Criar um cluster de banco de dados
Use os procedimentos a seguir para criar um cluster de banco de dados do Aurora PostgreSQL que use o Aurora PostgreSQL Limitless Database.
Você pode usar o Console de gerenciamento da AWS ou a AWS CLI para criar um cluster de banco de dados que usa o Aurora PostgreSQL Limitless Database. Você cria o cluster de banco de dados primário e o grupo de fragmentos de banco de dados.
Quando você usa o Console de gerenciamento da AWS para criar o cluster de banco de dados primário, o grupo de fragmentos de banco de dados também é criado no mesmo procedimento.
Como criar um cluster de banco de dados usando o console
Faça login no Console de gerenciamento da AWS e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
Escolha Create database (Criar banco de dados).
A página Criar banco de dados é exibida.
-
Em Tipo de mecanismo, escolha Aurora (compatível com PostgreSQL).
-
Em Versão, escolha uma das seguintes opções:
-
Aurora PostgreSQL com Limitless Database (compatível com PostgreSQL 16.4)
-
Aurora PostgreSQL com Limitless Database (compatível com PostgreSQL 16.6)
-
-
Em Aurora PostgreSQL Limitless Database:
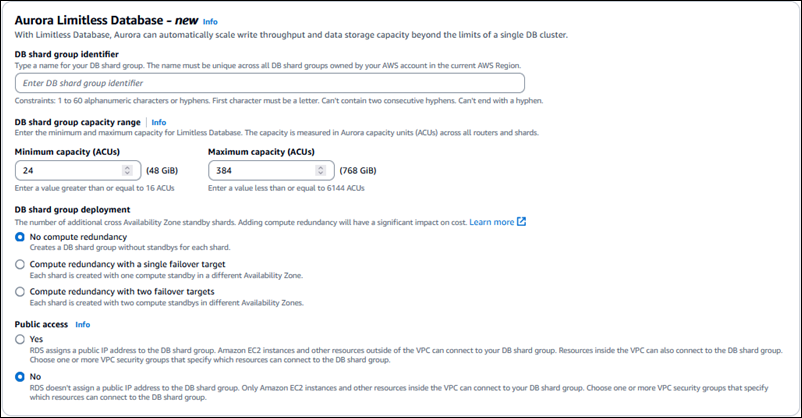
-
Insira um Identificador do grupo de fragmentos de banco de dados.
Importante
Depois de criar o grupo de fragmentos de banco de dados, não é possível alterar o identificador do cluster de banco de dados ou o identificador do grupo de fragmentos de banco de dados.
-
Em Faixa de capacidade do grupo de fragmentos de banco de dados:
-
Insira a Capacidade mínima (ACUs). Use um valor de pelo menos 16 ACUs.
Para um ambiente de desenvolvimento, o valor padrão é 16 ACUs. Para um ambiente de produção, o valor padrão é 24 ACUs.
-
Insira a Capacidade máxima (ACUs). Use um valor de pelo menos 16 ACUs ou no máximo 6.144 ACUs.
Para um ambiente de desenvolvimento, o valor padrão é 64 ACUs. Para um ambiente de produção, o valor padrão é 384 ACUs.
Para obter mais informações, consulte Correlação da capacidade máxima do grupo de fragmentos de banco de dados com o número de roteadores e fragmentos criados.
-
-
Em Implantação de grupos de fragmentos de banco de dados, escolha se deseja criar standbys para o grupo de fragmentos de banco de dados:
-
Sem redundância computacional: cria um grupo de fragmentos de banco de dados sem standbys para cada fragmento. Este é o valor padrão.
-
Redundância computacional com um único destino de failover: cria um grupo de fragmentos de banco de dados com um standby computacional em uma zona de disponibilidade (AZ) diferente.
-
Redundância computacional com dois destinos de failover: cria um grupo de fragmentos de banco de dados com dois standbys computacionais em duas AZs diferentes.
nota
Se você definir a redundância de computação com um valor diferente de zero, o número total de fragmentos será dobrado ou triplicado. Essas instâncias extras de banco de dados são instâncias de computação em espera que têm a escala aumentada e reduzida verticalmente de acordo com a mesma capacidade do gravador. Você não define a faixa de capacidade separadamente para os standbys. Portanto, o uso e o faturamento de ACU dobram e triplicam correspondentemente. Para saber qual é o uso exato de ACU resultante da redundância de computação, consulte a métrica
DBShardGroupComputeRedundancyCapacityem Métricas do DBShardGroup. -
-
Escolha se deseja tornar o grupo de fragmentos de banco de dados acessível publicamente.
nota
Não é possível modificar essa configuração após criar o grupo de fragmentos de banco de dados.
