As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Criar um trabalho híbrido
Esta seção mostra como criar um Hybrid Job usando um script do Python. Como alternativa, para criar um trabalho híbrido a partir do código Python local, como seu ambiente de desenvolvimento integrado (IDE) preferido ou um caderno do Braket, consulte Execute seu código local como um trabalho híbrido.
Nesta seção:
Criar e executar
Depois de ter um perfil com permissões para executar um trabalho híbrido, você estará pronto para continuar. A peça-chave do seu primeiro trabalho híbrido do Braket é o script do algoritmo. Ele define o algoritmo que você deseja executar e contém a lógica clássica e as tarefas quânticas que fazem parte do seu algoritmo. Além do script do algoritmo, você pode fornecer outros arquivos de dependência. O script do algoritmo, junto com suas dependências, é chamado de módulo de origem. O ponto de entrada define o primeiro arquivo ou função a ser executado em seu módulo de origem quando o trabalho híbrido é iniciado.
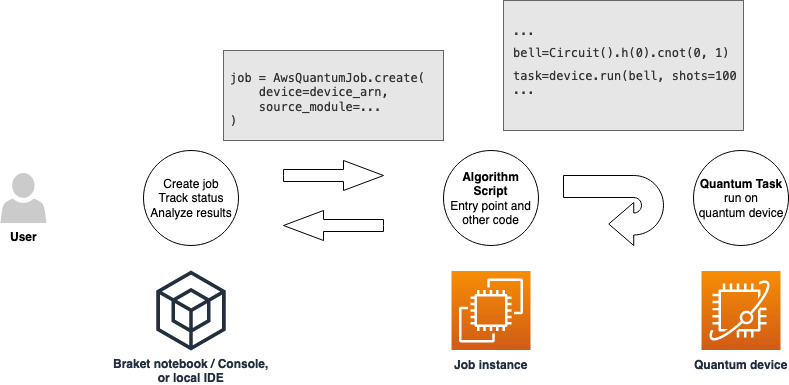
Primeiro, considere o seguinte exemplo básico de um script de algoritmo que cria cinco estados de sino e imprime os resultados de medição correspondentes.
import os from braket.aws import AwsDevice from braket.circuits import Circuit def start_here(): print("Test job started!") # Use the device declared in the job script device = AwsDevice(os.environ["AMZN_BRAKET_DEVICE_ARN"]) bell = Circuit().h(0).cnot(0, 1) for count in range(5): task = device.run(bell, shots=100) print(task.result().measurement_counts) print("Test job completed!")
Salve esse arquivo com o nome algorithm_script.py em seu diretório de trabalho atual no notebook Braket ou no ambiente local. O arquivo algorithm_script.py tem start_here() como ponto de entrada planejado.
Em seguida, crie um arquivo Python ou um caderno Python no mesmo diretório do arquivo algorithm_script.py. Esse script inicia o trabalho híbrido e processa qualquer processamento assíncrono, como imprimir o status ou os principais resultados nos quais estamos interessados. No mínimo, esse script precisa especificar seu script de trabalho híbrido e seu dispositivo principal.
nota
Para obter mais informações sobre como criar um caderno Braket ou fazer upload de um arquivo, como o arquivo algorithm_script.py, no mesmo diretório dos cadernos, consulte Executar seu primeiro circuito usando o Amazon Braket Python SDK.
Para esse primeiro caso básico, você escolhe um simulador. Qualquer que seja o tipo de dispositivo quântico que você almeje, um simulador ou uma unidade de processamento quântico (QPU) real, o dispositivo especificado com device no script a seguir é usado para agendar a tarefa híbrida e está disponível para os scripts do algoritmo como a variável de ambiente AMZN_BRAKET_DEVICE_ARN.
nota
Você só pode usar dispositivos que estejam disponíveis no Região da AWS seu trabalho híbrido. O Amazon Braket SDK seleciona automaticamente a Região da AWS. Por exemplo, uma tarefa híbrida em us-east-1 pode usar dispositivos IonQ, SV1, DM1, e TN1, mas não Rigetti.
Se você escolher um computador quântico em vez de um simulador, o Braket agenda seus trabalhos híbridos para executar todas as tarefas quânticas com acesso prioritário.
from braket.aws import AwsQuantumJob from braket.devices import Devices job = AwsQuantumJob.create( Devices.Amazon.SV1, source_module="algorithm_script.py", entry_point="algorithm_script:start_here", wait_until_complete=True )
O parâmetro wait_until_complete=True define um modo detalhado para que seu trabalho imprima a saída do trabalho real enquanto ele está sendo executado. Você deverá ver uma saída semelhante ao exemplo a seguir.
