Filtragem de dados para Integrações ETL zero do Amazon RDS
As Integrações ETL zero do Amazon RDS permitem filtragem de dados, o que possibilita controlar quais dados são replicados do banco de dados do Amazon RDS de origem para o data warehouse de destino. Em vez de replicar todo o banco de dados, você pode aplicar um ou mais filtros para incluir ou excluir seletivamente tabelas específicas. Isso ajuda a otimizar o desempenho do armazenamento e das consultas, garantindo que somente os dados relevantes sejam transferidos. No momento, a filtragem é limitada aos níveis de banco de dados e tabela. Não é possível aplicar filtragem em nível de coluna e linha.
A filtragem de dados pode ser útil quando você deseja:
-
Una determinadas tabelas de dois ou mais bancos de dados de origem diferentes para não precisar de dados completos de nenhum banco de dados.
-
Economize custos realizando análises usando apenas um subconjunto de tabelas em vez de uma frota inteira de bancos de dados.
-
Filtre informações confidenciais, como números de telefone, endereços ou detalhes do cartão de crédito, de determinadas tabelas.
É possível adicionar filtros de dados a uma integração ETL zero usando o Console de gerenciamento da AWS, a AWS Command Line Interface (AWS CLI) ou a API do Amazon RDS.
Se a integração tiver um cluster provisionado como destino, o cluster deverá estar no patch 180 ou posterior para usar a filtragem de dados.
Tópicos
Formato de um filtro de dados
É possível definir vários filtros para uma única integração. Cada filtro inclui ou exclui qualquer tabela de banco de dados existente e futura que corresponda a um dos padrões na expressão do filtro. As integrações ETL zero do Amazon RDS usam a sintaxe de filtro Maxwell
Cada filtro tem os seguintes elementos:
| Elemento | Descrição |
|---|---|
| Tipo de filtro |
Um tipo de filtro |
| Expressão de filtro |
Uma lista separada por vírgulas de padrões. As expressões devem usar a sintaxe de filtro Maxwell |
| Pattern |
Um padrão de filtro no formato notaNo RDS para MySQL, são aceitas expressões regulares em nomes de banco de dados e de tabela. No RDS para PostgreSQL, as expressões regulares são aceitas somente em nomes de esquema e de tabela, não em nomes de banco de dados. Não é possível incluir filtros ao nível da coluna nem listas de bloqueio. Uma única integração pode ter um máximo de 99 padrões no total. No console, é possível inserir padrões em uma única expressão de filtro ou distribuí-los entre várias expressões. Um único padrão não pode exceder 256 caracteres. |
