Adicionar dados a um banco de dados do RDS de origem e consultá-los
Para criar uma Integração ETL zero que replica dados do Amazon RDS no Amazon Redshift, você deve criar um banco de dados de destino pretendido.
Para conexões com o Amazon Redshift, conecte-se ao cluster ou grupo de trabalho do Amazon Redshift e crie um banco de dados com uma referência ao identificador da integração. Depois, é possível adicionar dados ao banco de dados do RDS de origem e vê-los replicados no Amazon Redshift ou no Amazon SageMaker.
Tópicos
Criar um banco de dados de destino
Depois de criar uma integração, para começar a replicar dados no Amazon Redshift, você deve primeiro criar um banco de dados no data warehouse de destino. Esse banco de dados deve incluir uma referência ao identificador da integração. Você pode usar o console do Amazon Redshift ou o Editor de Consultas v2 para criar o banco de dados.
Para conferir instruções sobre como criar um banco de dados de destino, consulte Criar bancos de dados de destino no Amazon Redshift.
Adicionar dados ao banco de dados de origem
Depois de configurar a integração, você pode preencher o banco de dados do RDS de origem com dados que você deseja replicar no data warehouse.
nota
Há diferenças entre os tipos de dados no Amazon RDS e no warehouse de analytics de destino. Para obter uma tabela de mapeamentos de tipos de dados, consulte. Diferenças de tipos de dados entre os bancos de dados RDS e Amazon Redshift
Primeiro, conecte-se ao banco de dados de origem usando o cliente do MySQL de sua escolha. Para instruções, consulte Conectar-se à instância de banco de dados do MySQL.
Depois, crie uma tabela e insira uma linha de dados de exemplo.
Importante
Verifique se a tabela tem uma chave primária. Caso contrário, ela não poderá ser replicada no data warehouse de destino.
RDS para MySQL
O exemplo a seguir usa o utilitário MySQL Workbench
CREATE DATABASEmy_db; USEmy_db; CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
RDS para PostgreSQL
O exemplo a seguir usa o terminal interativo do PostgreSQL psql. Ao se conectar ao banco de dados, inclua o nome do banco de dados que você deseja replicar.
psql -hmydatabase.123456789012.us-east-2.rds.amazonaws.com -p 5432 -Uusername-dnamed_db; named_db=> CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); named_db=> INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
RDS para Oracle
O exemplo a seguir usa o SQL*Plus para se conectar ao banco de dados do RDS para Oracle.
sqlplus 'user_name@(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=dns_name)(PORT=port))(CONNECT_DATA=(SID=database_name)))' SQL> CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); SQL> INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
Consultar os dados do Amazon RDS no Amazon Redshift
Depois que os dados são adicionados ao banco de dados do RDS, eles são replicados no banco de dados de destino e podem ser consultados.
Como consultar os dados replicados
-
Navegue até o console do Amazon Redshift e escolha Editor de Consultas v2 no painel de navegação esquerdo.
-
Conecte-se ao cluster ou grupo de trabalho e escolha o banco de dados de destino (criado na integração) no menu suspenso (destination_database neste exemplo). Para conferir instruções sobre como criar um banco de dados de destino, consulte Criar bancos de dados de destino no Amazon Redshift.