Initializing Braket Job: arn:aws:braket:us-west-2:111122223333:job/braket-job-default-123456789012 Job queue position: 1 Job queue position: 1 Job queue position: 1 .............. . . . Beginning Setup Checking for Additional Requirements Additional Requirements Check Finished Running Code As Process Test job started! Counter({'00': 58, '11': 42}) Counter({'00': 55, '11': 45}) Counter({'11': 51, '00': 49}) Counter({'00': 56, '11': 44}) Counter({'11': 56, '00': 44}) Test job completed! Code Run Finished 2025-09-24 23:13:40,962 sagemaker-training-toolkit INFO Reporting training SUCCESS
nota
Você também pode usar seu módulo personalizado com o AwsQuantumJob.create
Monitorar resultados
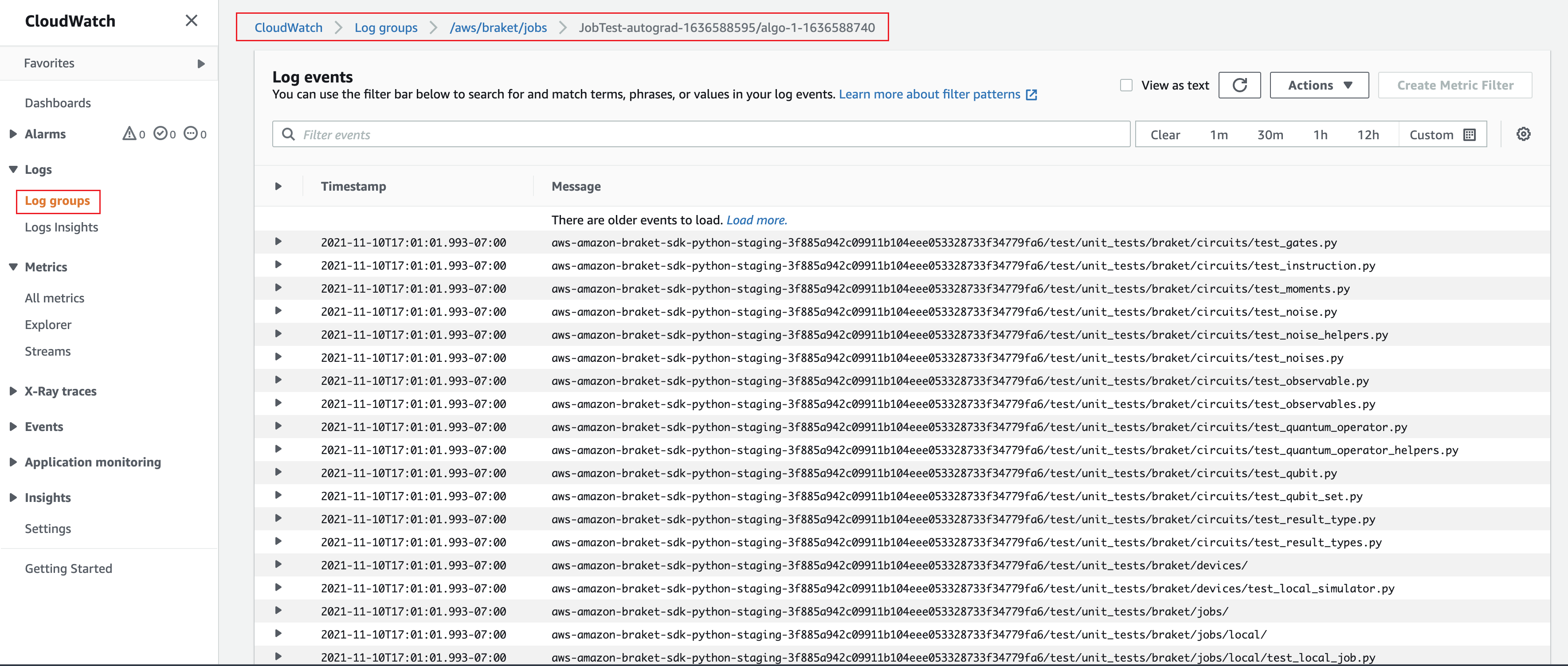
Como alternativa, você pode acessar a saída do log da Amazon CloudWatch. Para fazer isso, acesse a guia Grupos de logs no menu esquerdo da página de detalhes do trabalho, selecione o grupo de logs aws/braket/jobs e escolha o fluxo de logs que contém o nome do trabalho. No exemplo acima, ele é braket-job-default-1631915042705/algo-1-1631915190.
Você também pode visualizar o status do trabalho híbrido no console selecionando a página Trabalhos híbridos e, em seguida, escolhendo Configurações.
