Generate Db2 z/OS data insights by using AWS Mainframe Modernization and Amazon Q in Quick Sight
Shubham Roy, Roshna Razack, and Santosh Kumar Singh, Amazon Web Services
Summary
Note: AWS Mainframe Modernization Service (Managed Runtime Environment experience) is no longer open to new customers. For capabilities similar to AWS Mainframe Modernization Service (Managed Runtime Environment experience) explore AWS Mainframe Modernization Service (Self-Managed Experience). Existing customers can continue to use the service as normal. For more information, see AWS Mainframe Modernization availability change.
If your organization is hosting business-critical data in an IBM Db2 mainframe environment, gaining insights from that data is crucial for driving growth and innovation. By unlocking mainframe data, you can build faster, secure, and scalable business intelligence to accelerate data-driven decision-making, growth, and innovation in the Amazon Web Services (AWS) Cloud.
This pattern presents a solution for generating business insights and creating sharable narratives from mainframe data in IBM Db2 for z/OS tables. Mainframe data changes are streamed to Amazon Managed Streaming for Apache Kafka (Amazon MSK) topic using AWS Mainframe Modernization Data Replication with Precisely. Using Amazon Redshift streaming ingestion, Amazon MSK topic data is stored in Amazon Redshift Serverless data warehouse tables for analytics in Amazon Quick Sight.
After the data is available in Quick Sight, you can use natural language prompts with Amazon Q in Quick Sight to create summaries of the data, ask questions, and generate data stories. You don't have to write SQL queries or learn a business intelligence (BI) tool.
Business context
This pattern presents a solution for mainframe data analytics and data insights use cases. Using the pattern, you build a visual dashboard for your company's data. To demonstrate the solution, this pattern uses a health care company that provides medical, dental, and vision plans to its members in the US. In this example, member demographics and plan information are stored in the IBM Db2 for z/OS data tables. The visual dashboard shows the following:
Member distribution by region
Member distribution by gender
Member distribution by age
Member distribution by plan type
Members who have not completed preventive immunization
For examples of member distribution by region and members who have not completed preventive immunization, see the Additional information section.
After you create the dashboard, you generate a data story that explains the insights from the previous analysis. The data story provides recommendations for increasing the number of members who have completed preventive immunizations.
Prerequisites and limitations
Prerequisites
An active AWS account. This solution was built and tested on Amazon Linux 2 on Amazon Elastic Compute Cloud (Amazon EC2).
An virtual private cloud (VPC) with a subnet that can be accessed by your mainframe system.
A mainframe database with business data. For the example data used to build and test this solution, see the Attachments section.
Change data capture (CDC) enabled on the Db2 z/OS tables. To enable CDC on Db2 z/OS, see the IBM documentation.
Precisely Connect CDC for z/OS installed on the z/OS system that's hosting the source databases. The Precisely Connect CDC for z/OS image is provided as a zip file within the AWS Mainframe Modernization - Data Replication for IBM z/OS Amazon Machine Image (AMI). To install Precisely Connect CDC for z/OS on the mainframe, see the Precisely installation documentation.
Limitations
Your mainframe Db2 data should be in a data type that's supported by Precisely Connect CDC. For a list of supported data types, see the Precisely Connect CDC documentation.
Your data at Amazon MSK should be in a data type that's supported by Amazon Redshift. For a list of supported data types, see the Amazon Redshift documentation.
Amazon Redshift has different behaviors and size limits for different data types. For more information, see the Amazon Redshift documentation.
The near real-time data in Quick Sight depends on the refresh interval set for the Amazon Redshift database.
Some AWS services aren’t available in all AWS Regions. For Region availability, see AWS services by Region. Amazon Q in Quick Sight is currently not available in every Region that supports Quick Sight. For specific endpoints, see the Service endpoints and quotas page, and choose the link for the service.
Product versions
AWS Mainframe Modernization Data Replication with Precisely version 4.1.44
Python version 3.6 or later
Apache Kafka version 3.5.1
Architecture
Target architecture
The following diagram shows an architecture for generating business insights from mainframe data by using AWS Mainframe Modernization Data Replication with Precisely and Amazon Q in Quick Sight.
The diagram shows the following workflow:
The Precisely Log Reader Agent reads data from Db2 logs and writes the data into transient storage on an OMVS file system on the mainframe.
The Publisher Agent reads the raw Db2 logs from transient storage.
The on-premises controller daemon authenticates, authorizes, monitors, and manages operations.
