Invocações de modelos
A funcionalidade de observabilidade de IA generativa do CloudWatch permite monitorar a performance das invocações de modelos. É possível acompanhar métricas, como a contagem de invocações, o uso de tokens e os erros, usando visualizações prontas para uso. Para obter uma visibilidade detalhada sobre o conteúdo relacionado à invocação, como as entradas e as saídas, habilite o registro em log de invocação do Bedrock e envie os logs para o CloudWatch. Para saber mais, consulte Set up a CloudWatch Logs destination e Help protect sensitive log data with masking.
Como habilitar a invocação de modelos no Amazon Bedrock
nota
É necessário habilitar o registro em log de invocação do modelo no Amazon Bedrock para visualizar as invocações.
Para habilitar o registro em log de invocações e modelo no Amazon Bedrock, siga estas etapas:
-
Abra o console do Amazon Bedrock em https://console.aws.amazon.com/bedrock/
. -
Escolha Configurações.
-
Em Registro em log de invocação do modelo, selecione Registro em log de invocação do modelo.
-
Escolha os tipos de dados obrigatórios a serem incluídos nos logs. Escolha enviar os logs apenas para o CloudWatch Logs ou para o Amazon S3 e o CloudWatch Logs se você já publicar no Amazon S3.
-
Nas configurações do CloudWatch Logs, crie um nome para o grupo de logs e selecione os perfis de serviços apropriados.
-
Escolha os tipos de dados obrigatórios a serem incluídos nos logs.
-
Escolha Salvar configurações.
É possível visualizar os painéis configurados previamente de forma automática ao começar a usar as invocações do Amazon Bedrock. Após habilitar
Model Invocation logging, você pode visualizar os painéis padrão e acessar a tabela de invocação localizada abaixo deles.
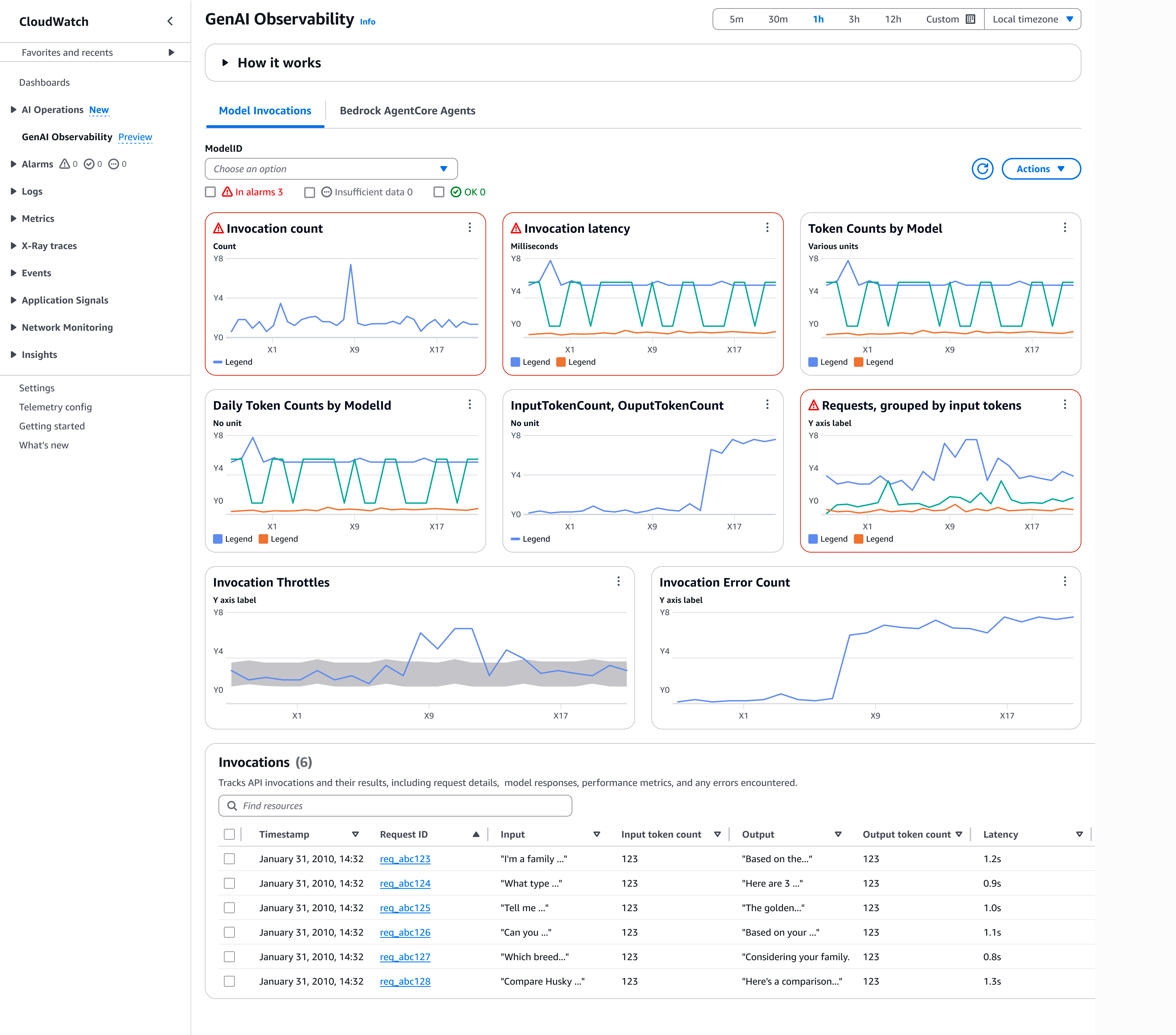
-
Contagem de invocação: número de solicitações bem-sucedidas às operações de API Converse, ConverseStream, InvokeModel e InvokeModelWithResponseStream.
-
Latência de invocação: tempo de latência das invocações.
-