-
-
Em Conectividade:
-
(Opcional) Selecione Conectar-se a um recurso computacional do EC2 e, em seguida, escolha uma instância existente do EC2 ou crie uma.
nota
Se você se conectar a uma instância do EC2, não poderá tornar o grupo de fragmentos de banco de dados acessível publicamente.
-
Em Tipo de rede, escolha IPv4 ou Modo de pilha dupla.
-
Escolha a Nuvem privada virtual (VPC) e o Grupo de sub-redes de banco de dados, ou use as configurações padrão.
nota
Se você criar um cluster de banco de dados do Limitless Database na região Leste dos EUA (Norte da Virgínia), não inclua a zona de disponibilidade (AZ)
us-east-1eno grupo de sub-redes de banco de dados. Devido às limitações de recursos, o Aurora serverless (e, portanto, o Limitless Database) não é compatível na AZus-east-1e. -
Escolha o Grupo de segurança da VPC (firewall) ou use a configuração padrão.
-
-
Em Autenticação de banco de dados, escolha Autenticação de senha ou Autenticação de senha e do banco de dados do IAM.
-
Em Monitoramento, certifique-se de que as caixas de seleção Ativar o Performance Insights e Habilitar monitoramento avançado estejam marcadas.
Para Insights de Performance, escolha um tempo de retenção de pelo menos 1 mês.
-
Expanda Configuração adicional na parte inferior da página.
-
Em Exportações de log, certifique-se de que a caixa de seleção Log do PostgreSQL esteja marcada.
-
Especifique outras configurações conforme necessário. Para obter mais informações, consulte Configurações de clusters de bancos de dados do Aurora.
-
Selecione Criar banco de dados.
Após a criação do cluster de banco de dados primário e do grupo de fragmentos de banco de dados, eles são exibidos na página Bancos de dados.

Ao usar a AWS CLI para criar um cluster de banco de dados que usa o Aurora PostgreSQL Limitless Database, você executa as seguintes tarefas:
Criar o cluster de banco de dados primário
Os seguintes parâmetros são necessários para criar o cluster de banco de dados:
-
--db-cluster-identifier: o nome de seu cluster de banco de dados. -
--engine: o cluster de banco de dados deve usar o mecanismo de banco de dadosaurora-postgresql. -
--engine-version: o cluster de banco de dados deve usar uma das versões do mecanismo de banco de dados:-
16.4-limitless -
16.6-limitless
-
-
--storage-type: o cluster de banco de dados deve usar a configuração de armazenamentoaurora-iopt1do cluster de banco de dados. -
--cluster-scalability-type: especifica o modo de escalabilidade do cluster de banco de dados do Aurora. Quando definido comolimitless, o cluster opera como um Aurora PostgreSQL Limitless Database. Quando definido comostandard(o padrão), o cluster usa a criação normal de instância de banco de dados.nota
Não é possível modificar essa configuração após a criação do cluster de banco de dados.
-
--master-username: o nome do usuário principal do cluster de banco de dados. -
--master-user-password: a senha do usuário principal. -
--enable-performance-insights: é necessário habilitar o Insights de Performance. -
--performance-insights-retention-period: o período de retenção do Insights de Performance deve ser de pelo menos 31 dias. -
--monitoring-interval: o intervalo, em segundos, entre os pontos quando as métricas do Monitoramento aprimorado são coletadas para o cluster de banco de dados. Esse valor não pode ser0. -
--monitoring-role-arn: o nome do recurso da Amazon (ARN) do perfil do IAM que permite que o RDS envie métricas do - para o Amazon CloudWatch Logs. -
--enable-cloudwatch-logs-exports: você deve exportar logspostgresqlpara o CloudWatch Logs.
Os seguintes parâmetros são opcionais:
-
--db-subnet-group-name: o grupo de sub-redes de banco de dados a ser associado ao cluster de banco de dados. Isso também determina a VPC associada ao cluster de banco de dados.nota
Se você criar um cluster de banco de dados do Limitless Database na região Leste dos EUA (Norte da Virgínia), não inclua a zona de disponibilidade (AZ)
us-east-1eno grupo de sub-redes de banco de dados. Devido às limitações de recursos, o Aurora serverless (e, portanto, o Limitless Database) não é compatível na AZus-east-1e. -
--vpc-security-group-ids: uma lista de grupos de segurança da VPC para associar ao cluster de banco de dados. -
--performance-insights-kms-key-id: o identificador da AWS KMS key para criptografia de dados do Insights de Performance. Se você não especificar uma chave do KMS, a chave padrão da sua Conta da AWS será usada. -
--region: a Região da AWS onde você cria o cluster de banco de dados. Ela deve ser compatível com o Aurora PostgreSQL Limitless Database.