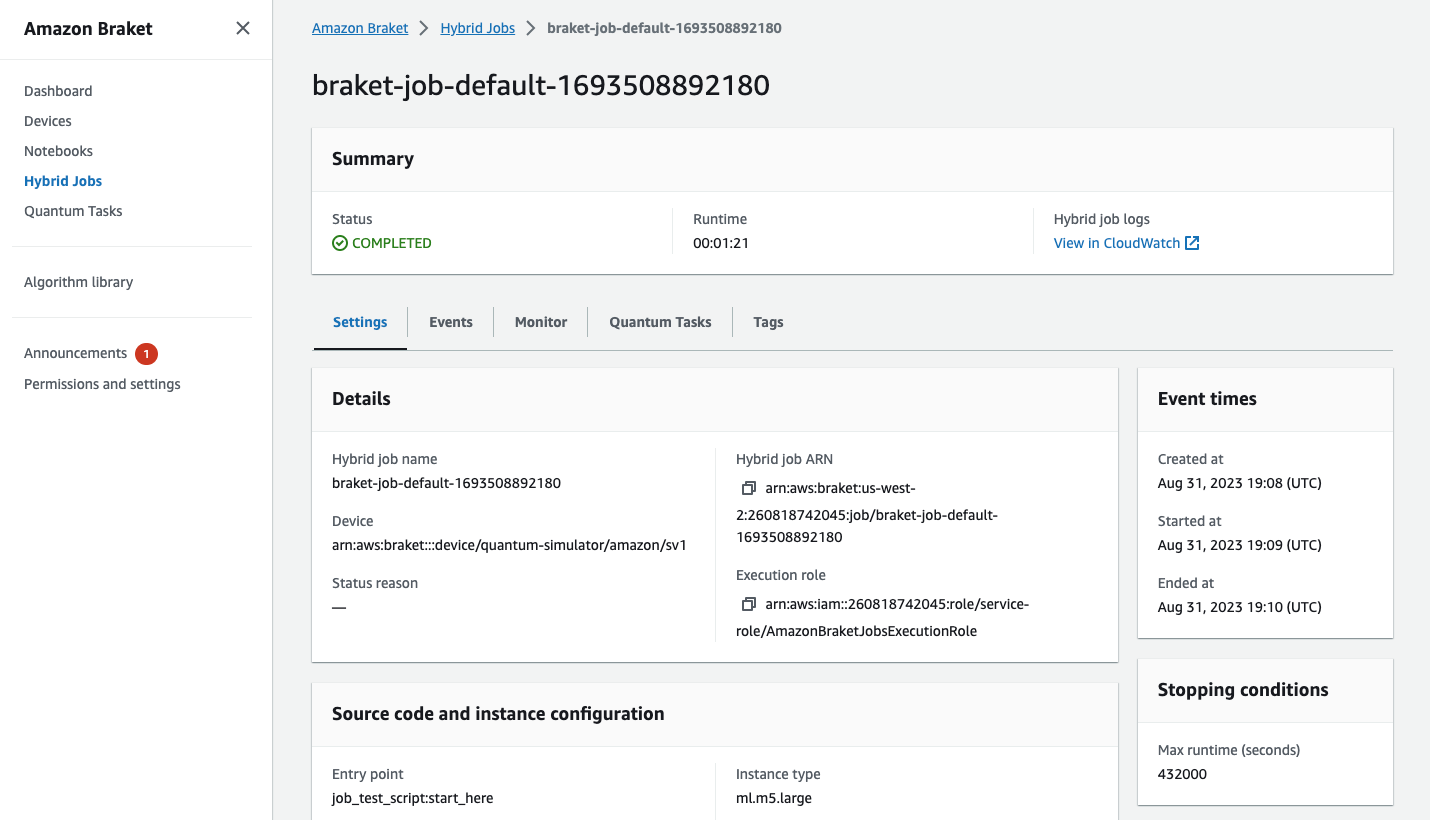
Seu trabalho híbrido produz alguns artefatos no Amazon S3 enquanto é executado. O nome padrão do bucket do S3 é amazon-braket-<region>-<accountid> e o conteúdo está no diretório jobs/<jobname>/<timestamp>. Você pode configurar os locais do S3 em que esses artefatos são armazenados especificando um code_location diferente quando a tarefa híbrida é criada com o SDK Braket Python.
nota
Esse bucket do S3 deve estar localizado da Região da AWS mesma forma que seu script de trabalho.
O diretório jobs/<jobname>/<timestamp> contém uma subpasta com a saída do script do ponto de entrada em um arquivo model.tar.gz. Também há um diretório chamado script que contém os artefatos do script do algoritmo em um source.tar.gz arquivo. Os resultados de suas tarefas quânticas reais estão no diretório nomeado jobs/<jobname>/tasks.