-
Use uma declaração SELECT para consultar dados. Neste exemplo, é possível executar o comando a seguir para selecionar todos os dados da tabela que você criou no banco de dados do RDS de origem:
SELECT * frommy_db."books_table";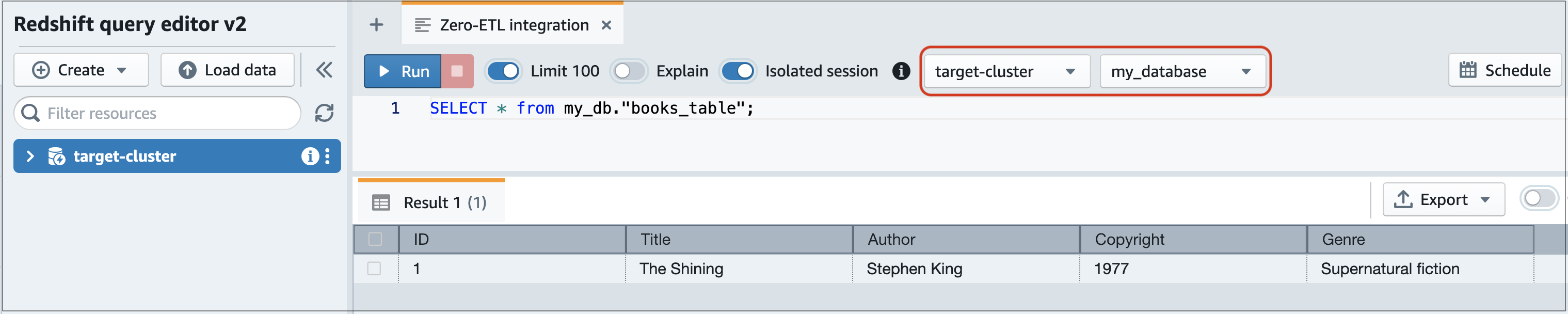
-
my_db -
books_table
-
Também é possível consultar os dados usando o cliente de linha de comandos. Por exemplo:
destination_database=# select * frommy_db."books_table"; ID | Title | Author | Copyright | Genre | txn_seq | txn_id ----+–------------+---------------+-------------+------------------------+----------+--------+ 1 | The Shining | Stephen King | 1977 | Supernatural fiction | 2 | 12192
nota
Para diferenciar letras maiúsculas de minúsculas, use aspas duplas (“ ”) para nomes de esquemas, tabelas e colunas. Para obter mais informações, consulte enable_case_sensitive_identifier.
Diferenças de tipos de dados entre os bancos de dados RDS e Amazon Redshift
Abaixo, as tabelas mostram as associações entre tipos de dados do RDS para MySQL, RDS para PostgreSQL e RDS para Oracle e tipos de dados de destino correspondentes. No momento, o Amazon RDS é compatível somente com esses tipos de dados para integrações ETL zero.
Se uma tabela no banco de dados de origem incluir um tipo de dado incompatível, a tabela ficará fora de sincronia e não poderá ser consumida no destino pretendido. O streaming da origem para o destino continuará, mas a tabela com o tipo de dados não compatível não estará disponível. Para corrigir a tabela e disponibilizá-la no destino pretendido, você deve reverter manualmente a alteração incompatível e, em seguida, atualizar a integração executando ALTER DATABASE...INTEGRATION
REFRESH.
nota
Não é possível atualizar Integrações ETL zero com um lakehouse do Amazon SageMaker. Em vez disso, exclua e tente criar a integração novamente.
RDS para MySQL
| Tipo de dados do RDS para MySQL | Tipo de dados de destino | Descrição | Limitações |
|---|---|---|---|
| INT | INTEGER | Número inteiro de quatro bytes assinado | Nenhum |
| SMALLINT | SMALLINT | Número inteiro de dois bytes assinado | Nenhum |
| TINYINT | SMALLINT | Número inteiro de dois bytes assinado | Nenhum |
| MEDIUMINT | INTEGER | Número inteiro de quatro bytes assinado | Nenhum |
| BIGINT | BIGINT | Número inteiro de oito bytes assinado | Nenhum |
| INT UNSIGNED | BIGINT | Número inteiro de oito bytes assinado | Nenhum |
| TINYINT UNSIGNED | SMALLINT | Número inteiro de dois bytes assinado | Nenhum |
| MEDIUMINT UNSIGNED | INTEGER | Número inteiro de quatro bytes assinado | Nenhum |
| BIGINT UNSIGNED | DECIMAL(20,0) | Numérico exato com precisão selecionável | Nenhum |
| DECIMAL(p,s) = NUMERIC(p,s) | DECIMAL (p,s) | Numérico exato com precisão selecionável |
Precisão maior que 38 e escala maior que 37 não são aceitas |
| DECIMAL(p,s) UNSIGNED = NUMERIC(p,s) UNSIGNED | DECIMAL (p,s) | Numérico exato com precisão selecionável |
Precisão maior que 38 e escala maior que 37 não são aceitas |
| FLOAT4/REAL | REAL | Número de ponto flutuante de precisão simples | Nenhum |
| FLOAT4/REAL UNSIGNED | REAL | Número de ponto flutuante de precisão simples | Nenhum |
| DOUBLE/REAL/FLOAT8 | DOUBLE PRECISION | Número de ponto flutuante de precisão dupla | Nenhum |
| DOUBLE/REAL/FLOAT8 UNSIGNED | DOUBLE PRECISION | Número de ponto flutuante de precisão dupla | Nenhum |
| BIT (n) | VARBYTE(8) | Valor binário de comprimento variável | Nenhum |
| BINARY(n) | VARBYTE(n) | Valor binário de comprimento variável | Nenhum |
| VARBINARY (n) | VARBYTE(n) | Valor binário de comprimento variável | Nenhum |
