço de backup (backup)
O serviço de backup agenda backups de dados completos e incrementais e mescla backups de dados anteriores.
O Amazon DocumentDB faz backup contínuo de seus dados no Amazon S3 com um período de retenção de 1 a 35 dias para que você possa restaurá-los rapidamente em qualquer ponto dentro do período de retenção de backup. O Amazon DocumentDB também tira snapshots automáticos dos seus dados como parte desse processo de backup contínuo. Você também pode gerenciar o backup e a restauração do Amazon DocumentDB
Características operacionais
Use a ferramenta Discovery para Couchbase
Conjunto de dados
A ferramenta recupera as seguintes informações de bucket, escopo e coleção:
nome do bucket
tipo de bucket
nome do escopo
nome da coleção
tamanho total (bytes)
total de itens
tamanho do item (bytes)
Índices
A ferramenta recupera as seguintes estatísticas de índice e todas as definições de índice para todos os buckets. Observe que os índices primários são excluídos, pois o Amazon DocumentDB cria automaticamente um índice primário para cada coleção.
nome do bucket
nome do escopo
nome da coleção
nome do índice
tamanho do índice (bytes)
Workload
A ferramenta recupera métricas de K/V consulta N1QL. K/V os valores métricos são coletados no nível do bucket e as métricas do SQL++ são coletadas no nível do cluster.
As opções da linha de comando da ferramenta são as seguintes:
python3 discovery.py \ --username <source cluster username> \ --password <source cluster password> \ --data_node <data node IP address or DNS name> \ --admin_port <administration http REST port> \ --kv_zoom <get bucket statistics for specified interval> \ --tools_path <full path to Couchbase tools> \ --index_metrics <gather index definitions and SQL++ metrics> \ --indexer_port <indexer service http REST port> \ --n1ql_start <start time for sampling> \ --n1ql_step <sample interval over the sample period>
Veja a seguir um exemplo de comando:
python3 discovery.py \ --username username \ --password ******** \ --data_node "http://10.0.0.1" \ --admin_port 8091 \ --kv_zoom week \ --tools_path "/opt/couchbase/bin" \ --index_metrics true \ --indexer_port 9102 \ --n1ql_start -60000 \ --n1ql_step 1000
Os valores da métrica K/V serão baseados em amostras a cada 10 minutos na última semana (consulte o método HTTP e o URI
collection-stats.csv — informações sobre bucket, escopo e coleta
bucket,bucket_type,scope_name,collection_name,total_size,total_items,document_size beer-sample,membase,_default,_default,2796956,7303,383 gamesim-sample,membase,_default,_default,114275,586,196 pillowfight,membase,_default,_default,1901907769,1000006,1902 travel-sample,membase,inventory,airport,547914,1968,279 travel-sample,membase,inventory,airline,117261,187,628 travel-sample,membase,inventory,route,13402503,24024,558 travel-sample,membase,inventory,landmark,3072746,4495,684 travel-sample,membase,inventory,hotel,4086989,917,4457 ...
index-stats.csv — nomes e tamanhos de índices
bucket,scope,collection,index-name,index-size beer-sample,_default,_default,beer_primary,468144 gamesim-sample,_default,_default,gamesim_primary,87081 travel-sample,inventory,airline,def_inventory_airline_primary,198290 travel-sample,inventory,airport,def_inventory_airport_airportname,513805 travel-sample,inventory,airport,def_inventory_airport_city,487289 travel-sample,inventory,airport,def_inventory_airport_faa,526343 travel-sample,inventory,airport,def_inventory_airport_primary,287475 travel-sample,inventory,hotel,def_inventory_hotel_city,497125 ...
kv-stats.csv — obtenha, defina e exclua métricas para todos os buckets
bucket,gets,sets,deletes beer-sample,0,0,0 gamesim-sample,0,0,0 pillowfight,369,521,194 travel-sample,0,0,0
n1ql-stats.csv — SQL++ seleciona, exclui e insere métricas para o cluster
selects,deletes,inserts 0,132,87
indexes- .txt <bucket-name>— definições de índice de todos os índices no bucket. Observe que os índices primários são excluídos, pois o Amazon DocumentDB cria automaticamente um índice primário para cada coleção.