The Apply Agent is deployed on Amazon EC2 by using the preconfigured AMI. It connects with the Publisher Agent through the controller daemon by using TCP/IP. The Apply Agent pushes data to Amazon MSK using multiple workers for high-throughput.
The workers write the data to the Amazon MSK topic in JSON format. As the intermediate target for the replicated messages, Amazon MSK provides the highly available and automated failover capabilities.
Amazon Redshift streaming ingestion provides low-latency, high-speed data ingestion from Amazon MSK to an Amazon Redshift Serverless database. A stored procedure in Amazon Redshift performs the mainframe change data (insert/update/deletes) reconciliation into Amazon Redshift tables. These Amazon Redshift tables serves as the data analytics source for Quick Sight.
Users access the data in Quick Sight for analytics and insights. You can use Amazon Q in Quick Sight to interact with the data by using natural language prompts.
Tools
AWS services
Amazon Elastic Compute Cloud (Amazon EC2) provides scalable computing capacity in the AWS Cloud. You can launch as many virtual servers as you need and quickly scale them out or in.
AWS Key Management Service (AWS KMS) helps you create and control cryptographic keys to help protect your data.
Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a fully managed service that helps you build and run applications that use Apache Kafka to process streaming data.
Amazon Quick Sight is a cloud-scale business intelligence (BI) service that helps you visualize, analyze, and report your data in a single dashboard. This pattern uses the generative BI capabilities of Amazon Q in Quick Sight.
Amazon Redshift Serverless is a serverless option of Amazon Redshift that makes it more efficient to run and scale analytics in seconds without the need to set up and manage data warehouse infrastructure.
AWS Secrets Manager helps you replace hardcoded credentials in your code, including passwords, with an API call to Secrets Manager to retrieve the secret programmatically.
Other tools
Code repository
The code for this pattern is available in the GitHub Mainframe_DataInsights_change_data_reconciliation repository. The code is a stored procedure in Amazon Redshift. This stored procedure reconciles mainframe data changes (inserts, updates, and deletes) from Amazon MSK into the Amazon Redshift tables. These Amazon Redshift tables serve as the data analytics source for Quick Sight.
Best practices
Follow best practices while setting up your Amazon MSK cluster.
Follow Amazon Redshift data parsing best practices for improving performance.
When you create the AWS Identity and Access Management (IAM) roles for the Precisely setup, follow the principle of least privilege and grant the minimum permissions required to perform a task. For more information, see Grant least privilege and Security best practices in the IAM documentation.
Epics
| Task | Description | Skills required |
|---|
Set up a security group. | To connect to the controller daemon and the Amazon MSK cluster, create a security group for the EC2 instance. Add the following inbound and outbound rules: Inbound rule 1: For Type,choose Custom TCP. For Protocol, choose TCP. For Port range, choose 2626 (default port for the Precisely controller daemon) or the port number of the controller daemon running on the mainframe. For Source, choose CIDR block.
Inbound rule 2: For Type, choose Custom TCP. For Protocol, choose SSH. For Port range, choose 22. For Source, choose IP address or prefix list.
Inbound rule 3: For Type, choose Custom TCP. For Protocol, choose TCP. For Port range, choose 9092-9098. For Source, choose CIDR block.
Outbound rule 1: For Type, choose Custom TCP. For Protocol, choose TCP. For Port range, choose 9092-9098. For Source, choose CIDR block.
Outbound rule 2: For Type, choose Custom TCP. For Protocol, choose TCP. For Port range, choose 2626 (default port for the Precisely controller daemon) or the port number of the controller daemon running on the mainframe. For Source, choose CIDR block.
Note the name of the security group. You will need to reference the name when you launch the EC2 instance and configure the Amazon MSK cluster. | DevOps engineer, AWS DevOps |
Create an IAM policy and an IAM role. | To create an IAM policy and an IAM role, follow the instructions in the AWS documentation. The IAM policy grants access to create topics on the Amazon MSK cluster and to send data to those topics. After you create the IAM role, associate the policy with it. Note the IAM role name. This role will be used as the IAM instance profile when you launch the EC2 instance.
| DevOps engineer, AWS systems administrator |
Provision an EC2 instance. | To provision an EC2 instance to run Precisely CDC and connect to Amazon MSK, do the following: Sign in to AWS Marketplace, and subscribe to AWS Mainframe Modernization ‒ Data Replication for IBM z/OS. Select the AMI from the managed subscriptions, and choose on Launch new instance. Provide other configuration details, such as the instance name, instance type, key pair, VPC, and subnets. For more information, see the Amazon EC2 documentation. In the dropdown list, choose the security group that you created earlier. Under Advanced details, IAM instance profile, you must select the role that you created earlier. Choose Launch instance.