| CHAR (n) | VARCHAR(n) | Valor de string de comprimento variável | Nenhum |
| VARCHAR(n) | VARCHAR(n) | Valor de string de comprimento variável | Nenhum |
| TEXT | VARCHAR(65535) | Valor de string de comprimento variável de até 65.535 caracteres | Nenhum |
| TINYTEXT | VARCHAR(255) | Valor de string de comprimento variável de até 255 caracteres | Nenhum |
| MEDIUMTEXT | VARCHAR(65535) | Valor de string de comprimento variável de até 65.535 caracteres | Nenhum |
| LONGTEXT | VARCHAR(65535) | Valor de string de comprimento variável de até 65.535 caracteres | Nenhum |
| ENUM | VARCHAR(1020) | Valor de string de comprimento variável de até 1.020 caracteres | Nenhum |
| SET | VARCHAR(1020) | Valor de string de comprimento variável de até 1.020 caracteres | Nenhum |
| DATE | DATE | Data de calendário (ano, mês, dia) | Nenhum |
| DATETIME | TIMESTAMP | Data e hora (sem fuso horário) | Nenhum |
| TIMESTAMP(p) | TIMESTAMP | Data e hora (sem fuso horário) | Nenhum |
| TIME | VARCHAR(18) | Valor de string de comprimento variável de até 18 caracteres | Nenhum |
| YEAR | VARCHAR(4) | Valor de string de comprimento variável de até 4 caracteres | Nenhum |
| JSON | SUPER | Dados ou documentos semiestruturados como valores | Nenhum |
RDS para PostgreSQL
As Integrações ETL zero para o RDS para PostgreSQL não são compatíveis com tipos de dados personalizados nem tipos de dados criados por extensões.
| Tipo de dados do RDS PostgreSQL | Tipo de dados do Amazon Redshift | Descrição | Limitações |
|---|---|---|---|
| array | SUPER | Dados ou documentos semiestruturados como valores | Nenhum |
| bigint | BIGINT | Número inteiro de oito bytes assinado | Nenhum |
| bigserial | BIGINT | Número inteiro de oito bytes assinado | Nenhum |
| bit variável (n) | VARBYTE(n) | Valor de binário de tamanho variável de até 16.777.216 bytes | Nenhum |
| bit(n) | VARBYTE(n) | Valor de binário de tamanho variável de até 16.777.216 bytes | Nenhum |
| bit, bit varying | VARBYTE(16777216) | Valor de binário de tamanho variável de até 16.777.216 bytes | Nenhum |
| booleano | BOOLEAN | Booliano lógico (verdadeiro/falso) | Nenhum |
| bytea | VARBYTE(16777216) | Valor de binário de tamanho variável de até 16.777.216 bytes | Nenhum |
| char(n) | CHAR (n) | Valor de string de caracteres de tamanho fixo de até 65.535 bytes | Nenhum |
| char varying(n) | VARCHAR(65535) | Valor de string de caracteres de comprimento variável de até 65.535 caracteres | Nenhum |
| cid | BIGINT |
Número inteiro de oito bytes assinado |
Nenhum |
| cidr |
VARCHAR(19) |
Valor de string de comprimento variável de até 19 caracteres |
Nenhum |
| date | DATE | Data de calendário (ano, mês, dia) |
Valores maiores do que 294.276 d.C. não são aceitos. |
| double precision | DOUBLE PRECISION | Números de ponto flutuante de precisão dupla | Valores abaixo do normal não são totalmente aceitos. |
|
gtsvector |
VARCHAR(65535) |
Valor de string de comprimento variável de até 65.535 caracteres |
Nenhum |
| inet |
VARCHAR(19) |
Valor de string de comprimento variável de até 19 caracteres |
Nenhum |
| integer | INTEGER | Número inteiro de quatro bytes assinado | Nenhum |
|
int2vector |
SUPER | Dados ou documentos semiestruturados como valores. | Nenhum |
| intervalo | INTERVAL | Duração | Somente os tipos de INTERVAL que especificam um qualificador de ano a mês ou de dia a segundo são aceitos. |
| json | SUPER | Dados ou documentos semiestruturados como valores | Nenhum |
| jsonb | SUPER | Dados ou documentos semiestruturados como valores | Nenhum |
| jsonpath | VARCHAR(65535) | Valor de string de comprimento variável de até 65.535 caracteres | Nenhum |