CREATE INDEX `def_airportname` ON `travel-sample`(`airportname`) CREATE INDEX `def_city` ON `travel-sample`(`city`) CREATE INDEX `def_faa` ON `travel-sample`(`faa`) CREATE INDEX `def_icao` ON `travel-sample`(`icao`) CREATE INDEX `def_inventory_airport_city` ON `travel-sample`.`inventory`.`airport`(`city`) CREATE INDEX `def_inventory_airport_faa` ON `travel-sample`.`inventory`.`airport`(`faa`) CREATE INDEX `def_inventory_hotel_city` ON `travel-sample`.`inventory`.`hotel`(`city`) CREATE INDEX `def_inventory_landmark_city` ON `travel-sample`.`inventory`.`landmark`(`city`) CREATE INDEX `def_sourceairport` ON `travel-sample`(`sourceairport`) ...
Planejamento
Na fase de planejamento, você determinará os requisitos de cluster do Amazon DocumentDB e o mapeamento dos buckets, escopos e coleções do Couchbase para bancos de dados e coleções do Amazon DocumentDB.
Requisitos de cluster do Amazon DocumentDB
Use os dados coletados na fase de descoberta para dimensionar seu cluster Amazon DocumentDB. Consulte Dimensionamento de instâncias para obter mais informações sobre como dimensionar seu cluster Amazon DocumentDB.
Mapeamento de compartimentos, escopos e coleções para bancos de dados e coleções
Determine os bancos de dados e coleções que existirão no (s) seu (s) cluster (s) do Amazon DocumentDB. Considere as opções a seguir, dependendo de como os dados são organizados em seu cluster do Couchbase. Essas não são as únicas opções, mas fornecem pontos de partida para você considerar.
Couchbase Server 6.x ou anterior
Buckets do Couchbase para coleções do Amazon DocumentDB
Migre cada bucket para uma coleção diferente do Amazon DocumentDB. Nesse cenário, o valor do documento do Couchbase será usado como o id valor do Amazon _id DocumentDB.
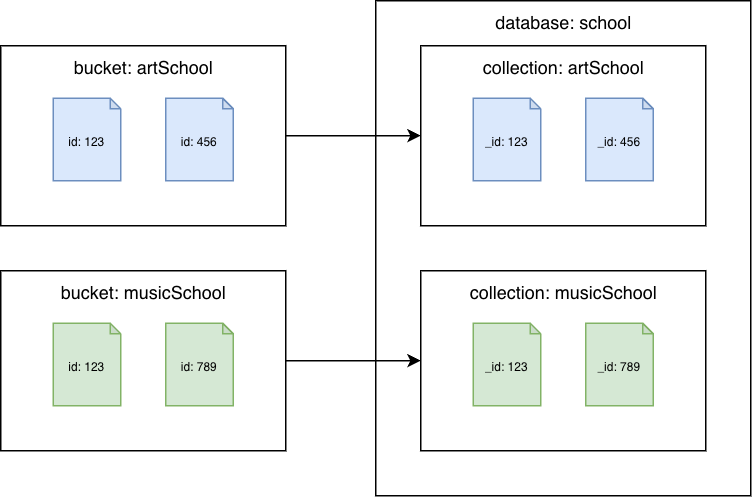
Couchbase Server 7.0 ou posterior
Coleções do Couchbase para coleções do Amazon DocumentDB
Migre cada coleção para uma coleção diferente do Amazon DocumentDB. Nesse cenário, o valor do documento do Couchbase será usado como o id valor do Amazon _id DocumentDB.
