Práticas recomendadas para otimizar a performance da classe S3 Express One Zone
Ao criar aplicações que fazem upload e recuperam objetos da classe Amazon S3 Express One Zone, siga as nossas diretrizes de práticas recomendadas para otimizar a performance. Para usar a classe de armazenamento S3 Express One Zone, é necessário criar um bucket de diretório do S3. A classe de armazenamento S3 Express One Zone não é compatível com buckets de uso geral do S3.
Para consultar as diretrizes de desempenho para todas as outras classes de armazenamento do Amazon S3 e para buckets de uso geral do S3, consulte Padrões de design de melhores práticas: otimizar a performance do Amazon S3.
Para obter performance e escalabilidade ideais com a classe de armazenamento S3 Express One Zone e os buckets de diretório em workloads de alta escala, é importante entender em que sentido os buckets de diretório funcionam de forma diferente dos buckets de uso geral. Em seguida, fornecemos as práticas recomendadas para alinhar suas aplicações à forma como os buckets de diretório funcionam.
Como os buckets de diretório funcionam
A classe de armazenamento Amazon S3 Express One Zone pode comportar workloads com até 2 milhões de transações GET e até 200 mil transações PUT por segundo (TPS) por bucket de diretório. Com o S3 Express One Zone, os dados são armazenados em buckets de diretório do S3 em zonas de disponibilidade. Os objetos nos buckets de diretório podem ser acessados em um namespace hierárquico, de modo semelhante a um sistema de arquivos e diferentemente dos buckets de uso geral do S3, que têm um namespace simples. Ao contrário dos buckets de uso geral, os buckets de diretórios organizam as chaves hierarquicamente em diretórios em vez de prefixos. Um prefixo é uma string no início do nome da chave do objeto. Você pode usar prefixos para organizar os dados e gerenciar uma arquitetura de armazenamento de objetos simples em buckets de uso geral. Para obter mais informações, consulte Organizar objetos usando prefixos.
Nos buckets de diretório, os objetos são organizados em um namespace hierárquico usando a barra (/) como o único delimitador compatível. Quando você carrega um objeto com uma chave, como dir1/dir2/file1.txt, os diretórios dir1/ e dir2/ são automaticamente criados e gerenciados pelo Amazon S3. Os diretórios são criados durante as operações CreateMultiPartUpload ou PutObject e removidos automaticamente quando ficam vazios após após operações DeleteObject ou AbortMultiPartUpload. Não há limite máximo para o número de objetos e subdiretórios em um diretório.
Os diretórios criados quando os objetos são carregados em buckets de diretório podem ser escalados instantaneamente para reduzir a chance de erros HTTP 503 (Slow Down). Esse ajuste de escala automático permite que as aplicações emparelhem as solicitações de leitura e gravação dentro de um diretório e entre diretórios, conforme necessário. Para o S3 Express One Zone, os diretórios individuais são projetados para atender à taxa máxima de solicitações de um bucket de diretório. Não há necessidade de randomizar prefixos de chave para obter a performance ideal, pois o sistema distribui automaticamente os objetos para uma distribuição uniforme da carga, mas, como resultado, as chaves não são armazenadas lexicograficamente em buckets de diretório. Isso ocorre de maneira diferente nos buckets de uso geral do S3, nos quais as chaves que estão lexicograficamente mais próximas têm maior probabilidade de serem colocadas no mesmo servidor.
Para ter mais informações sobre exemplos de operações de bucket de diretório e interações de diretório, consulte Exemplos de operação de bucket de diretório e interação de diretórios.
Práticas recomendadas
Siga as práticas recomendadas para otimizar a performance do bucket de diretório e ajudar a escalar suas workloads ao longo do tempo.
Usar diretórios que contenham várias entradas (objetos ou subdiretórios)
Os buckets de diretório oferecem alta performance por padrão para todas as workloads. Para otimizar ainda mais a performance com determinadas operações, a consolidação de mais entradas (que são objetos ou subdiretórios) nos diretórios diminuirá a latência e aumentará a taxa de solicitações:
Operações de API mutantes, como
PutObject,DeleteObject,CreateMultiPartUploadeAbortMultiPartUpload, alcançam uma performance ideal quando implementadas com uma quantidade menor de diretórios mais densos que contenham milhares de entradas, em vez de com um grande número de diretórios menores.As operações
ListObjectsV2funcionam melhor quando menos diretórios precisam ser percorridos para preencher uma página de resultados.