| AWS administrator, DevOps engineer |
| Task | Description | Skills required |
|---|
Create the Amazon MSK cluster. | To create an Amazon MSK cluster, do the following : Sign in to the AWS Management Console, and navigate to Amazon MSK. Choose Create cluster. For the cluster creation method, choose Custom create, and for the cluster type, choose Provisioned. Provide a name for the cluster. Update Cluster settings as needed, and keep the defaults for the other settings. Note the <Kafka version>. You will need it during Kafka client setup. Choose Next. Choose the same VPC and subnets that you used for the Precisely EC2 instance, and choose the security group that you created earlier. In the Security settings section, enable both SASL/SCRAM and IAM role-based authentication. Precisely Connect CDC uses SASL/SCRAM (Simple Authentication and Security Layer/ Salted Challenge Response Mechanism), and IAM is needed for connecting to Amazon Redshift. Choose Next. For reviewing, choose Monitoring and Broker log delivery method. Choose Next, and then choose Create the cluster.
A typical provisioned cluster takes up to 15 minutes to create. After the cluster is created, its status changes from Creating to Active. | AWS DevOps, Cloud administrator |
Set up SASL/SCRAM authentication. | To set up SASL/SCRAM authentication for an Amazon MSK cluster, do the following: To set up a secret in Secrets Manager, follow the instructions in the AWS documentation. Open the Amazon MSK console, and select the Amazon MSK cluster that you created previously. Choose the Properties tab. Choose Associate secrets, Choose the secrets, select the secrets key that you created, and then choose Associate secrets. You will see a success message similar to the following: Successfully associated 1 secret for cluster <chosen cluster name>
Choose the cluster name. In the cluster summary, choose View client information. Note the private endpoint connection string for the authentication type SASL/SCRAM.
| Cloud architect |
Create the Amazon MSK topic. | To create the Amazon MSK topic, do the following: Connect to the EC2 instance that you created earlier, and install the latest updates by running the following command: sudo yum update -y
Install the Java and Kafka library by running the following command: sudo yum install -y java-11 librdkafka librdkafka-devel
To create a folder named kafka in /home/ec2-user, navigate to that folder, and run the following command: mkdir kafka;cd kafka
Download the kafka client library to the kafka folder, replacing <YOUR MSK VERSION> with the Kafka version that you noted during the Amazon MSK cluster creation: wget https://archive.apache.org/dist/kafka//kafka_2.13-<YOUR MSK VERSION>.tgz
To extract the downloaded file, run the following command, replacing YOUR MSK VERSION>: tar -xzf kafka_2.13-<YOUR MSK VERSION>.tgz
To navigate to the kafka libs directory and download the Java IAM authentication Java Archive (JAR) file, run the following commands, replacing <YOUR MSK VERSION>: cd kafka_2.13-<YOUR MSK VERSION>/libs
wget https://github.com/aws/aws-msk-iam-auth/releases/download/v1.1.1/aws-msk-iam-auth-1.1.1-all.jarkafka
To navigate to the Kafka bin directory and create the client.properties file, run the following commands: cd /home/ec2-user/kafka/kafka_2.13-<YOUR MSK VERSION>/bin
cat >client.properties
Update the client.properties file with the following contents: security.protocol=SASL_SSL
sasl.mechanism=AWS_MSK_IAM
sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
To create a Kafka topic, navigate to the Kafka bin and run the following command, replacing <kafka broker> with the IAM bootstrap server private endpoint that you noted during Amazon MSK cluster creation: ./kafka-topics.sh --bootstrap-server <kafka broker> --command-config client.properties --create --replication-factor 3 —partitions 6 --topic <topic name>
When the message Created topic <topic name> appears, note the topic name.
