Deadlocks distribuídos no Aurora PostgreSQL Limitless Database
Em um grupo de fragmentos de banco de dados, podem ocorrer deadlocks entre transações distribuídas entre diferentes roteadores e fragmentos. Por exemplo, duas transações distribuídas simultâneas que abrangem dois fragmentos são executadas, conforme apresentado na figura a seguir.
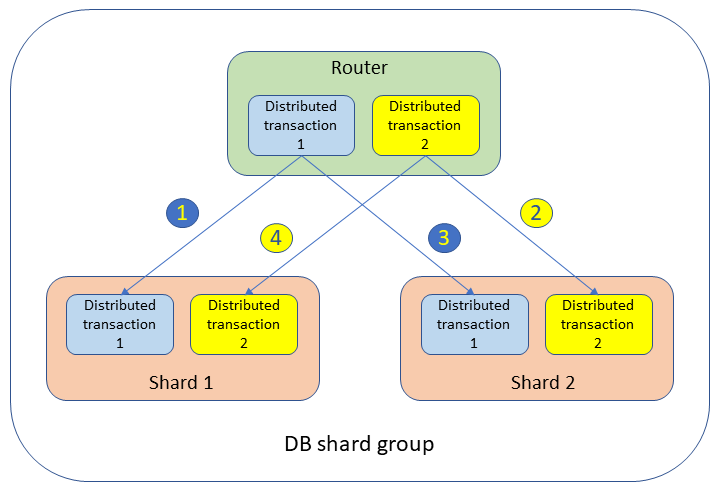
As transações bloqueiam tabelas e criam eventos de espera nos dois fragmentos da seguinte forma:
-
Transação distribuída 1:
UPDATEtableSETvalue= 1 WHERE key = 'shard1_key';Isso mantém um bloqueio no fragmento 1.
-
Transação distribuída 2:
UPDATEtableSETvalue= 2 WHERE key = 'shard2_key';Isso mantém um bloqueio no fragmento 2.
-
Transação distribuída 1:
UPDATEtableSETvalue= 3 WHERE key = 'shard2_key';A transação distribuída 1 está aguardando o fragmento 2.
-
Transação distribuída 2:
UPDATEtableSETvalue= 4 WHERE key = 'shard1_key';A transação distribuída 2 está aguardando o fragmento 1.
Nesse cenário, nem o fragmento 1 nem o fragmento 2 veem o problema: a transação 1 está aguardando a transação 2 no fragmento 2 e a transação 2 está aguardando a transação 1 no fragmento 1. De uma visão global, a transação 1 está aguardando a transação 2 e a transação 2 está aguardando a transação 1. Essa situação em que duas transações em dois fragmentos diferentes estão esperando uma pela outra é chamada de deadlock distribuído.
O Aurora PostgreSQL Limitless Database pode detectar e resolver deadlocks distribuídos automaticamente. Um roteador no grupo de fragmentos de banco de dados é notificado quando uma transação está esperando muito tempo para adquirir um recurso. O roteador que recebe a notificação começa a coletar as informações necessárias de todos os roteadores e fragmentos dentro do grupo de fragmentos de banco de dados. O roteador então finaliza as transações que estão participando de um deadlock distribuído, até que as demais transações no grupo de fragmentos de banco de dados possam prosseguir sem serem bloqueadas umas pelas outras.
Você recebe o seguinte erro quando sua transação faz parte de um deadlock distribuído e é encerrada pelo roteador:
ERROR: aborting transaction participating in a distributed deadlock
O parâmetro do cluster de banco de dados rds_aurora.limitless_distributed_deadlock_timeout define o tempo de espera de cada transação em um recurso antes de notificar o roteador para verificar se há um deadlock distribuído. É possível aumentar o valor do parâmetro se a workload for menos propensa a situações de deadlock. O padrão é 1000 milissegundos (1 segundo).
O ciclo de deadlock distribuído é publicado nos logs do PostgreSQL quando um deadlock entre nós é encontrado e resolvido. As informações sobre cada processo que faz parte do deadlock incluem o seguinte:
-
Nó coordenador que iniciou a transação
-
ID de transação virtual (xid) da transação no nó coordenador, no formato
backend_id/backend_local_xid -
ID de sessão distribuída da transação