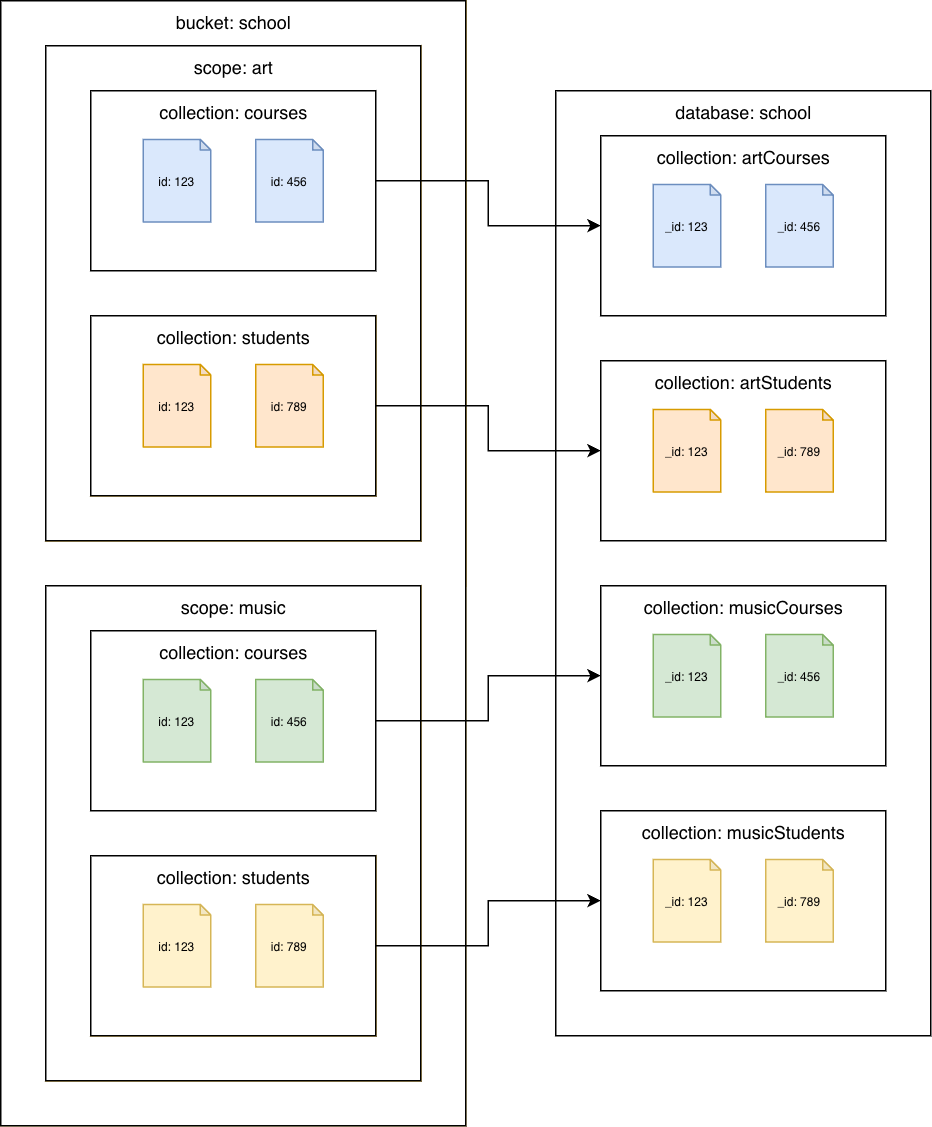
Migração
Migração de índices
A migração para o Amazon DocumentDB envolve a transferência não apenas de dados, mas também de índices para manter o desempenho das consultas e otimizar as operações do banco de dados. Esta seção descreve o step-by-step processo detalhado de migração de índices para o Amazon DocumentDB e, ao mesmo tempo, garante compatibilidade e eficiência.
Use o Amazon Q para converter instruções SQL++ em CREATE INDEX comandos do Amazon createIndex() DocumentDB.
Faça o upload dos arquivos indexes- .txt <bucket name>criados pela Discovery Tool for Couchbase.
Insira o seguinte prompt:
Convert the Couchbase CREATE INDEX statements to Amazon DocumentDB createIndex commands
O Amazon Q gerará comandos equivalentes do Amazon DocumentDBcreateIndex(). Observe que talvez seja necessário atualizar os nomes das coleções com base em como você mapeou os buckets, escopos e coleções do Couchbase para as coleções do Amazon DocumentDB.
Por exemplo:
indexes-beer-sample.txt
CREATE INDEX `beerType` ON `beer-sample`(`type`) CREATE INDEX `code` ON `beer-sample`(`code`) WHERE (`type` = "brewery")
Exemplo de saída do Amazon Q (trecho):
db.beerSample.createIndex( { "type": 1 }, { "name": "beerType", "background": true } ) db.beerSample.createIndex( { "code": 1 }, { "name": "code", "background": true, "partialFilterExpression": { "type": "brewery" } } )
Para quaisquer índices que o Amazon Q não consiga converter, consulte Gerenciando índices do Amazon DocumentDB e Índices e propriedades de índice para obter mais informações.
Refatore o código para usar o MongoDB APIs
Os clientes usam o Couchbase SDKs para se conectar ao Couchbase Server. Os clientes do Amazon DocumentDB usam drivers do MongoDB para se conectar ao Amazon DocumentDB. Todos os idiomas suportados pelo Couchbase também SDKs são suportados pelos drivers do MongoDB. Consulte MongoDB
Como APIs são diferentes entre o Couchbase Server e o Amazon DocumentDB, você precisará refatorar seu código para usar o MongoDB apropriado. APIs Você pode usar o Amazon Q para converter as chamadas de K/V API e as consultas SQL++ no MongoDB equivalente: APIs
Faça upload do (s) arquivo (s) do código-fonte.