Não usar entropia em prefixos
Nas operações do Amazon S3, a entropia se refere à aleatoriedade na nomenclatura de prefixos que ajuda a distribuir workloads uniformemente entre as partições de armazenamento. No entanto, como os buckets de diretório gerenciam internamente a distribuição de carga, não é recomendável usar entropia em prefixos para obter a melhor performance. Isso ocorre porque, em buckets diretório, a entropia pode fazer com que as solicitações fiquem mais lentas por não reutilizar os diretórios que já foram criados.
Um padrão de chave como $HASH/directory/object pode acabar criando muitos diretórios intermediários. No exemplo a seguir, todos os trabalhos job-1 são diretórios diferentes, pois os principais são diferentes. Os diretórios serão esparsos e as solicitações de mutação e lista serão mais lentas. Neste exemplo, há 12 diretórios intermediários, todos com uma única entrada.
s3://my-bucket/0cc175b9c0f1b6a831c399e269772661/job-1/file1 s3://my-bucket/92eb5ffee6ae2fec3ad71c777531578f/job-1/file2 s3://my-bucket/4a8a08f09d37b73795649038408b5f33/job-1/file3 s3://my-bucket/8277e0910d750195b448797616e091ad/job-1/file4 s3://my-bucket/e1671797c52e15f763380b45e841ec32/job-1/file5 s3://my-bucket/8fa14cdd754f91cc6554c9e71929cce7/job-1/file6
Em vez disso, para melhorar a performance, podemos remover o componente $HASH e permitir que job-1 se torne um único diretório, melhorando a densidade de um diretório. No exemplo a seguir, o único diretório intermediário que tem seis entradas pode aumentar a performance, em comparação com o exemplo anterior.
s3://my-bucket/job-1/file1 s3://my-bucket/job-1/file2 s3://my-bucket/job-1/file3 s3://my-bucket/job-1/file4 s3://my-bucket/job-1/file5 s3://my-bucket/job-1/file6
Essa vantagem de performance ocorre porque, quando uma chave de objeto é criada e seu nome inclui um diretório, o diretório é criado automaticamente para o objeto. Os uploads subsequentes de objetos para o mesmo diretório não exigirão que o diretório seja criado, o que reduzirá a latência dos uploads de objetos nos diretórios existentes.
Usar um separador diferente do delimitador / para separar partes da chave se não for necessário agrupar objetos logicamente durante as chamadas ListObjectsV2
Como o delimitador / é tratado especialmente para buckets de diretório, ele deve ser usado com propósito. Embora os buckets de diretório não ordenem objetos lexicograficamente, os objetos dentro de um diretório ainda assim são agrupados nas saídas de ListObjectsV2. Se você não precisar dessa funcionalidade, poderá substituir / por outro caractere como separador para não provocar a criação de diretórios intermediários.
Por exemplo, suponha que as seguintes chaves estejam em um padrão de prefixo YYYY/MM/DD/HH/:
s3://my-bucket/2024/04/00/01/file1 s3://my-bucket/2024/04/00/02/file2 s3://my-bucket/2024/04/00/03/file3 s3://my-bucket/2024/04/01/01/file4 s3://my-bucket/2024/04/01/02/file5 s3://my-bucket/2024/04/01/03/file6
Se você não precisar agrupar objetos por hora ou dia nos resultados de ListObjectsV2, mas precisar agrupar objetos por mês, o padrão de chave YYYY/MM/DD-HH- a seguir gerará um número significativamente menor de diretórios e melhorará a performance para a operação ListObjectsV2.
s3://my-bucket/2024/04/00-01-file1 s3://my-bucket/2024/04/00-01-file2 s3://my-bucket/2024/04/00-01-file3 s3://my-bucket/2024/04/01-02-file4 s3://my-bucket/2024/04/01-02-file5 s3://my-bucket/2024/04/01-02-file6
Usar operações de lista delimitada sempre que possível
Uma solicitação ListObjectsV2 sem um delimiter executa uma travessia recursiva no modo primeiro em profundidade em todos os diretórios. Uma solicitação ListObjectsV2 com um delimiter recupera somente entradas no diretório especificado pelo parâmetro prefix, reduzindo a latência da solicitação e aumentando as chaves agregadas por segundo. Para buckets de diretório, use operações de lista delimitada sempre que possível. As listas delimitadas fazem com que os diretórios sejam visitados menos vezes, o que aumenta a quantidade de chaves por segundo e diminui a latência das solicitações.