Salve seus resultados
Você pode salvar os resultados gerados pelo script do algoritmo para que estejam disponíveis no objeto de trabalho híbrido no script de trabalho híbrido, bem como na pasta de saída no Amazon S3 (em um arquivo compactado em tar chamado model.tar.gz).
A saída deve ser salva em um arquivo usando o formato JavaScript Object Notation (JSON). Se os dados não puderem ser prontamente serializados em texto, como no caso de uma matriz numérica, você poderá passar uma opção para serializar usando um formato de dados em conserva. Consulte o módulo braket.jobs.data_persistence
Para salvar os resultados das tarefas híbridas, adicione as seguintes linhas comentadas com #ADD ao arquivo algorithm_script.py.
import os from braket.aws import AwsDevice from braket.circuits import Circuit from braket.jobs import save_job_result # ADD def start_here(): print("Test job started!") device = AwsDevice(os.environ['AMZN_BRAKET_DEVICE_ARN']) results = [] # ADD bell = Circuit().h(0).cnot(0, 1) for count in range(5): task = device.run(bell, shots=100) print(task.result().measurement_counts) results.append(task.result().measurement_counts) # ADD save_job_result({"measurement_counts": results}) # ADD print("Test job completed!")
Em seguida, você pode exibir os resultados do trabalho a partir do seu script de trabalho anexando a linha print(job.result()) comentada com #ADD.
import time from braket.aws import AwsQuantumJob job = AwsQuantumJob.create( source_module="algorithm_script.py", entry_point="algorithm_script:start_here", device="arn:aws:braket:::device/quantum-simulator/amazon/sv1", ) print(job.arn) while job.state() not in AwsQuantumJob.TERMINAL_STATES: print(job.state()) time.sleep(10) print(job.state()) print(job.result()) # ADD
Neste exemplo, removemos wait_until_complete=True para suprimir a saída detalhada. Você pode adicioná-lo novamente para depuração. Quando você executa essa tarefa híbrida, ela gera o identificador e o job-arn, seguidos pelo estado da tarefa híbrida a cada 10 segundos até que a tarefa híbrida chegue a COMPLETED, após o qual mostra os resultados do circuito da campainha. Veja o exemplo a seguir.
arn:aws:braket:us-west-2:111122223333:job/braket-job-default-123456789012 INITIALIZED RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING ... RUNNING RUNNING COMPLETED {'measurement_counts': [{'11': 53, '00': 47},..., {'00': 51, '11': 49}]}
Usando pontos de verificação
Você pode salvar iterações intermediárias de seus trabalhos híbridos usando pontos de verificação. No exemplo de script de algoritmo da seção anterior, você adicionaria as seguintes linhas comentadas com #ADD para criar arquivos de ponto de verificação.
from braket.aws import AwsDevice from braket.circuits import Circuit from braket.jobs import save_job_checkpoint # ADD import os def start_here(): print("Test job starts!") device = AwsDevice(os.environ["AMZN_BRAKET_DEVICE_ARN"]) # ADD the following code job_name = os.environ["AMZN_BRAKET_JOB_NAME"] save_job_checkpoint(checkpoint_data={"data": f"data for checkpoint from {job_name}"}, checkpoint_file_suffix="checkpoint-1") # End of ADD bell = Circuit().h(0).cnot(0, 1) for count in range(5): task = device.run(bell, shots=100) print(task.result().measurement_counts) print("Test hybrid job completed!")
Ao executar o trabalho híbrido, o arquivo <jobname>-checkpoint-1.json é criado nos artefatos do trabalho híbrido, no diretório de checkpoints, com um caminho padrão /opt/jobs/checkpoints. O script de trabalho híbrido permanece inalterado, a menos que você queira alterar esse caminho padrão.
Se você quiser carregar uma tarefa híbrida a partir de um ponto de verificação gerado por uma tarefa híbrida anterior, o script do algoritmo usa from braket.jobs import load_job_checkpoint. A lógica a ser carregada em seu script de algoritmo é a seguinte.
from braket.jobs import load_job_checkpoint checkpoint_1 = load_job_checkpoint( "previous_job_name", checkpoint_file_suffix="checkpoint-1", )
Depois de carregar esse ponto de verificação, você pode continuar sua lógica com base no conteúdo carregado no checkpoint-1.
nota
O checkpoint_file_suffix deve corresponder ao sufixo especificado anteriormente ao criar o ponto de verificação.
Seu script de orquestração precisa especificar o job-arn do trabalho híbrido anterior com a linha comentada com #ADD.
from braket.aws import AwsQuantumJob job = AwsQuantumJob.create( source_module="source_dir", entry_point="source_dir.algorithm_script:start_here", device="arn:aws:braket:::device/quantum-simulator/amazon/sv1", copy_checkpoints_from_job="<previous-job-ARN>", #ADD )