Insira o seguinte prompt:
Convert the Couchbase API code to Amazon DocumentDB API code
Usando o exemplo de código Hello Couchbase Python
from datetime import timedelta from pymongo import MongoClient # Connection parameters database_name = "travel-sample" # Connect to Amazon DocumentDB cluster client = MongoClient('<Amazon DocumentDB connection string>') # Get reference to database and collection db = client['travel-sample'] airline_collection = db['airline'] # upsert document function def upsert_document(doc): print("\nUpsert Result: ") try: # key will equal: "airline_8091" key = doc["type"] + "_" + str(doc["id"]) doc['_id'] = key # Amazon DocumentDB uses _id as primary key result = airline_collection.update_one( {'_id': key}, {'$set': doc}, upsert=True ) print(f"Modified count: {result.modified_count}") except Exception as e: print(e) # get document function def get_airline_by_key(key): print("\nGet Result: ") try: result = airline_collection.find_one({'_id': key}) print(result) except Exception as e: print(e) # query for document by callsign def lookup_by_callsign(cs): print("\nLookup Result: ") try: result = airline_collection.find( {'callsign': cs}, {'name': 1, '_id': 0} ) for doc in result: print(doc['name']) except Exception as e: print(e) # Test document airline = { "type": "airline", "id": 8091, "callsign": "CBS", "iata": None, "icao": None, "name": "Couchbase Airways", } upsert_document(airline) get_airline_by_key("airline_8091") lookup_by_callsign("CBS")
Consulte Conexão programática ao Amazon DocumentDB para ver exemplos de conexão com o Amazon DocumentDB em Python, Node.js, PHP, Go, Java, C#/.NET, R e Ruby.
Selecione a abordagem de migração
Ao migrar dados para o Amazon DocumentDB, há duas opções:
Migração offline
Considere uma migração off-line quando:
O tempo de inatividade é aceitável: a migração off-line envolve interromper as operações de gravação no banco de dados de origem, exportar os dados e importá-los para o Amazon DocumentDB. Esse processo gera tempo de inatividade para seu aplicativo. Se seu aplicativo ou carga de trabalho puder tolerar esse período de indisponibilidade, a migração off-line é uma opção viável.
Migração de conjuntos de dados menores ou realização de provas de conceito: Para conjuntos de dados menores, o tempo necessário para o processo de exportação e importação é relativamente curto, tornando a migração off-line um método rápido e simples. Também é adequado para desenvolvimento, testes e proof-of-concept ambientes em que o tempo de inatividade é menos crítico.
Simplicidade é uma prioridade: o método off-line, usando cbexport e mongoimport, geralmente é a abordagem mais direta para migrar dados. Isso evita as complexidades da captura de dados de alteração (CDC) envolvida nos métodos de migração on-line.
Nenhuma alteração contínua precisa ser replicada: se o banco de dados de origem não estiver recebendo ativamente as alterações durante a migração ou se essas alterações não forem essenciais para serem capturadas e aplicadas ao destino durante o processo de migração, uma abordagem off-line é apropriada.
Couchbase Server 6.x ou anterior
Bucket do Couchbase para a coleção Amazon DocumentDB
Exporte dados usando cbexport json--format opção, você pode usar lines oulist.
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id
Importe os dados para uma coleção do Amazon DocumentDB usando o mongoimport com a opção apropriada para importar as linhas ou a lista:
linhas:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
lista:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
Couchbase Server 7.0 ou posterior
Para realizar uma migração off-line, use as ferramentas cbexport e mongoimport:
Bucket do Couchbase com escopo e coleção padrão
Exporte dados usando cbexport json--format opção, você pode usar lines oulist.
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id
Importe os dados para uma coleção do Amazon DocumentDB usando o mongoimport com a opção apropriada para importar as linhas ou a lista:
linhas:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
lista:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
Coleções do Couchbase para coleções do Amazon DocumentDB
Exporte dados usando cbexport json--include-data opção de exportar cada coleção. Para a --format opção, você pode usar lines oulist. Use as --collection-field opções --scope-field e para armazenar o nome do escopo e da coleção nos campos especificados em cada documento JSON.