Contagem de tokens por modelo: contagem de tokens por modelo, detalhada pelas contagens de tokens de entrada e de tokens de saída.
-
Contagem diária de tokens por ModelID: contagem total diária de tokens por ID do modelo.
-
InputTokenCount e OutputTokenCount: número total de tokens na entrada e na saída nesta conta, considerando os modelos selecionados.
-
Solicitações agrupadas por tokens de entrada: número de solicitações agrupadas em seis intervalos, conforme o número de tokens de entrada. Cada linha representa o número de solicitações que se enquadram em um intervalo específico.
-
Controle de utilização para invocação: número de invocações controladas pelo sistema devido ao controle de utilização. O número de controles de utilização observado dependerá das configurações de nova tentativa estabelecidas no SDK. Para obter mais informações, consulte o comportamento Retry no Guia de referência dos SDKs e das ferramentas da AWS.
-
Contagem de erros de invocação: número de invocações que resultaram em erros do lado do servidor e do lado do cliente.
Para usar o painel de invocação de modelos, siga essas etapas.
-
Passe o cursor do mouse sobre qualquer gráfico de métricas para visualizar os detalhes da invocação. Você pode selecionar o ícone Alarme para configurar
Alarmsque monitorem a qualidade e a performance da aplicação. -
No menu suspenso ModelID, você pode selecionar um ID de modelo para visualizar as métricas correspondentes.
-
Selecione Visualizar em métricas do CloudWatch para visualizar as métricas do painel no CloudWatch.
-
Selecione Substituição de período para ajustar o intervalo de tempo das métricas (por exemplo, um minuto, uma hora ou seis horas).
-
Em Invocações, escolha ID da solicitação para visualizar os detalhes da solicitação. É possível visualizar os detalhes de entrada e de saída da invocação de modelos no painel localizado à direita.

Na página ID da solicitação, no menu suspenso Ações, selecione Visualizar no Logs Insights para visualizar os logs no CloudWatch. Para obter mais informações, consulte Analisar logs de dados com o CloudWatch Logs Insights.