Por exemplo, para os seguintes diretórios e objetos em seu bucket de diretório:
s3://my-bucket/2024/04/12-01-file1 s3://my-bucket/2024/04/12-01-file2 ... s3://my-bucket/2024/05/12-01-file1 s3://my-bucket/2024/05/12-01-file2 ... s3://my-bucket/2024/06/12-01-file1 s3://my-bucket/2024/06/12-01-file2 ... s3://my-bucket/2024/07/12-01-file1 s3://my-bucket/2024/07/12-01-file2 ...
Para melhorar a performance de ListObjectsV2, use uma lista delimitada para listar seus subdiretórios e objetos, se a lógica da aplicação permitir. Por exemplo, você pode executar o seguinte comando para a operação de lista delimitada:
aws s3api list-objects-v2 --bucket my-bucket --prefix '2024/' --delimiter '/'
A saída é a lista de subdiretórios.
{ "CommonPrefixes": [ { "Prefix": "2024/04/" }, { "Prefix": "2024/05/" }, { "Prefix": "2024/06/" }, { "Prefix": "2024/07/" } ] }
Para listar cada subdiretório com melhor performance, execute um comando como o mostrada no seguinte exemplo:
Comando:
aws s3api list-objects-v2 --bucket my-bucket --prefix '2024/04' --delimiter '/'
Resultado:
{ "Contents": [ { "Key": "2024/04/12-01-file1" }, { "Key": "2024/04/12-01-file2" } ] }
Implantar o armazenamento da classe S3 Express One Zone na mesma localização dos recursos de computação
Com o S3 Express One Zone, cada bucket de diretório fica localizado em uma única zona de disponibilidade que você seleciona ao criar o bucket. Primeiro você pode criar um bucket de diretório em uma zona de disponibilidade local para workloads ou recursos de computação. Depois, você pode iniciar imediatamente leituras e gravações de latência muito baixa. Os buckets de diretório são um tipo de bucket do S3 em que você pode escolher a zona de disponibilidade em uma Região da AWS para reduzir a latência entre computação e armazenamento.
Se você acessar buckets de diretório entre zonas de disponibilidade, poderá experimentar um pequeno aumento na latência. Para otimizar a performance, recomendamos que você acesse um bucket de diretório por instâncias do Amazon Elastic Container Service, do Amazon Elastic Kubernetes Service e do Amazon Elastic Compute Cloud que estejam localizadas na mesma zona de disponibilidade, sempre que possível.
Usar conexões simultâneas para obter alto throughput com objetos acima de 1 MB
O melhor desempenho pode ser atingido com a emissão de várias solicitações simultâneas para buckets de diretório a fim de distribuir as solicitações em conexões separadas e maximizar a largura de banda acessível. Como os buckets de uso geral, a classe S3 Express One Zone não tem nenhum limite para o número de conexões feitas com o bucket de diretório. Diretórios individuais podem escalar a performance horizontal e automaticamente quando ocorre um grande número de gravações simultâneas no mesmo diretório.
As conexões TCP individuais com buckets de diretório têm um limite superior fixo no número de bytes que podem ser carregados ou baixados por segundo. Quando os objetos ficam maiores, o tempo de solicitação é controlado pelo streaming de bytes, e não pelo processamento de transações. Para usar várias conexões para paralelizar o upload ou o download de objetos maiores, você pode reduzir a latência de ponta a ponta. Se estiver usando o SDK da Java 2.x, considere usar o Gerenciador de transferências do S3, que aproveitará as melhorias de performance, como as operações de API de multipart upload e as consultas em escala de bytes, para acessar os dados em paralelo.