|
macaddr |
VARCHAR(17) | Valor de string de comprimento variável de até 17 caracteres | Nenhum |
|
macaddr8 |
VARCHAR(23) | Valor de string de comprimento variável de até 23 caracteres | Nenhum |
| money | DECIMAL(20,3) | Valor da moeda | Nenhum |
| name | VARCHAR(64) | Valor de string de comprimento variável de até 64 caracteres | Nenhum |
| numeric(p,s) | DECIMAL (p,s) | Valor fixo de precisão definido pelo usuário |
|
| oid | BIGINT | Número inteiro de oito bytes assinado | Nenhum |
| oidvector | SUPER | Dados ou documentos semiestruturados como valores. | Nenhum |
| pg_brin_bloom_summary | VARCHAR(65535) | Valor de string de comprimento variável de até 65.535 caracteres | Nenhum |
| pg_dependencies | VARCHAR(65535) | Valor de string de comprimento variável de até 65.535 caracteres | Nenhum |
| pg_lsn | VARCHAR(17) | Valor de string de comprimento variável de até 17 caracteres | Nenhum |
| pg_mcv_list | VARCHAR(65535) | Valor de string de comprimento variável de até 65.535 caracteres | Nenhum |
| pg_ndistinct | VARCHAR(65535) | Valor de string de comprimento variável de até 65.535 caracteres | Nenhum |
| pg_node_tree | VARCHAR(65535) | Valor de string de comprimento variável de até 65.535 caracteres | Nenhum |
| pg_snapshot | VARCHAR(65535) | Valor de string de comprimento variável de até 65.535 caracteres | Nenhum |
| real | REAL | Número de ponto flutuante de precisão simples | Valores abaixo do normal não são totalmente aceitos. |
| refcursor | VARCHAR(65535) | Valor de string de comprimento variável de até 65.535 caracteres | Nenhum |
| smallint | SMALLINT | Número inteiro de dois bytes assinado | Nenhum |
| smallserial | SMALLINT | Número inteiro de dois bytes assinado | Nenhum |
| serial | INTEGER | Número inteiro de quatro bytes assinado | Nenhum |
| texto | VARCHAR(65535) | Valor de string de comprimento variável de até 65.535 caracteres | Nenhum |
| tid | VARCHAR(23) | Valor de string de comprimento variável de até 23 caracteres | Nenhum |
| hora [(p)] sem fuso horário | VARCHAR(19) | Valor de string de comprimento variável de até 19 caracteres | Os valores Infinity e -Infinity não são aceitos. |
| hora [(p)] com fuso horário | VARCHAR(22) | Valor de string de comprimento variável de até 22 caracteres | Os valores Infinity e -Infinity não são aceitos. |
| carimbo de data/hora [(p)] sem fuso horário | TIMESTAMP | Data e hora (sem fuso horário) |
|
| carimbo de data e hora [(p)] com fuso horário | TIMESTAMPTZ | Data e hora (com fuso horário) |
|
| tsquery | VARCHAR(65535) | Valor de string de comprimento variável de até 65.535 caracteres | Nenhum |
| tsvector | VARCHAR(65535) | Valor de string de comprimento variável de até 65.535 caracteres | Nenhum |
| txid_snapshot | VARCHAR(65535) | Valor de string de comprimento variável de até 65.535 caracteres | Nenhum |
| uuid | VARCHAR(36) | String de 36 caracteres de comprimento variável | Nenhum |
| xid | BIGINT | Número inteiro de oito bytes assinado | Nenhum |
| xid8 | DECIMAL(20, 0) | Decimal de precisão fixa | Nenhum |
| xml | VARCHAR(65535) | Valor de string de comprimento variável de até 65.535 caracteres | Nenhum |
RDS para Oracle
Tipos de dados incompatíveis
Não é possível usar os seguintes tipos de dados do RDS para Oracle no Amazon Redshift:
-
ANYDATA -
BFILE -
REF -
ROWID -
UROWID -
VARRAY -
SDO_GEOMETRY -
Tipos de dados definidos pelo usuário
Diferenças entre os tipos de dados
A tabela a seguir mostra as diferenças entre os tipos de dados que afetam uma Integração ETL zero quando o RDS para Oracle é a origem e o Amazon Redshift é o destino.
