As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Alta disponibilidade com o uso de grupos de replicação
Single-node Os clusters Amazon ElastiCache Valkey e Redis OSS são entidades na memória com serviços limitados de proteção de dados (AOF). Se o seu cluster falhar por qualquer motivo, você perderá todos os dados do cluster. No entanto, se você estiver executando um mecanismo OSS Valkey ou Redis, poderá agrupar de 2 a 6 nós em um cluster com réplicas em que 1 a 5 nós somente para leitura contêm dados replicados do único nó primário do grupo. read/write Nesse cenário, se um nó falhar por qualquer motivo, você não perderá todos os seus dados, pois eles serão replicados em um ou mais outros nós. Devido à latência da replicação, alguns dados podem ser perdidos se o read/write nó primário falhar.
Conforme visto no gráfico a seguir, a estrutura de replicação está contida em um fragmento (chamado de grupo de nós no API/CLI) que está contido em um cluster OSS Valkey ou Redis. Clusters do Valkey ou Redis OSS (modo cluster desabilitado) sempre têm um fragmento. Clusters do Valkey ou Redis OSS (modo cluster habilitado) podem ter até 500 fragmentos, com os dados do cluster particionados nos fragmentos. É possível criar um cluster com alto número de fragmentos e baixo número de réplicas totalizando até 90 nós por cluster. Essa configuração do cluster pode variar de 90 fragmentos e 0 réplicas para 15 fragmentos e 5 réplicas, que é o número máximo de réplicas permitidas.
O limite de nós ou fragmentos pode ser aumentado para um máximo de 500 por cluster com o Valkey e com ElastiCache a ElastiCache versão 5.0.6 ou superior para o Redis OSS. Por exemplo, você pode optar por configurar um cluster de 500 nós que varia entre 83 fragmentos (uma primária e 5 réplicas por fragmento) e 500 fragmentos (primário único e sem réplicas). Verifique se existem endereços IP disponíveis suficientes para acomodar o aumento. As armadilhas comuns incluem as sub-redes no grupo de sub-redes têm um intervalo CIDR muito pequeno ou as sub-redes são compartilhadas e fortemente usadas por outros clusters. Para obter mais informações, consulte Criação de um grupo de sub-redes.
Para versões abaixo de 5.0.6, o limite é 250 por cluster.
Para solicitar um aumento de limite, consulte Limites de serviço da AWS e selecione o tipo de limite Nodes per cluster per instance type (Nós por cluster por tipo de instância).
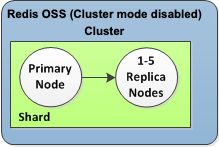
Cluster do Valkey ou Redis OSS (modo cluster desabilitado) tem um fragmento e de 0 a 5 nós de réplicas
Se o cluster com réplicas Multi-AZ estiver ativado e o nó primário falhar, o primário fará o failover para uma réplica de leitura. Como os dados são atualizados nos nós de réplica de forma assíncrona, pode haver alguma perda de dados devido à latência na atualização dos nós de réplica. Para obter mais informações, consulte Mitigar falhas ao executar o Valkey ou Redis OSS.
nota
Para clusters com durabilidade ativada, os dados são mantidos em um registro Multi-AZ transacional e podem ser recuperados mesmo se todos os nós falharem. Com gravações síncronas, nenhum dado reconhecido é perdido durante o failover. Com gravações assíncronas, até 10 segundos de dados podem ser perdidos em caso de falha.
Tópicos
Replicação com durabilidade habilitada
Para clusters Valkey 9.0+ com durabilidade habilitada, a replicação é mediada pelo log Multi-AZ transacional em vez do streaming direto do primário para a réplica. O nó primário grava no log transacional, e as réplicas consomem de forma independente as gravações confirmadas do log. Essa arquitetura significa que as réplicas se recuperam de forma independente sem impor carga ao nó primário.
Sincronização e backup com durabilidade
Para clusters com durabilidade ativada, as operações de sincronização e backup diferem dos clusters padrão:
Off-box captura de instantâneos: os instantâneos são criados por instâncias efêmeras que são lidas do registro Multi-AZ transacional, eliminando o impacto no desempenho do seu cluster.
Log-based recuperação: as réplicas com falha são restauradas a partir do log transacional e dos instantâneos, em vez de exigir uma sincronização completa do registro primário.