Endpoints da VPC de gateway
Os endpoints de gateway oferecem uma conexão direta entre a VPC e os buckets de diretório, sem a necessidade de um gateway da internet ou de um dispositivo NAT para a VPC. Para reduzir o tempo que seus pacotes permanecem na rede, você deve configurar a VPC com um endpoint da VPC de gateway para buckets de diretório. Para obter mais informações, consulte Rede para buckets de diretório.
Usar a autenticação de sessão e reutilizar os tokens de sessão enquanto estiverem válidos
Os buckets de diretório oferecem um mecanismo de autenticação de token de sessão para reduzir a latência em operações de API sensíveis à performance. Você pode fazer uma única chamada CreateSession para obter um token de sessão válido para todas as solicitações nos próximos 5 minutos. Para obter a menor latência em suas chamadas de API, adquira um token de sessão e reutilize-o durante toda a vida útil desse token antes de atualizá-lo.
Se você usar SDKs da AWS, as atualizações de token de sessão serão feitas automaticamente pelo SDK para evitar interrupções no serviço quando uma sessão expirar. Recomendamos que você use os SDKs da AWS para iniciar e gerenciar solicitações para a operação de API CreateSession.
Para obter mais informações sobre o CreateSession, consulte Autorizar operações de API de endpoint zonal com CreateSession.
Usar um cliente baseado em CRT
O AWS Common Runtime (CRT) é um conjunto de bibliotecas modulares e eficientes escritas em C e destinadas a atuar como base dos SDKs da AWS. O CRT oferece throughput aprimorado, melhor gerenciamento de conexão e tempos de inicialização mais rápidos. Ele está disponível em todos os SDKs da AWS, exceto no Go.
Para ter mais informações sobre como configurar o CRT para o SDK que você usa, consulte AWS Common Runtime (CRT) libraries, Accelerate Amazon S3 throughput with the AWS Common Runtime
Usar a versão mais recente dos SDKs da AWS
Os AWS SDKs fornecem suporte integrado a muitas da diretrizes recomendadas para otimizar a performance do Amazon S3. Os SDKs oferecem uma API mais simples para aproveitar o Amazon S3 em uma aplicação e são atualizados regularmente para seguir as práticas recomendadas mais recentes. Por exemplo, os SDKs repetem automaticamente as solicitações após erros HTTP 503 e lidam com respostas de conexões lentas.
Se estiver usando o SDK da Java 2.x, considere usar o Gerenciador de transferências do S3, que escala horizontalmente as conexões de maneira automática para atingir milhares de solicitações por segundo usando solicitações em escala de bytes quando apropriado. As solicitações em escala de bytes podem melhorar a performance porque você pode usar conexões simultâneas com o S3 para consultar escalas de bytes diferentes no mesmo objeto. Isso ajuda a atingir um throughput agregado maior em comparação com uma única solicitação de objeto inteiro. É importante usar a última versão dos SDKs da AWS para obter os recursos mais recentes de otimização de performance.
Solução de problemas de performance
Você está definindo as solicitações de nova tentativa para aplicações sensíveis à latência?
A classe S3 Express One Zone foi desenvolvida com o propósito específico de oferecer níveis consistentes de alta performance sem ajustes adicionais. No entanto, definir valores agressivos de tempo limite e novas tentativas pode ajudar ainda mais a impulsionar níveis consistentes de latência e desempenho. Os AWS SDKs têm valores configuráveis de tempo limite e repetição que podem ser ajustados de acordo com as tolerâncias da aplicação específica.
Você está usando bibliotecas do AWS Common Runtime (CRT) e tipos ideais de instância do Amazon EC2?
As aplicações que executam um grande número de operações de leitura e gravação provavelmente precisam de mais memória ou capacidade de computação do que as aplicações que não o fazem. Ao inicializar as instâncias do Amazon Elastic Compute Cloud (Amazon EC2) para uma workload que exige muita performance, escolha tipos de instância com a quantidade desses recursos que a aplicação precisa. O armazenamento de alta performance da classe S3 Express One Zone apresenta combinação ideal com tipos de instância maiores e mais novos, com quantidades maiores de memória do sistema e CPUs e GPUs mais poderosas que podem aproveitar o armazenamento de alta performance. Também recomendamos usar as versões mais recentes dos AWS SDKs habilitados para CRT, que podem acelerar ainda mais as solicitações de leitura e gravação em paralelo.