Importante
Se você selecionar um RDS para PostgreSQL, deverá especificar pelo menos um padrão de filtro de dados. O padrão deve incluir no mínimo um banco de dados único (database-name.*.*
A imagem a seguir mostra a estrutura dos filtros de dados do RDS para MySQL no console:
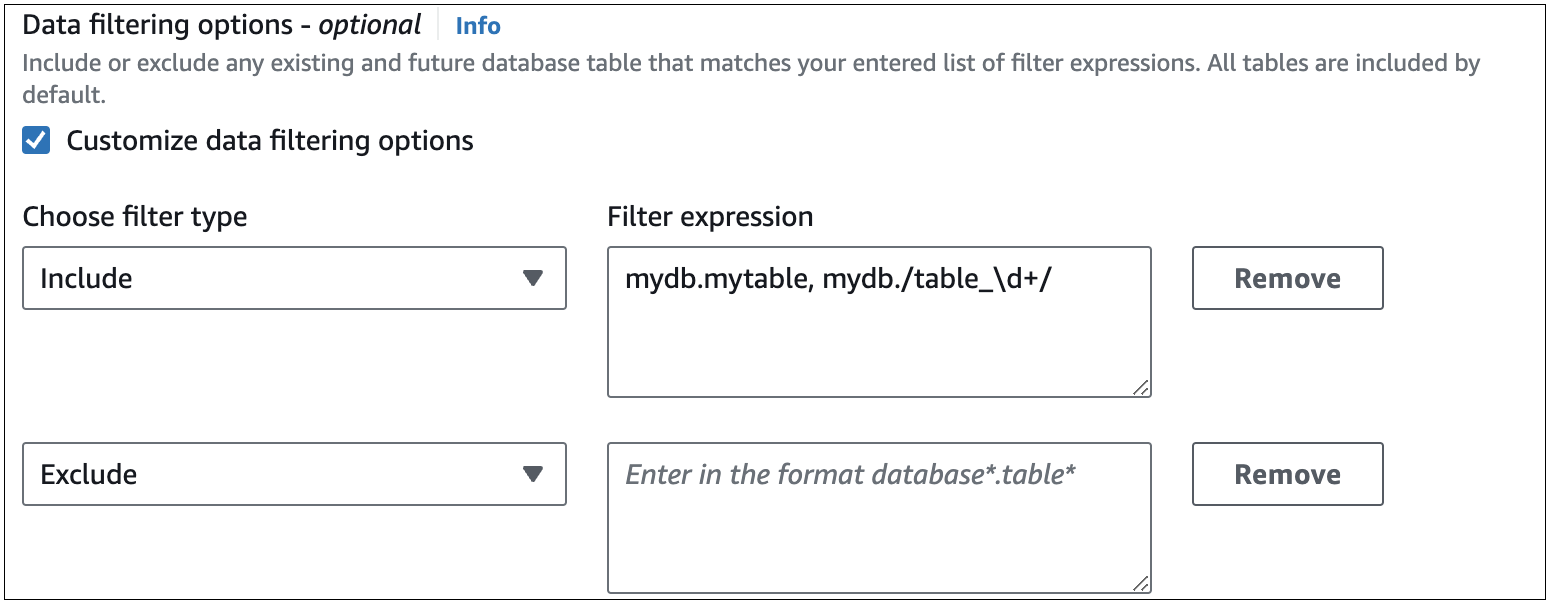
Importante
Não inclua informações pessoais, confidenciais ou sigilosas em seus padrões de filtragem.
Filtros de dados na AWS CLI
Ao usar a AWS CLI para adicionar um filtro de dados, a sintaxe difere um pouco da sintaxe do console. Você deve atribuir um tipo de filtro (Include ou Exclude) a cada padrão individualmente; portanto, não é possível agrupar vários padrões sob um tipo de filtro.
Por exemplo, no console, é possível agrupar os seguintes padrões separados por vírgula em uma única instrução Include:
RDS para MySQL
mydb.mytable,mydb./table_\d+/
RDS para PostgreSQL
mydb.myschema.mytable,mydb.myschema./table_\d+/
No entanto, ao usar a AWS CLI, o mesmo filtro de dados deve estar no seguinte formato:
RDS para MySQL
'include:mydb.mytable, include:mydb./table_\d+/'
RDS para PostgreSQL
'include:mydb.myschema.mytable, include:mydb.myschema./table_\d+/'
Lógica de filtros
Se você não especificar nenhum filtro de dados na integração, o Amazon RDS assumirá o filtro padrão include:*.*, o que replica todas as tabelas no data warehouse de destino. Entretanto, se você adicionar pelo menos um filtro, a lógica padrão mudará para exclude:*.*, o que exclui todas as tabelas por padrão. Isso permite que você defina explicitamente quais bancos de dados e tabelas incluir na replicação.
Por exemplo, se você definir o seguinte filtro:
'include: db.table1, include: db.table2'
O Amazon RDS avaliará o filtro da seguinte forma:
'exclude:*.*, include: db.table1, include: db.table2'
Portanto, o Amazon RDS replica somente a table1 e a table2 do banco de dados denominado db para o data warehouse de destino.
Precedência do filtro
O Amazon RDS avalia os filtros de dados na ordem em que você especificar. No Console de gerenciamento da AWS, ele processa expressões de filtro da esquerda para a direita e de cima para baixo. Um segundo filtro ou um padrão individual subsequente pode substituir o primeiro.
Por exemplo, se o primeiro filtro for Include books.stephenking, ele incluirá somente a tabela stephenking do banco de dados books. No entanto, se você adicionar um segundo filtro, Exclude books.*, ele substituirá o primeiro filtro. Isso impede que qualquer tabela do índice books seja replicada para o data warehouse de destino.