| Cloud administrator |
| Task | Description | Skills required |
|---|
Set up the Precisely scripts to replicate data changes. | To set up the Precisely Connect CDC scripts to replicate changed data from the mainframe to the Amazon MSK topic, do the following: To create a folder name precisely and change to that folder, run the following command: mkdir /home/ec2-user/precisely;cd /home/ec2-user/precisely
To create two folders inside precisely called scripts and ddls, and then change to the scripts folder, run the following command: mkdir scripts;mkdir ddls;cd scripts
To create a file named sqdata_kafka_producer.conf in the scripts folder, run the following command: cat >sqdata_kafka_producer.conf
Update sqdata_kafka_producer.conf file with the following content: builtin.features=SASL_SCRAM
security.protocol=SASL_SSL
sasl.mechanism=SCRAM-SHA-512
sasl.username=<User Name>
sasl.password=<Password>
metadata.broker.list=<SASL/SCRAM Bootstrap servers>
Update <SASL/SCRAM Bootstrap servers> with the Amazon MSK SASL/SCRAM broker list that you previously configured. Update <User Name> and <Password> with the username and password that you set up previously in Secrets Manager. Create a script.sqd file in the scripts folder. cat >script.sqd
The Apply Engine uses script.sqd to process source data and replicate the source data to the target. For an example Apply Engine script, see the Additional information section. To change to the ddls folder and create a .ddl file for each Db2 table, run the following commands: cd /home/ec2-user/precisely/ddls
cat >mem_details.ddl
cat >mem_plans.ddl
For example .ddl files, see the Additional information section. | App developer, Cloud architect |
Generate the network ACL key. | To generate the network access control list (network ACL) key, do the following: To export the sqdata installation path, run the following command: export PATH=$PATH:/usr/sbin:/opt/precisely/di/sqdata/bin
To change to the /home/ec2-user directory and generate the network ACL key, run the following commands: cd /home/ec2-user
sqdutil keygen --force
After the public and private keys are generated, the following message is displayed: SQDUT04I Generating a private key in file /home/ec2-user/.nacl/id_nacl
SQDC017I sqdutil(pid=27344) terminated successfully
Note the generated public key that is stored in the .nacl folder.
| Cloud architect, AWS DevOps |
| Task | Description | Skills required |
|---|
Configure defaults in the ISPF screen. | To configure default settings in the Interactive System Productivity Facility (ISPF), follow the instructions in the Precisely documentation. | Mainframe system administrator |
Configure the controller daemon. | To configure the controller daemon, do the following: On the SQData z/OS Main Menu screen, choose option 2. On the Add Daemon to List screen, in the Daemon Name field, enter a name for the daemon, and then press Enter.
| Mainframe system administrator |
Configure the publisher. | To configure the publisher, do the following: On the SQData z/OS Main Menu screen, choose option 3. This takes you to the Capture/Publisher Summary screen. Choose the option to add a CAB file. This will take you to the Add CAB File to List screen. In the Name field, enter a name for the CAB file. For Db2, enter the Type as D. Press Enter. This takes you to the Create New Db2 Capture CAB File screen. In the zFS Dir field, specify the storage mount point. Press Enter to save and continue.
| Mainframe system administrator |
Update the daemon configuration file. | To update the publisher details in the controller daemon configuration file, do the following: On the SQData z/OS Main Menu screen, choose option 2. Enter S near the daemon that you created to see the daemon details. Enter 1, and then press Enter to edit the agents file. Add your CAB file details. The following example shows the details for a CAB file named DB2ZTOMSK. Use your mainframe user ID instead of <userid>. ÝDB2ZTOMSK¨
type=capture
cab=/u/<userid>/sqdata/DB2ZTOMSK.cab
Press F3. Enter 2 to edit the ACL file. Add your userid to the acl configuration file as shown in the following example: Ýacls¨
prod=admin,<userid>
Press F3 to save and exit.
| Mainframe system administrator |
Create the job to start the controller daemon. | To create the job, do the following: In Options, enter G. Enter the JOB Card, job and proc libraries, and Db2 load library details. Enter the network ACL file details, and enter option 2 to generate the job control language (JCL) file in the specified job library.
| Mainframe system administrator |
Generate the capture publisher JCL file. | To generation the capture publisher JCL file, do the following: On the SQData z/OS Main Menu screen, choose option 3. This takes you to the Capture/Publisher Summary screen. Enter S next to the CAB file to select it. This takes you to the Db2 Capture/Publisher Detail screen. In Options, enter G in options to generate the capture/publisher job. Enter the JOB card, job, and procedure libraries, and Db2 load library details. To create the job, choose option 4. The job is created in the job library specified in job library.