Para usar a VPC padrão e o grupo de segurança da VPC, omita as opções --db-subnet-group-name e --vpc-security-group-ids.
Como criar o cluster de banco de dados primário
-
aws rds create-db-cluster \ --db-cluster-identifiermy-limitless-cluster\ --engine aurora-postgresql \ --engine-version 16.6-limitless \ --storage-type aurora-iopt1 \ --cluster-scalability-type limitless \ --master-usernamemyuser\ --master-user-passwordmypassword\ --db-subnet-group-namemysubnetgroup\ --vpc-security-group-idssg-c7e5b0d2\ --enable-performance-insights \ --performance-insights-retention-period31\ --monitoring-interval5\ --monitoring-role-arn arn:aws:iam::123456789012:role/EMrole\ --enable-cloudwatch-logs-exports postgresql
Para obter mais informações, consulte create-db-cluster
Criar o grupo de fragmentos de banco de dados
Em seguida, você cria o grupo de fragmentos de banco de dados no cluster de banco de dados que acabou de criar. Os seguintes parâmetros são obrigatórios:
-
--db-shard-group-identifier: o nome do grupo de fragmentos de banco de dados.O identificador do grupo de fragmentos de banco de dados tem as seguintes restrições:
-
Ele deve ser exclusivo na Conta da AWS e Região da AWS em que você o criou.
-
Deve conter de 1 a 63 letras, números ou hifens.
-
O primeiro caractere deve ser uma letra.
-
Não pode terminar com um hífen ou conter dois hífens consecutivos.
-
Importante
Depois de criar o grupo de fragmentos de banco de dados, não é possível alterar o identificador do cluster de banco de dados ou o identificador do grupo de fragmentos de banco de dados.
-
-
--db-cluster-identifier: o nome do cluster de banco de dados no qual você está criando o grupo de fragmentos de banco de dados. -
--max-acu: a capacidade máxima do grupo de fragmentos de banco de dados. Deve ser de 16 a 6.144 ACUs. Para limites de capacidade superiores a 6.144 ACUs, entre em contato com a AWS.O número inicial de roteadores e fragmentos é determinado pela capacidade máxima que você define ao criar o grupo de fragmentos de banco de dados. Quanto maior a capacidade máxima, maior o número de roteadores e fragmentos criados no grupo de fragmentos de banco de dados. Para obter mais informações, consulte Correlação da capacidade máxima do grupo de fragmentos de banco de dados com o número de roteadores e fragmentos criados.
Os seguintes parâmetros são opcionais:
-
--compute-redundancy: se deve criar standbys para o grupo de fragmentos de banco de dados. Esse parâmetro pode ter um dos seguintes valores:-
0: cria um grupo de fragmentos de banco de dados sem standbys para cada fragmento. Este é o valor padrão. -
1: cria um grupo de fragmentos de banco de dados com um standby computacional em uma zona de disponibilidade (AZ) diferente. -
2: cria um grupo de fragmentos de banco de dados com dois standbys computacionais em duas AZs diferentes.
nota
Se você definir a redundância computacional para um valor diferente de zero, o número total de fragmentos será dobrado ou triplicado. Isso incorrerá em custos adicionais.
Os nós em standbys computacionais têm a escala aumentada e reduzida verticalmente de acordo com a mesma capacidade do gravador. Você não define a faixa de capacidade separadamente para os standbys.
-
-
--min-acu: a capacidade mínima do grupo de fragmentos de banco de dados. Deve ser de pelo menos 16 ACUs, que é o valor padrão. -
--publicly-accessible|--no-publicly-accessible: se devem ser atribuídos endereços IP acessíveis publicamente ao grupo de fragmentos de banco de dados. O acesso ao grupo de fragmentos de banco de dados é controlado pelos grupos de segurança usados pelo cluster.O padrão é
--no-publicly-accessible.nota
Não é possível modificar essa configuração após criar o grupo de fragmentos de banco de dados.
Como criar o grupo de fragmentos de banco de dados
-
aws rds create-db-shard-group \ --db-shard-group-identifiermy-db-shard-group\ --db-cluster-identifier my-limitless-cluster \ --max-acu1000