Quando você especifica pelo menos um filtro, a lógica primeiro assume exclude:*.*, o que significa que todas as tabelas são automaticamente excluídas da replicação. Como prática recomendada, defina filtros do mais amplo ao mais específico. Comece com uma ou mais instruções Include para especificar os dados a serem replicados e, em seguida, adicione filtros Exclude para remover seletivamente determinadas tabelas.
O mesmo princípio se aplica aos filtros que você define usando a AWS CLI. O Amazon RDS avalia esses padrões de filtro na ordem em que você os especifica; portanto, um padrão pode substituir um especificado antes dele.
Exemplos do RDS para MySQL
Os seguintes exemplos demonstram como a filtragem de dados funciona para exemplos do RDS para MySQL de Integração ETL zero:
-
Inclua todos os bancos de dados e todas as tabelas:
'include: *.*' -
Inclua todas as tabelas no banco de dados
books:'include: books.*' -
Exclua todas as tabelas chamadas
mystery:'include: *.*, exclude: *.mystery' -
Inclua duas tabelas específicas no banco de dados
books:'include: books.stephen_king, include: books.carolyn_keene' -
Inclua todas as tabelas no banco de dados
books, exceto aquelas que contêm a substringmystery:'include: books.*, exclude: books./.*mystery.*/' -
Inclua todas as tabelas no banco de dados
books, exceto aquelas que começam commystery:'include: books.*, exclude: books./mystery.*/' -
Inclua todas as tabelas no banco de dados
books, exceto aquelas que terminam commystery:'include: books.*, exclude: books./.*mystery/' -
Inclua todas as tabelas no banco de dados
booksque começam comtable_, exceto aquela chamadatable_stephen_king. Por exemplo,table_moviesoutable_booksseria replicada, mas nãotable_stephen_king.'include: books./table_.*/, exclude: books.table_stephen_king'
Exemplos do RDS para PostgreSQL
Os seguintes exemplos demonstram como a filtragem de dados funciona para Integrações ETL zero do RDS para PostgreSQL:
-
Inclua todas as tabelas no banco de dados
books:'include: books.*.*' -
Exclua todas as tabelas denominadas
mysteryno banco de dadosbooks:'include: books.*.*, exclude: books.*.mystery' -
Inclua uma tabela no banco de dados
booksno esquemamysterye uma tabela no banco de dadosemployeeno esquemafinance:'include: books.mystery.stephen_king, include: employee.finance.benefits' -
Inclua todas as tabelas no banco de dados
bookse no esquemascience_fiction, exceto aquelas que contêm a substringking:'include: books.science_fiction.*, exclude: books.*./.*king.*/ -
Inclua todas as tabelas no banco de dados
books, exceto aquelas que têm um nome de esquema que começa comsci:'include: books.*.*, exclude: books./sci.*/.*' -
Inclua todas as tabelas no banco de dados
books, exceto aquelas no esquemamysteryque terminam comking:'include: books.*.*, exclude: books.mystery./.*king/' -
Inclua todas as tabelas no banco de dados
booksque começam comtable_, exceto aquela chamadatable_stephen_king. Por exemplo,table_moviesno esquemafictionetable_booksno esquemamysterysão replicados, mas nãotable_stephen_kingem nenhum dos esquemas:'include: books.*./table_.*/, exclude: books.*.table_stephen_king'
Exemplos do RDS para Oracle
Os seguintes exemplos demonstram como a filtragem de dados funciona para Integrações ETL zero do RDS para Oracle:
-
Inclua todas as tabelas no banco de dados “books”:
'include: books.*.*' -
Exclua todas as tabelas denominadas “mystery” no banco de dados “books”:
'include: books.*.*, exclude: books.*.mystery' -
Inclua uma tabela no banco de dados “books” no esquema “mystery” e uma tabela no banco de dados no esquema “finance”:
'include: books.mystery.stephen_king, include: employee.finance.benefits' -
Inclua todas as tabelas no esquema “mystery” dentro do banco de dados “books”:
'include: books.mystery.*'
Considerações sobre distinção de maiúsculas e minúsculas
O banco de dados Oracle e o Amazon Redshift lidam com maiúsculas e minúsculas de nomes de objetos de forma diferente, o que afeta tanto a configuração do filtro de dados quanto as consultas de destino. Observe o seguinte:
-
O banco de dados Oracle armazena nomes de bancos de dados, esquemas e objetos em maiúsculas, a menos que seja explicitamente citado na instrução
CREATE. Por exemplo, se você criarmytable(sem aspas), o dicionário de dados Oracle armazenará o nome da tabela comoMYTABLE. Se você citar o nome do objeto, o dicionário de dados preservará o tamanho da letra. -
Os filtros de dados ETL zero diferenciam maiúsculas e minúsculas e devem corresponder exatamente às maiúsculas e minúsculas dos nomes dos objetos conforme eles aparecem no dicionário de dados Oracle.