| Mainframe system administrator |
Check and update CDC. | Check the DATACAPTURE flag for the Db2 table by running the following query, changing <table name> to your Db2 table name: SELECT DATACAPTURE FROM SYSIBM.SYSTABLES WHERE NAME='<table name>';
Confirm that the result shows DATACAPTURE as Y. If DATACAPTURE is not Y, run the following query to enable CDC on the Db2 table, changing <table name> to your Db2 table name: ALTER TABLE <table name> DATA CAPTURE CHANGES;
| Mainframe system administrator |
Submit the JCL files. | Submit the following JCL files that you configured in the previous steps: After you submit the JCL files, you can start the Apply Engine in Precisely on the EC2 instance. | Mainframe system administrator |
| Task | Description | Skills required |
|---|
Start the Apply Engine and validate the CDC. | To start the Apply Engine on the EC2 instance and validate the CDC, do the following: To connect to the EC2 instance, follow the instructions in the AWS documentation. Change to the directory that contains the script.sqd file: cd /home/ec2-user/precisely/scripts
To start the Apply Engine, run the following sqdeng start command: sqdeng -s script.sqd --identity=/home/ec2-user/.nacl/id_nacl
The Apply Engine will start waiting for updates from the mainframe source. To test CDC, make some record inserts or updates in the Db2 table. Validate that the Apply Engine log shows the number of records captured and written to the target.
| Cloud architect, App developer |
Validate the records on the Amazon MSK topic. | To read the message from the Kafka topic, do the following: To change to the bin directory of the Kafka client installation path on the EC2 instance, run the following command, replacing <Kafka version> with your version: cd /home/ec2-user/kafka/kafka_2.13-<Kafka version>/bin
To validate the Db2 CDC written as messages in the Kafka topic, run the following command, replacing <kafka broker> and <Topic Name> with the topic that you created earlier: ./kafka-console-consumer.sh --bootstrap-server <kafka broker>:9098 --topic <Topic Name> --from-beginning --consumer.config client.properties
Validate that the messages match the number of records updated in the Db2 table.
| App developer, Cloud architect |
| Task | Description | Skills required |
|---|
Set up Amazon Redshift Serverless. | To create an Amazon Redshift Serverless data warehouse, follow the instructions in the AWS documentation. On the Amazon Redshift Serverless dashboard, validate that the namespace and workgroup were created and are available. For this example pattern, the process might take 2‒5 minutes. | Data engineer |
Set up the IAM role and trust policy required for streaming ingestion. | To set up Amazon Redshift Serverless streaming ingestion from Amazon MSK, do following: Create an IAM policy for Amazon Redshift to access Amazon MSK. Replacing [region] with the AWS Region for Amazon MSK, [account-id] with your AWS account ID, and [msk-cluster-name] with Amazon MSK cluster name, run the following code: {"Version": "2012-10-17", "Statement": [{"Sid": "MSKIAMpolicy","Effect": "Allow","Action": ["kafka-cluster:ReadData","kafka-cluster:DescribeTopic","kafka-cluster:Connect"],"Resource": ["arn:aws:kafka:[region]:[account-id]:cluster/[msk-cluster-name]/*","arn:aws:kafka:[region]:[account-id]:topic/[msk-cluster-name]/*"]},{"Effect": "Allow","Action": ["kafka-cluster:AlterGroup","kafka-cluster:DescribeGroup"],"Resource": ["arn:aws:kafka:[region]:[account-id]:group/[msk-cluster-name]/*"]}]}
You can find the cluster name and the Amazon Resource Name (ARN) on the Amazon MSK console. On the console, choose Cluster summary, and then choose ARN. To create an IAM role and attach the policy, follow the instructions in the AWS documentation. To attach the IAM role to the Amazon Redshift Serverless namespace, do following: In your Amazon Redshift Serverless security group, create an inbound rule with the following details: For Type, choose Custom TCP. For Protocol, choose TCP. For Port range, choose 9098, 9198. For Source, choose Amazon MSK security group.
In your Amazon MSK security group, create an inbound rule with following details: For Type, choose Custom TCP. For Protocol, choose TCP. For Port range, choose 9098, 9198. For Source, choose Amazon Redshift security group.