Você está usando SDKs da AWS para autenticação baseada em sessão?
Com o Amazon S3, você também pode otimizar a performance ao usar solicitações da API REST HTTP seguindo as mesmas práticas recomendadas que fazem parte dos AWS SDKs. No entanto, com o mecanismo de autorização e autenticação baseado em sessão usado pela classe S3 Express One Zone, é altamente recomendável que você use os AWS SDKs para gerenciar CreateSession e o respectivo token de sessão gerenciada. Os AWS SDKs criam e atualizam tokens automaticamente em seu nome usando a operação de API CreateSession. O uso de CreateSession gera economia na latência de ida e volta por solicitação para que o AWS Identity and Access Management (IAM) autorize cada solicitação.
Exemplos de operação de bucket de diretório e interação de diretórios
Veja a seguir três exemplos sobre como os buckets de diretório funcionam.
Exemplo 1: como as solicitações PutObject do S3 para um bucket de diretório interagem com os diretórios
-
Quando a operação
PUT(<bucket>, "documents/reports/quarterly.txt")é executada em um bucket vazio, o diretóriodocuments/na raiz do bucket é criado, o diretórioreports/emdocuments/é criado e o objetoquarterly.txtemreports/é criado. Para essa operação, além do objeto, foram criados dois diretórios.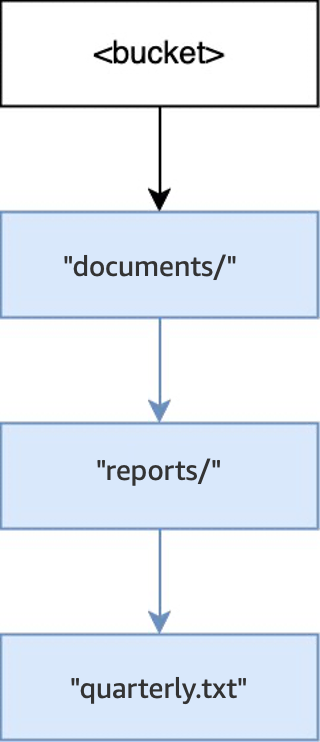
-
Portanto, quando outra operação
PUT(<bucket>, "documents/logs/application.txt")é executada, o diretóriodocuments/já existe, o diretóriologs/emdocuments/não existe e é criado e o objetoapplication.txtemlogs/é criado. Para essa operação, além do objeto, foram criados dois diretórios.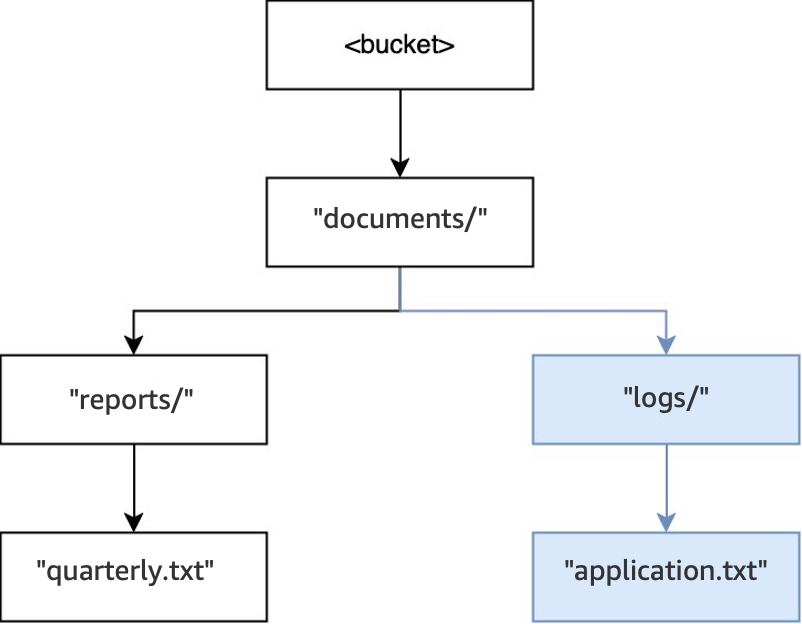