-
As consultas do Amazon Redshift usam como padrão nomes de objetos em minúsculas, a menos que sejam explicitamente citados. Por exemplo, uma consulta de
MYTABLE(sem aspas) procuramytable.
Preste atenção às diferenças de tamanho da letra ao criar o filtro do Amazon Redshift e consultar os dados.
Criar uma integração em maiúsculas
Quando você cria uma tabela sem especificar o nome entre aspas duplas, o banco de dados Oracle armazena o nome em maiúsculas no dicionário de dados. Por exemplo, você pode criar MYTABLE usando qualquer uma das instruções SQL a seguir.
CREATE TABLE REINVENT.MYTABLE (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE reinvent.mytable (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE REinvent.MyTable (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE reINVENT.MYtabLE (id NUMBER PRIMARY KEY, description VARCHAR2(100));
Como você não citou o nome da tabela nas instruções anteriores, o banco de dados Oracle armazena o nome do objeto em maiúsculas como MYTABLE.
Para replicar essa tabela no Amazon Redshift, você deve especificar o nome em maiúsculas no filtro de dados do seu comando create-integration. O nome do filtro ETL zero e o nome do dicionário de dados Oracle devem coincidir.
aws rds create-integration \ --integration-name upperIntegration \ --data-filter "include: ORCL.REINVENT.MYTABLE" \ ...
Por padrão, o Amazon Redshift armazena dados em letras minúsculas. Para consultar MYTABLE no banco de dados replicado no Amazon Redshift, você deve citar o nome MYTABLE em maiúsculas para que coincida com o tamanho da letra no dicionário de dados Oracle.
SELECT * FROM targetdb1."REINVENT"."MYTABLE";
As consultas a seguir não usam o mecanismo de citação. Todas elas exibem um erro porque pesquisam uma tabela do Amazon Redshift chamada mytable, que usa o nome padrão em minúsculas, mas a tabela é denominada MYTABLE no dicionário de dados Oracle.
SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".MyTable; SELECT * FROM targetdb1."REINVENT".mytable;
As consultas a seguir usam o mecanismo de citação para especificar um nome com maiúsculas e minúsculas. Todas as consultas exibem um erro porque pesquisam uma tabela do Amazon Redshift que não se chama MYTABLE.
SELECT * FROM targetdb1."REINVENT"."MYtablE"; SELECT * FROM targetdb1."REINVENT"."MyTable"; SELECT * FROM targetdb1."REINVENT"."mytable";
Criar uma integração em minúsculas
No exemplo alternativo a seguir, você vai usar aspas duplas para armazenar o nome da tabela em minúsculas no dicionário de dados Oracle. Você vai criar mytable da forma a seguir.
CREATE TABLE REINVENT."mytable" (id NUMBER PRIMARY KEY, description VARCHAR2(100));
O banco de dados Oracle armazena o nome da tabela como mytable em letras minúsculas. Para replicar essa tabela no Amazon Redshift, você deve especificar o nome em maiúsculas mytable no filtro de dados ETL zero.
aws rds create-integration \ --integration-name lowerIntegration \ --data-filter "include: ORCL.REINVENT.mytable" \ ...
