Arquitetura do Aurora PostgreSQL Limitless Database
O Limitless Database alcança escala com uma arquitetura de duas camadas que consiste em vários nós de banco de dados. Os nós são roteadores ou fragmentos.
-
Os fragmentos são instâncias de banco de dados do Aurora PostgreSQL que armazenam cada uma um subconjunto dos dados do seu banco de dados, permitindo o processamento simultâneo para obter maior taxa de throughput de gravação.
-
Os roteadores gerenciam a natureza distribuída do banco de dados e apresentam uma única imagem do banco de dados aos clientes do banco de dados. Os roteadores mantêm metadados sobre onde os dados são armazenados, analisam os comandos SQL recebidos e enviam esses comandos para os fragmentos. Em seguida, eles agregam dados dos fragmentos para retornar um único resultado ao cliente e gerenciam transações distribuídas para manter a consistência em todo o banco de dados distribuído.
O Aurora PostgreSQL Limitless Database difere de clusters de bancos de dados Aurora padrão por ter um grupo de fragmentos de banco de dados em vez de uma instância de banco de dados do gravador e instâncias de banco de dados do leitor. Todos os nós que compõem a arquitetura do Limitless Database estão contidos no grupo de fragmentos de banco de dados. Os fragmentos e roteadores individuais no grupo de fragmentos de banco de dados não estão visíveis na sua Conta da AWS. Você usa o endpoint do cluster de banco de dados para acessar o Limitless Database.
A figura a seguir mostra a arquitetura de alto nível do Aurora PostgreSQL Limitless Database.
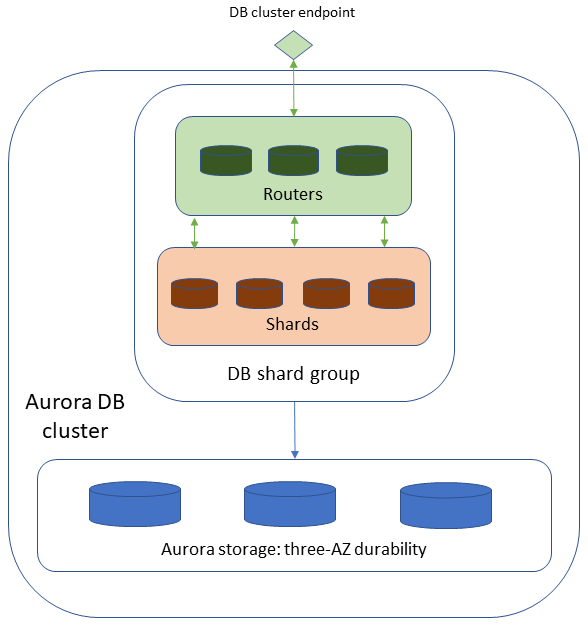
Para obter mais informações sobre a arquitetura do Aurora PostgreSQL Limitless Database e como você pode usá-lo, assista a este vídeo no canal AWS Events no YouTube:
Para obter mais informações sobre a arquitetura de um cluster de banco de dados padrão do Aurora, consulte Clusters de banco de dados do Amazon Aurora.
Principais termos para o Aurora PostgreSQL Limitless Database
- Grupo de fragmentos de banco de dados
-
Um contêiner para nós do Limitless Database (fragmentos e roteadores).
- Roteador
-
Um nó que aceita conexões SQL de clientes, envia comandos SQL para fragmentos, mantém a consistência em todo o sistema e retorna os resultados aos clientes.
- Fragmento
-
Um nó que armazena um subconjunto de tabelas fragmentadas, cópias completas de tabelas de referência e tabelas padrão. Aceita consultas de roteadores, mas não pode ser conectado diretamente pelos clientes.
- Tabela fragmentada
-
Uma tabela com seus dados particionados em fragmentos.
- Chave de fragmento
-
Uma coluna ou conjunto de colunas em uma tabela fragmentada que é usado para determinar o particionamento entre fragmentos.
- Tabelas colocalizadas
-
Duas tabelas fragmentadas que compartilham a mesma chave de fragmento e são explicitamente declaradas como colocalizadas. Todos os dados do mesmo valor de chave de fragmento são enviados para o mesmo fragmento.
- Tabela de referência
-
Uma tabela com seus dados copiados na íntegra em cada fragmento.
- Tabela padrão
-
O tipo de tabela padrão no Limitless Database. É possível converter tabelas padrão em tabelas fragmentadas e de referência.
Todas as tabelas padrão são armazenadas no mesmo fragmento selecionado pelo sistema, permitindo que as junções entre tabelas padrão sejam realizadas em um único fragmento. No entanto, as tabelas padrão são limitadas pela capacidade máxima do fragmento (128 TiB). Esse fragmento também armazena dados de tabelas fragmentadas e de referência, portanto, o limite efetivo para tabelas padrão é menor que 128 TiB.
Tipos de tabela para o Aurora PostgreSQL Limitless Database
O Aurora PostgreSQL Limitless Database é compatível com três tipos de tabela: fragmentada, de referência e padrão.
As tabelas fragmentadas têm seus dados distribuídos em todos os fragmentos no grupo de fragmentos de banco de dados. O Limitless Database faz isso automaticamente usando uma chave de fragmento, que é uma coluna ou conjunto de colunas que você especifica ao particionar a tabela. Todos os dados com o mesmo valor da chave de fragmento são enviados para o mesmo fragmento. A fragmentação é baseada em hash, não em intervalos ou listas.
Veja a seguir bons casos de uso para tabelas fragmentadas:
-
A aplicação funciona com um subconjunto distinto de dados.
-
A tabela é muito grande.
-
A tabela potencialmente cresce mais rápido do que outras tabelas.
As tabelas fragmentadas podem ser colocalizadas, o que significa que elas compartilham a mesma chave de fragmento e que todos os dados de ambas as tabelas com o mesmo valor de chave de fragmento são enviados para o mesmo fragmento. Se você colocalizar tabelas e uni-las usando a chave de fragmento, a junção poderá ser realizada em um único fragmento porque todos os dados necessários estão presentes nesse fragmento.
As tabelas de referência têm uma cópia completa de todos os dados em cada fragmento no grupo de fragmentos de banco de dados. As tabelas de referência são normalmente usadas para tabelas menores com um volume de gravação menor, mas que ainda precisam ser unidas com frequência e não são adequadas para fragmentação. Exemplos de tabelas de referência incluem tabelas de datas e tabelas de dados geográficos, como estado, cidade e código postal.
As tabelas padrão são o tipo de tabela padrão no Aurora PostgreSQL Limitless Database. Elas não são tabelas distribuídas. O Aurora PostgreSQL Limitless Database é compatível com junções entre tabelas padrão e tabelas padrão, fragmentadas e de referência.
Faturamento do Aurora PostgreSQL Limitless Database
Para obter informações sobre como a cobrança do Aurora PostgreSQL Limitless Database é feita, consulte Faturamento da instância de banco de dados para Aurora.
Para obter informações sobre a definição de preço do Aurora, consulte a página de definição de preço do Aurora