-
Por fim, quando uma operação
PUT(<bucket>, "documents/readme.txt")é executada, o diretóriodocuments/na raiz já existe e o objetoreadme.txté criado. Para essa operação, nenhum diretório é criado.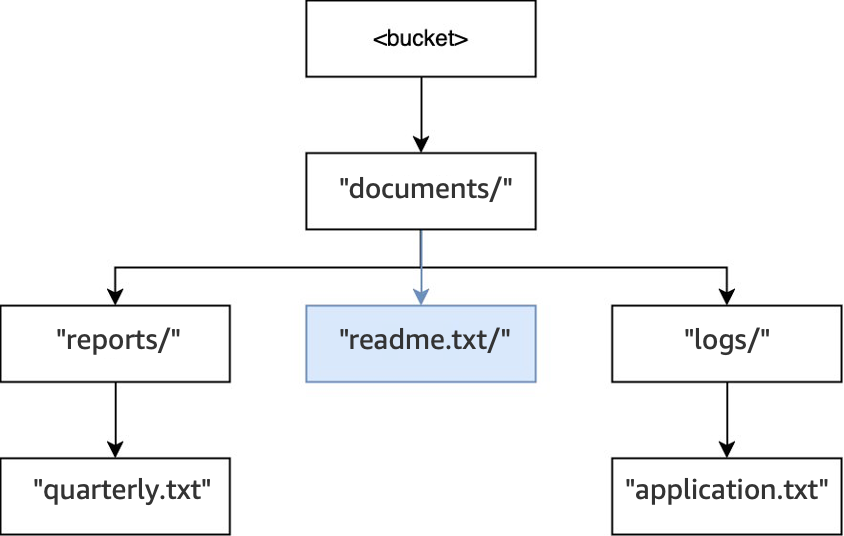
Exemplo 2: como as solicitações ListObjectsV2 do S3 para um bucket de diretório interagem com os diretórios
Para as solicitações ListObjectsV2 do S3 sem a especificação de um delimitador, o bucket é percorrido de acordo com o modo primeiro em profundidade. As saídas são retornadas em uma ordem consistente. No entanto, embora essa ordem permaneça a mesma entre as solicitações, ela não é lexicográfica. Para o bucket e os diretórios criados no exemplo anterior:
-
Quando
LIST(<bucket>)é executada, o diretóriodocuments/é inserido e a travessia começa. -
O subdiretório
logs/é inserido e a travessia começa. -
O objeto
application.txté encontrado emlogs/. -
Não existem mais entradas em
logs/. A operação List sai delogs/e entra emdocuments/novamente. -
O diretório
documents/continua sendo percorrido e o objetoreadme.txté encontrado. -
O diretório
documents/continua sendo percorrido, o subdiretórioreports/é inserido e a travessia começa. -
O objeto
quarterly.txté encontrado emreports/. -
Não existem mais entradas em
reports/. List sai dereports/e entra emdocuments/novamente. -
Não existem mais entradas em
documents/e a operação List retorna.
Neste exemplo, logs/ é colocado antes de readme.txt e readme.txt é colocado antes de reports/.