This pattern uses the port for IAM authentication for both Amazon Redshift and Amazon MSK configuration. For more information, see the AWS documentation (step 2). Turn on enhanced VPC routing for the Amazon Redshift Serverless workgroup. For more information, see the AWS documentation.
| Data engineer |
Connect Amazon Redshift Serverless to Amazon MSK. | To connect to the Amazon MSK topic, create an external schema in Amazon Redshift Serverless. In Amazon Redshift query editor v2, run the following SQL command, replacing 'iam_role_arn' with the role that you created previously and replacing 'MSK_cluster_arn' with the ARN for your cluster. CREATE EXTERNAL SCHEMA member_schema
FROM MSK
IAM_ROLE 'iam_role_arn'
AUTHENTICATION iam
URI 'MSK_cluster_arn';
| Migration engineer |
Create a materialized view. | To consume the data from the Amazon MSK topic in Amazon Redshift Serverless, create a materialized view. In Amazon Redshift query editor v2, run the following SQL commands, replacing <MSK_Topic_name> with the name of your Amazon MSK topic. CREATE MATERIALIZED VIEW member_view
AUTO REFRESH YES
AS SELECT
kafka_partition,
kafka_offset,
refresh_time,
json_parse(kafka_value) AS Data
FROM member_schema.<MSK_Topic_name>
WHERE CAN_JSON_PARSE(kafka_value);
| Migration engineer |
Create target tables in Amazon Redshift. | Amazon Redshift tables provide the input for Quick Sight. This pattern uses the tables member_dtls and member_plans, which match the source Db2 tables on the mainframe. To create the two tables in Amazon Redshift, run the following SQL commands in Amazon Redshift query editor v2: -- Table 1: members_dtls
CREATE TABLE members_dtls (
memberid INT ENCODE AZ64,
member_name VARCHAR(100) ENCODE ZSTD,
member_type VARCHAR(50) ENCODE ZSTD,
age INT ENCODE AZ64,
gender CHAR(1) ENCODE BYTEDICT,
email VARCHAR(100) ENCODE ZSTD,
region VARCHAR(50) ENCODE ZSTD
) DISTSTYLE AUTO;
-- Table 2: member_plans
CREATE TABLE member_plans (
memberid INT ENCODE AZ64,
medical_plan CHAR(1) ENCODE BYTEDICT,
dental_plan CHAR(1) ENCODE BYTEDICT,
vision_plan CHAR(1) ENCODE BYTEDICT,
preventive_immunization VARCHAR(50) ENCODE ZSTD
) DISTSTYLE AUTO;
| Migration engineer |
Create a stored procedure in Amazon Redshift. | This pattern uses a stored procedure to sync-up change data (INSERT, UPDATE, DELETE) from the source mainframe to the target Amazon Redshift data warehouse table for analytics in Quick Sight. To create the stored procedure in Amazon Redshift, use query editor v2 to run the stored procedure code that's in the GitHub repository. | Migration engineer |
Read from the streaming materialized view and load to the target tables. | The stored procedure reads data change from the streaming materialized view and loads the data changes to the target tables. To run the stored procedure, use the following command: call SP_Members_Load();
You can use Amazon EventBridge to schedule the jobs in your Amazon Redshift data warehouse to call this stored procedure based on your data latency requirements. EventBridge runs jobs at fixed intervals. To monitor whether the previous call to the procedure completed, you might need to use a mechanism such as an AWS Step Functions state machine. For more information, see the following resources: Another option is to use Amazon Redshift query editor v2 to schedule the refresh. For more information, see Scheduling a query with query editor v2. | Migration engineer |
| Task | Description | Skills required |
|---|
Set up Quick Sight. | To set up Quick Sight, follow the instructions in the AWS documentation. | Migration engineer |
Set up a secure connection between Quick Sight and Amazon Redshift. | To set up secure a connection between Quick Sight and Amazon Redshift, do the following To authorize connections from Quick Sight to Amazon Redshift, open the Amazon Redshift console, and add an inbound rule in the Amazon Redshift security group. The rule should allow traffic to port 5439 (the default Redshift port) from the CIDR range where you set up Quick Sight. For a list of AWS Regions and their IP addresses, see Supported AWS Regions for Quick Sight. On the Amazon Redshift console, choose Workgroup, Data access, Network and security, and enable Publicly accessible.
| Migration engineer |
Create a dataset for Quick Sight. | To create a dataset for Quick Sight from Amazon Redshift, do following: On the Quick Sight console, in the navigation pane, choose Datasets. On the Datasets page, choose New data set. Choose Redshift Manual connect. In the New Redshift data source window, enter the connection information: For Data source name, enter a name for the Amazon Redshift data source. For Database server, enter the endpoint of the Amazon Redshift cluster. You can get the endpoint value from the Endpoint field in the General information section for the cluster workgroup on the Amazon Redshift Serverless dashboard. The server address is the first part of the endpoint before the colon, as shown in the following example: mfdata-insights.NNNNNNNNN.us-east-1.redshift-serverless.amazonaws.com:5439/dev
For the port, enter 5439 (the default port for Amazon Redshift). Enter the name of the database (after the slash in the endpoint). In this case, the database name is dev. For Username and Password, enter the username and password for the Amazon Redshift database.