| Tipo de dados do RDS para Oracle | Tipo de dados do Amazon Redshift |
|---|---|
|
BINARY_FLOAT |
FLOAT4 |
|
BINARY_DOUBLE |
FLOAT8 |
|
BINARY |
VARCHAR (tamanho) |
|
FLOAT (P) |
Se a precisão for =< 24, então FLOAT4. Se a precisão for > 24, então FLOAT8. |
|
NUMBER (P,S) |
Se a escala for => 0 and =< 37, então NUMERIC (p,s). Se a escala for => 38 e =< 127, então VARCHAR (tamanho). Se a escala for 0:
Se a escala for menor que 0, então INT8. |
|
DATE |
Se a escala for => 0 e =< 6, dependendo do tipo de coluna de destino do Redshift, então uma das seguintes opções:
Se a escala for => 7 e =< 9, então VARCHAR (37). |
|
INTERVAL YEAR TO MONTH |
Se o tamanho for de 1 a 65.535, então VARCHAR (tamanho em bytes). Se o tamanho for de 65.536 a 2.147.483.647, então VARCHAR (65.535). |
|
INTERVAL DAY TO SECOND |
Se o tamanho for de 1 a 65.535, então VARCHAR (tamanho em bytes). Se o tamanho for de 65.536 a 2.147.483.647, então VARCHAR (65.535). |
|
TIMESTAMP |
Se a escala for => 0 e =< 6, dependendo do tipo de coluna de destino do Redshift, então uma das seguintes opções:
Se a escala for => 7 e =< 9, então VARCHAR (37). |
|
TIMESTAMP WITH TIME ZONE |
Se o tamanho for de 1 a 65.535, então VARCHAR (tamanho em bytes). Se o tamanho for de 65.536 a 2.147.483.647, então VARCHAR (65.535). |
|
TIMESTAMP WITH LOCAL TIME ZONE |
Se o tamanho for de 1 a 65.535, então VARCHAR (tamanho em bytes). Se o tamanho for de 65.536 a 2.147.483.647, então VARCHAR (65.535). |
|
CHAR |
Se o tamanho for de 1 a 65.535, então VARCHAR (tamanho em bytes). Se o tamanho for de 65.536 a 2.147.483.647, então VARCHAR (65.535). |
|
VARCHAR2 |
Quando o tamanho é maior que 4.000 bytes, então VARCHAR (tamanho máximo do LOB). O tamanho máximo de LOB não pode exceder 63 KB. O Amazon Redshift não aceita VARCHARs maiores que 64 KB. Quando o tamanho é 4.000 bytes ou menos, então VARCHAR (tamanho em bytes). |
|
NCHAR |
Se o tamanho for de 1 a 65.535, então NVARCHAR (tamanho em bytes). Se o tamanho for de 65.536 a 2.147.483.647, então NVARCHAR (65.535). |
|
NVARCHAR2 |
Quando o tamanho é maior que 4.000 bytes, então NVARCHAR (tamanho máximo do LOB). O tamanho máximo de LOB não pode exceder 63 KB. O Amazon Redshift não aceita VARCHARs maiores que 64 KB. Quando o tamanho é 4.000 bytes ou menos, então NVARCHAR (tamanho em bytes). |
|
RAW |
VARCHAR (tamanho) |
|
REAL |
FLOAT8 |
|
BLOB |
VARCHAR (tamanho máximo de LOB *2) O tamanho máximo de LOB não pode exceder 31 KB. O Amazon Redshift não aceita VARCHARs maiores que 64 KB. |
|
CLOB |
VARCHAR (tamanho máximo de LOB) O tamanho máximo de LOB não pode exceder 63 KB. O Amazon Redshift não aceita VARCHARs maiores que 64 KB. |
|
NCLOB |
NVARCHAR (tamanho máximo de LOB) O tamanho máximo de LOB não pode exceder 63 KB. O Amazon Redshift não aceita VARCHARs maiores que 64 KB. |
|
LONG |
VARCHAR (tamanho máximo de LOB) O tamanho máximo de LOB não pode exceder 63 KB. O Amazon Redshift não aceita VARCHARs maiores que 64 KB. |
|
LONG RAW |
VARCHAR (tamanho máximo de LOB *2) O tamanho máximo de LOB não pode exceder 31 KB. O Amazon Redshift não aceita VARCHARs maiores que 64 KB. |
|
XMLTYPE |
VARCHAR (tamanho máximo de LOB) O tamanho máximo de LOB não pode exceder 63 KB. O Amazon Redshift não aceita VARCHARs maiores que 64 KB. |
Operações de DDL para o RDS para PostgreSQL
Como o Amazon Redshift é derivado do PostgreSQL, ele compartilha vários recursos com o RDS para PostgreSQL porque ambos têm em comum a arquitetura do PostgreSQL. As Integrações ETL zero utilizam essas semelhanças para simplificar a replicação de dados do RDS para PostgreSQL para o Amazon Redshift, associando bancos de dados por nome e utilizando o banco de dados compartilhado, o esquema e a estrutura de tabelas.