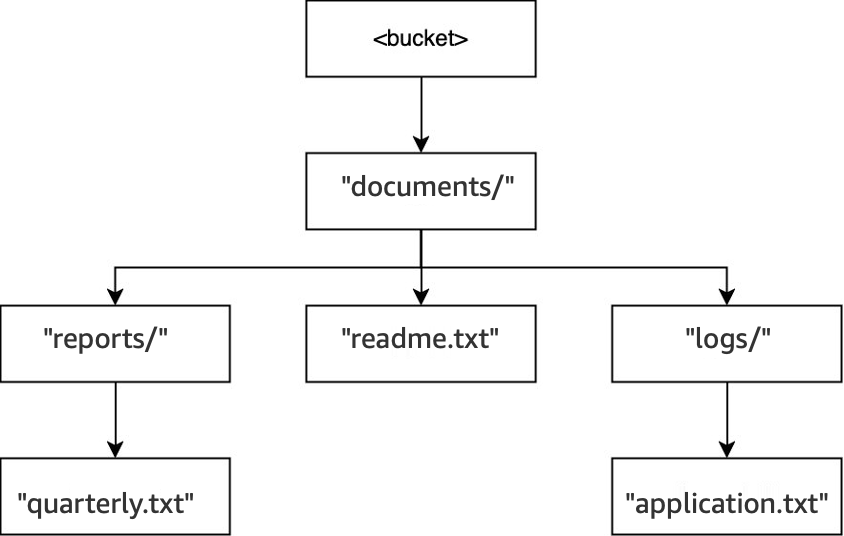
Exemplo 3: como as solicitações DeleteObject do S3 para um bucket de diretório interagem com os diretórios
-
Nesse mesmo bucket, quando a operação
DELETE(<bucket>, "documents/reports/quarterly.txt")é executada, o objetoquarterly.txté excluído, deixando o diretórioreports/vazio e fazendo com que ele seja excluído imediatamente. O diretóriodocuments/não está vazio porque tem o diretóriologs/e o objetoreadme.txtdentro dele; portanto, não é excluído. Nessa operação, somente um objeto e um diretório foram excluídos.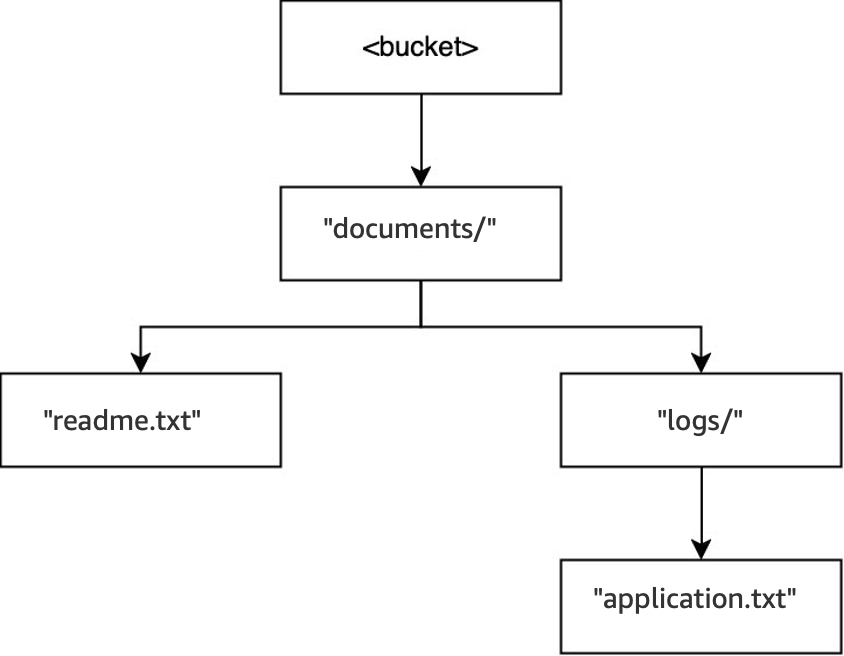
-
Quando a operação
DELETE(<bucket>, "documents/readme.txt")é executada, o objetoreadme.txté excluído.documents/ainda não está vazio porque contém o diretóriologs/; portanto, não foi excluído. Nessa operação, nenhum diretório é excluído e somente o objeto é excluído.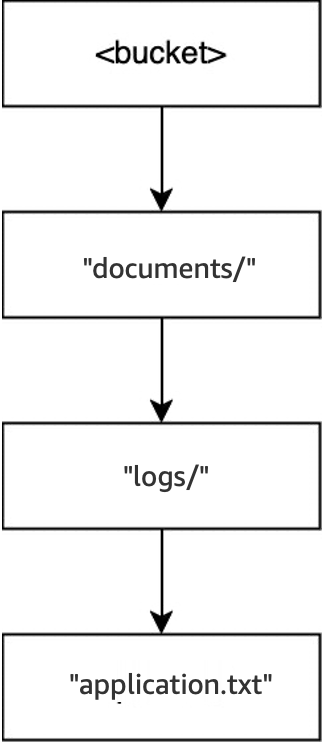
-
Por fim, quando a operação
DELETE(<bucket>, "documents/logs/application.txt")é executada,application.txté excluído, deixandologs/vazio e fazendo com que ele seja excluído imediatamente. Isso então deixadocuments/vazio e faz com que ele também seja excluído imediatamente. Nessa operação, dois diretórios e um objeto são excluídos. O bucket agora está vazio.