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --include-data <scope name>.<collection name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id \ --scope-field "_scope" \ --collection-field "_collection"
Como o cbexport adicionou os _collection campos _scope e a cada documento exportado, você pode removê-los de todos os documentos no arquivo de exportação por meio de pesquisa e substituiçãosed, ou qualquer método de sua preferência.
Importe os dados de cada coleção para uma coleção do Amazon DocumentDB usando o mongoimport com a opção apropriada para importar as linhas ou a lista:
linhas:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
lista:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
migração online
Considere uma migração on-line quando precisar minimizar o tempo de inatividade e as mudanças contínuas precisarem ser replicadas para o Amazon DocumentDB quase em tempo real.
Consulte Como realizar uma migração ao vivo do Couchbase para o Amazon DocumentDB para
Couchbase Server 6.x ou anterior
Bucket do Couchbase para a coleção Amazon DocumentDB
O utilitário de migração do Couchbasedocument.id.strategy parâmetro é configurado para usar o valor da chave da mensagem como o valor do _id campo (consulte Propriedades da estratégia de identificação do conector do coletor
ConnectorConfiguration: document.id.strategy: 'com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy'
Couchbase Server 7.0 ou posterior
Bucket do Couchbase com escopo e coleção padrão
O utilitário de migração do Couchbasedocument.id.strategy parâmetro é configurado para usar o valor da chave da mensagem como o valor do _id campo (consulte Propriedades da estratégia de identificação do conector do coletor
ConnectorConfiguration: document.id.strategy: 'com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy'
Coleções do Couchbase para coleções do Amazon DocumentDB
Configure o conector de origem
ConnectorConfiguration: # add couchbase.collections configuration couchbase.collections: '<scope 1>.<collection 1>, <scope 1>.<collection 2>, ...'
Configure o conector do coletor
ConnectorConfiguration: # remove collection configuration #collection: 'test' # modify topics configuration topics: '<bucket>.<scope 1>.<collection 1>, <bucket>.<scope 1>.<collection 2>, ...' # add topic.override.%s.%s configurations for each topic topic.override.<bucket>.<scope 1>.<collection 1>.collection: '<collection>' topic.override.<bucket>.<scope 1>.<collection 2>.collection: '<collection>'
Validação
Esta seção fornece um processo de validação detalhado para verificar a consistência e a integridade dos dados após a migração para o Amazon DocumentDB. As etapas de validação se aplicam independentemente do método de migração.
Tópicos
Verifique se todas as coleções existem no destino
Fonte do Couchbase
opção 1: banco de trabalho de consulta
SELECT RAW `path` FROM system:keyspaces WHERE `bucket` = '<bucket>'
opção 2: ferramenta cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT RAW `path` FROM system:keyspaces WHERE `bucket` = '<bucket>'"
Destino do Amazon DocumentDB
mongosh (consulte Connect to your Amazon DocumentDB cluster):
db.getSiblingDB('<database>') db.getCollectionNames()
Verifique a contagem de documentos entre os clusters de origem e de destino
Fonte do Couchbase
Couchbase Server 6.x ou anterior
opção 1: banco de trabalho de consulta
SELECT COUNT(*) FROM `<bucket>`
opção 2: cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`"
Couchbase Server 7.0 ou posterior
opção 1: banco de trabalho de consulta
SELECT COUNT(*) FROM `<bucket>`.`<scope>`.`<collection>`
opção 2: cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`.`<scope>`.`<collection>`"
Destino do Amazon DocumentDB
mongosh (consulte Connect to your Amazon DocumentDB cluster):
db = db.getSiblingDB('<database>') db.getCollection('<collection>').countDocuments()
Compare documentos entre clusters de origem e de destino
Fonte do Couchbase
Couchbase Server 6.x ou anterior
opção 1: banco de trabalho de consulta
SELECT META().id as _id, * FROM `<bucket>` LIMIT 5
opção 2: cbq
cbq \ -e <source cluster endpoint> -u <username> \ -p <password> \ -q "SELECT META().id as _id, * FROM `<bucket>` \ LIMIT 5"
Couchbase Server 7.0 ou posterior
opção 1: banco de trabalho de consulta
SELECT COUNT(*) FROM `<bucket>`.`<scope>`.`<collection>`
opção 2: cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`.`<scope>`.`<collection>`"
Destino do Amazon DocumentDB
mongosh (consulte Connect to your Amazon DocumentDB cluster):
db = db.getSiblingDB('<database>') db.getCollection('<collection>').find({ _id: { $in: [ <_id 1>, <_id 2>, <_id 3>, <_id 4>, <_id 5> ] } })