Choose Validate Connection. If successful, you should see a green check mark, which indicates validation. If validation fails, see the Troubleshooting section. Choose Create data source.
| Migration engineer |
Join the dataset. | To create analytics in Quick Sight, join the two tables by following the instructions in the AWS documentation. In the Join Configuration pane, choose Left for Join type. Under Join clauses, use memberid from member_plans = memberid from members_details. | Migration engineer |
| Task | Description | Skills required |
|---|
Set up Amazon Q in Quick Sight. | To set up the Amazon Q in Quick Sight generative BI capability, follow the instructions in the AWS documentation. | Migration engineer |
Analyze mainframe data and build a visual dashboard. | To analyze and visualize your data in Quick Sight, do the following: To create the mainframe data analysis, follow the instructions in the AWS documentation. For the dataset, choose the dataset that you created. On the analysis page choose Build visual. In the Create topic for analysis window, choose Update existing topic. In the Select a topic dropdown list, choose the topic that you created previously. Choose Topic linking. After you link the topic, choose Build visual to open the Amazon Q Build a Visual window. In the prompt bar. write your analysis questions. The example questions used for this pattern are the following: Show member distribution by region Show member distribution by age Show member distribution by gender Show member distribution by plan type Show members not completed preventive immunization
After you enter your questions, choose Build. Amazon Q in Quick Sight creates the visuals. To add the visuals to your visual dashboard, choose ADD TO ANALYSIS.
When you're finished, you can publish your dashboard to share with others in your organization. For examples, see Mainframe visual dashboard in the Additional information section. | Migration engineer |
| Task | Description | Skills required |
|---|
Create a data story. | Create a data story to explain insights from the previous analysis, and generate a recommendation to increase preventive immunization for members: To create the data story, follow the instructions in the AWS documentation. For the data story prompt, use the following: Build a data story about Region with most numbers of members. Also show the member distribution by medical plan, vision plan, dental plan. Recommend how to motivate members to complete immunization. Include 4 points of supporting data for this pattern.
You can also build your own prompt to generate data stories for other business insights. Choose Add visuals, and add the visuals that are relevant to the data story. For this pattern, use the visuals that you created previously. Choose Build. For example data story output, see Data story output in the Additional information section.
| Migration engineer |
View the generated data story. | To view the generated data story, choose that story on the Data stories page. | Migration engineer |
Edit a generated data story. | To change the formatting, layout, or visuals in a data story, follow the instructions in the AWS documentation. | Migration engineer |
Share a data story. | To share a data story, follow the instructions in the AWS documentation. | Migration engineer |
Troubleshooting
| Issue | Solution |
|---|
For Quick Sight to Amazon Redshift dataset creation, Validate Connection has faled. | Confirm that the security group attached to the Amazon Redshift Serverless instance allows inbound traffic from the IP address range associated with the Region where you set up Quick Sight. Confirm that the VPC where Amazon Redshift Serverless is deployed is publicly available. Confirm that you are using the correct username and password for Amazon Redshift. You can reset the username and password on the Amazon Redshift console.
|
Trying to start the Apply engine on the EC2 instance returns the following error: -bash: sqdeng: command not found
| Export the sqdata installation path by running following command: export PATH=$PATH:/usr/sbin:/opt/precisely/di/sqdata/bin
|
Trying to start the Apply Engine returns one of the following connection errors: SQDD018E Cannot connect to transfer socket(rc==0x18468). Agent:<Agent Name > Socket:/u/./sqdata/.DB2ZTOMSK.cab.data
SQDUR06E Error opening url cdc://<VPC end point name>:2626/DB2ZTOMSK/DB2ZTOMSK : errno:1128 (Unknown error 1128)
| Check the mainframe spool to make sure that the controller daemon jobs are running. |
Related resources
Additional information
Example .ddl files
members_details.ddl
CREATE TABLE MEMBER_DTLS (
memberid INTEGER NOT NULL,
member_name VARCHAR(50),
member_type VARCHAR(20),
age INTEGER,
gender CHAR(1),
email VARCHAR(100),
region VARCHAR(20)
);
member_plans.ddl
CREATE TABLE MEMBER_PLANS (
memberid INTEGER NOT NULL,
medical_plan CHAR(1),
dental_plan CHAR(1),
vision_plan CHAR(1),
preventive_immunization VARCHAR(20)
);
Example .sqd file
Replace <kafka topic name> with your Amazon MSK topic name.