Ao consultar essa tabela no banco de dados replicado no Amazon Redshift, você pode especificar o nome mytable em minúsculas. A consulta é bem-sucedida porque procura uma tabela chamadamytable, que é o nome da tabela no dicionário de dados Oracle.
SELECT * FROM targetdb1."REINVENT".mytable;
Como o Amazon Redshift usa como padrão nomes de objetos em minúsculas, as consultas a seguir também conseguem encontrar mytable.
SELECT * FROM targetdb1."REINVENT".MYtablE; SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".MyTable;
As consultas a seguir usam o mecanismo de citação para o nome do objeto. Todas elas exibem um erro porque pesquisam uma tabela do Amazon Redshift cujo nome é diferente de mytable.
SELECT * FROM targetdb1."REINVENT"."MYTABLE"; SELECT * FROM targetdb1."REINVENT"."MyTable"; SELECT * FROM targetdb1."REINVENT"."MYtablE";
Criar uma tabela com uma integração em maiúsculas e minúsculas
No exemplo a seguir, você vai usar aspas duplas para armazenar o nome da tabela em minúsculas no dicionário de dados Oracle. Você vai criar MyTable da forma a seguir.
CREATE TABLE REINVENT."MyTable" (id NUMBER PRIMARY KEY, description VARCHAR2(100));
O banco de dados Oracle armazena esse nome de tabela como MyTable com letras maiúsculas e minúsculas. Para replicar essa tabela no Amazon Redshift, você deve especificar o nome em maiúsculas e minúsculas no filtro de dados.
aws rds create-integration \ --integration-name mixedIntegration \ --data-filter "include: ORCL.REINVENT.MyTable" \ ...
Ao consultar essa tabela no banco de dados replicado no Amazon Redshift, você deve especificar o nome MyTable em maiúsculas e minúsculas, citando o nome do objeto.
SELECT * FROM targetdb1."REINVENT"."MyTable";
Como o Amazon Redshift usa como padrão nomes de objetos em minúsculas, as consultas a seguir não encontram o objeto porque estão procurando pelo nome mytable em minúsculas.
SELECT * FROM targetdb1."REINVENT".MYtablE; SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".mytable;
nota
Não é possível usar expressões regulares no valor de filtro para nome de banco de dados, esquema ou nome de tabela em integrações do RDS para Oracle.
Adicionar filtros de dados a uma integração
É possível configurar a filtragem de dados usando o Console de gerenciamento da AWS, a AWS CLI ou a API do Amazon RDS.
Importante
Se você adicionar um filtro depois de criar uma integração, o Amazon RDS o tratará como se ele sempre tivesse existido. Ele remove quaisquer dados no data warehouse de destino que não correspondam aos novos critérios de filtragem e ressincroniza todas as tabelas afetadas.
Para adicionar filtros de dados para uma integração ETL zero
Faça login no Console de gerenciamento da AWS e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
No painel de navegação, escolha Integrações ETL zero. Selecione a integração à qual você deseja adicionar filtros de dados e escolha Modificar.