Pense nos seguintes pontos ao gerenciar Integrações ETL zero do RDS para PostgreSQL:
-
O isolamento é gerenciado no nível do banco de dados.
-
A replicação ocorre no nível do banco de dados.
-
Os bancos de dados do RDS para PostgreSQL são associados aos bancos de dados do Amazon Redshift por nome, e os dados fluirão para o banco de dados do Redshift renomeado correspondente caso o original seja renomeado.
Apesar de suas semelhanças, o Amazon Redshift e o RDS para PostgreSQL têm diferenças importantes. As seções a seguir descrevem as respostas do sistema do Amazon Redshift para operações comuns de DDL.
Operações do banco de dados
A tabela a seguir mostra as respostas do sistema para operações de DDL do banco de dados.
| Operação de DDL | Resposta do sistema do Redshift |
|---|---|
CREATE DATABASE |
Nenhuma operação |
DROP DATABASE |
O Amazon Redshift descarta todos os dados no banco de dados de destino do Redshift. |
RENAME DATABASE |
O Amazon Redshift descarta todos os dados no banco de dados de destino original e os ressincroniza no novo banco de dados de destino. Se o novo banco de dados não existir, você deverá criá-lo manualmente. Para conferir instruções, consulte Criar bancos de dados de destino no Amazon Redshift. |
Operações de esquema
A tabela a seguir mostra as respostas do sistema para operações de DDL do esquema.
| Operação de DDL | Resposta do sistema do Redshift |
|---|---|
CREATE SCHEMA |
Nenhuma operação |
DROP SCHEMA |
O Amazon Redshift descarta o esquema original. |
RENAME SCHEMA |
O Amazon Redshift descarta o esquema original e ressincroniza os dados no novo esquema. |
Operações de tabela
A tabela a seguir mostra as respostas do sistema para operações de DDL da tabela.
| Operação de DDL | Resposta do sistema do Redshift |
|---|---|
CREATE TABLE |
O Amazon Redshift cria a tabela. Algumas operações fazem com que a criação da tabela falhe, como criar uma tabela sem uma chave primária ou realizar o particionamento declarativo. Para obter mais informações, consulte Limitações e Solução de problemas em Integrações ETL zero do Amazon RDS. |
DROP TABLE |
O Amazon Redshift descarta a tabela. |
TRUNCATE TABLE |
O Amazon Redshift trunca a tabela. |
ALTER TABLE
(RENAME...) |
O Amazon Redshift renomeia a tabela ou a coluna. |
ALTER TABLE (SET
SCHEMA) |
O Amazon Redshift descarta a tabela no esquema original e a ressincroniza no novo esquema. |
ALTER TABLE (ADD PRIMARY
KEY) |
O Amazon Redshift adiciona uma chave primária e ressincroniza a tabela. |
ALTER TABLE (ADD
COLUMN) |
O Amazon Redshift adiciona uma coluna à tabela. |
ALTER TABLE (DROP
COLUMN) |
O Amazon Redshift descartará a coluna se ela não for uma coluna de chave primária. Caso contrário, ele ressincronizará a tabela. |
ALTER TABLE (SET
LOGGED/UNLOGGED) |
Se você alterar a tabela para ativar o registro em log, o Amazon Redshift a ressincronizará. Se você alterar a tabela para desativar o registro em log, o Amazon Redshift a descartará. |