script.sqd
-- Name: DB2ZTOMSK: DB2z To MSK JOBNAME DB2ZTOMSK;REPORT EVERY 1;OPTIONS CDCOP('I','U','D');-- Source Descriptions
JOBNAME DB2ZTOMSK;
REPORT EVERY 1;
OPTIONS CDCOP('I','U','D');
-- Source Descriptions
BEGIN GROUP DB2_SOURCE;
DESCRIPTION DB2SQL /var/precisely/di/sqdata/apply/DB2ZTOMSK/ddl/mem_details.ddl AS MEMBER_DTLS;
DESCRIPTION DB2SQL /var/precisely/di/sqdata/apply/DB2ZTOMSK/ddl/mem_plans.ddl AS MEMBER_PLANS;
END GROUP;
-- Source Datastore
DATASTORE cdc://<zos_host_name>/DB2ZTOMSK/DB2ZTOMSK
OF UTSCDC
AS CDCIN
DESCRIBED BY GROUP DB2_SOURCE ;
-- Target Datastore(s)
DATASTORE 'kafka:///<kafka topic name>/key'
OF JSON
AS TARGET
DESCRIBED BY GROUP DB2_SOURCE;
PROCESS INTO TARGET
SELECT
{
REPLICATE(TARGET)
}
FROM CDCIN;
Mainframe visual dashboard
The following data visual was created by Amazon Q in Quick Sight for the analysis question show member distribution by region.
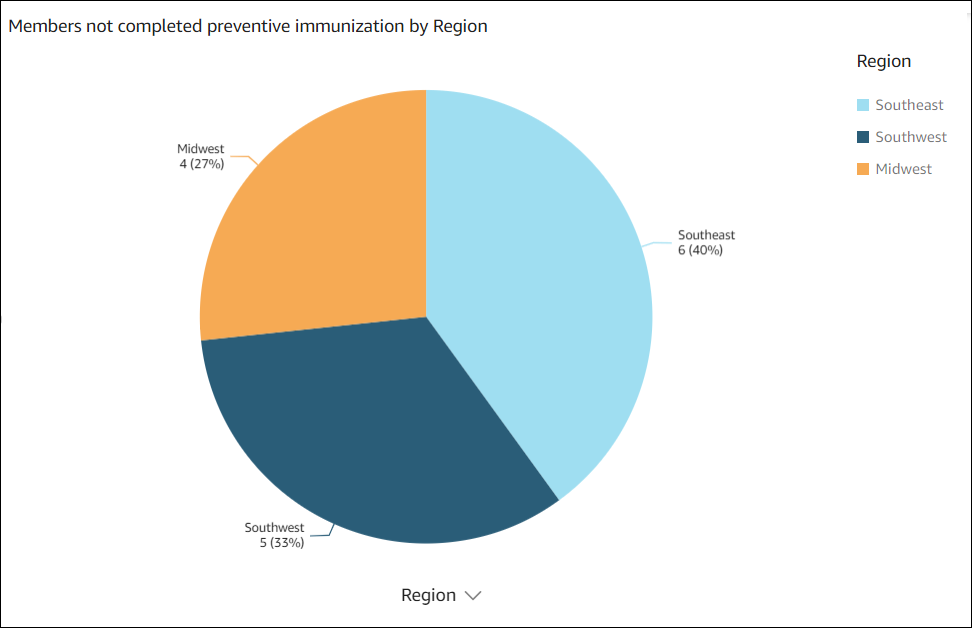
The following data visual was created by Amazon Q in Quick Sight for the question show member distribution by Region who have not completed preventive immunization, in pie chart.
Data story output
The following screenshots show sections of the data story created by Amazon Q in Quick Sight for the prompt Build a data story about Region with most numbers of members. Also show the member distribution by age, member distribution by gender. Recommend how to motivate members to complete immunization. Include 4 points of supporting data for this pattern.
In the introduction, the data story recommends choosing the region with the most members to gain the greatest impact from immunization efforts.
The data story provides an analysis of member numbers for the four regions. The Northeast, Southwest, and Southeast regions have the most members.
The data story presents an analysis of members by age.
The data story focuses on immunization efforts in the Midwest.
Attachments
To access additional content that is associated with this document, download and unzip the following file: attachment.zip