-
Em Fonte, adicione uma ou mais instruções
ExcludeeInclude.A seguinte imagem mostra um exemplo de filtros de dados para uma integração do MySQL:
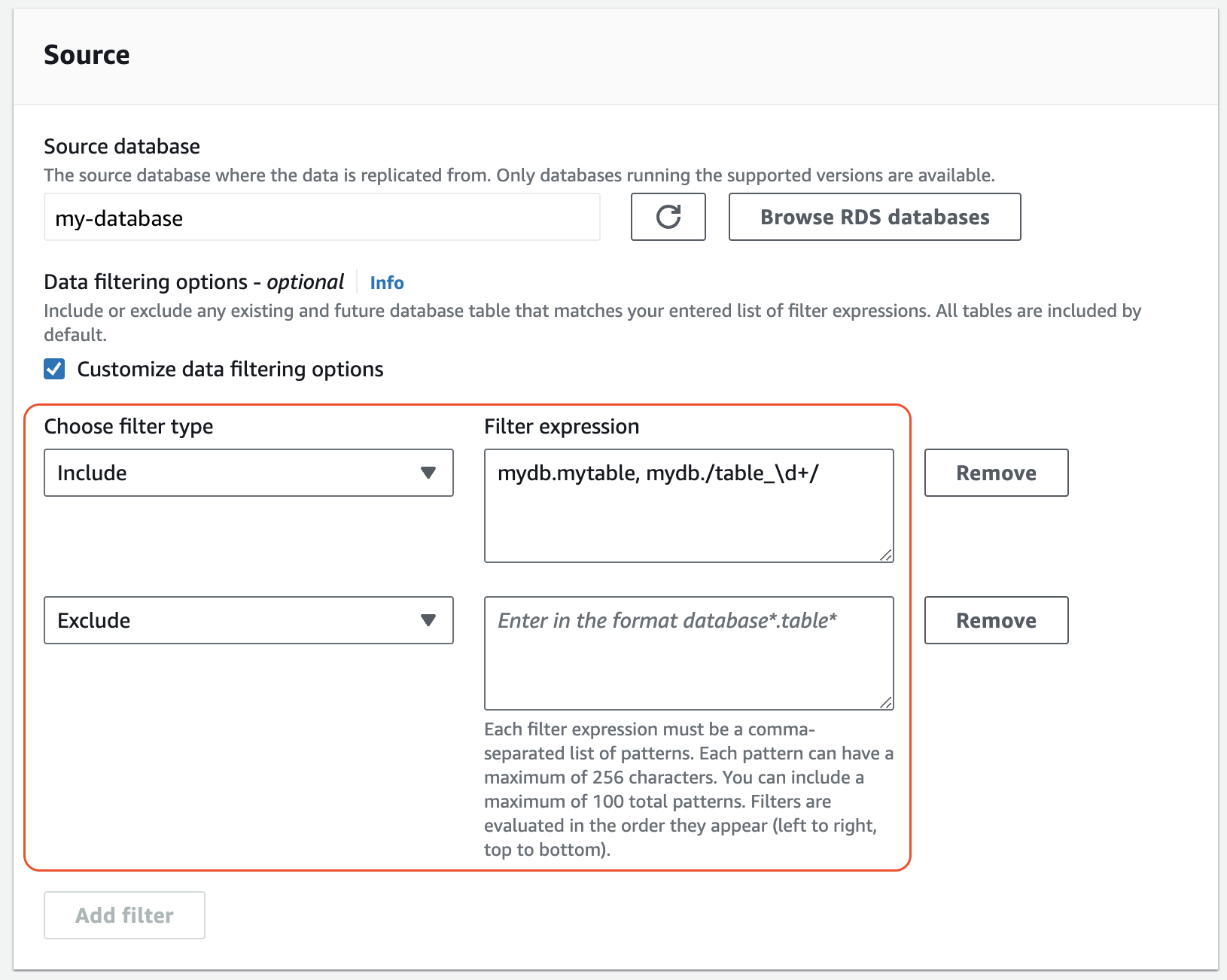
-
Quando as alterações estiverem adequadas para você, escolha Continuar e Salvar alterações.
Para adicionar filtros de dados a uma integração ETL zero usando a AWS CLI, chame o comando modify-integration--data-filter com uma lista separada por vírgulas dos filtros Maxwell Include e Exclude.
exemplo
O exemplo a seguir adiciona padrões de filtro a my-integration.
Para Linux, macOS ou Unix:
aws rds modify-integration \ --integration-identifiermy-integration\ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
Para Windows:
aws rds modify-integration ^ --integration-identifiermy-integration^ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
Para modificar uma integração ETL zero usando a API do RDS, chame a operação ModifyIntegration. Especifica o identificador de integração e fornece uma lista separada por vírgulas de padrões de filtro.
Remover filtros de dados de uma integração
Quando você remove um filtro de dados de uma integração, o Amazon RDS reavalia os filtros restantes como se o filtro removido nunca tivesse existido. Em seguida, ele replica quaisquer dados anteriormente excluídos que agora atendem aos critérios no data warehouse de destino. Isso aciona uma ressincronização de todas as tabelas afetadas.
