Modern data lakes
Advanced use cases in modern data lakes
The evolution of data storage has progressed from databases to data warehouses and data lakes, where each technology addresses unique business and data requirements. Traditional databases excelled at handling structured data and transactional workloads, but they faced performance challenges as data volumes increased. Data warehouses emerged to tackle performance and scalability issues, but like databases, they relied on proprietary formats within vertically integrated systems.
Data lakes offer one of the best options for storing data in terms of cost, scalability, and flexibility. You can use a data lake to retain large volumes of structured and unstructured data at a low cost, and use this data for different types of analytics workloads, from business intelligence reporting to big data processing, real-time analytics, machine learning, and generative artificial intelligence (AI), to help guide better decisions.
Despite these benefits, data lakes weren't initially designed with database-like capabilities. A data lake doesn't provide support for atomicity, consistency, isolation, and durability (ACID) processing semantics, which you might require to optimize and manage your data effectively at scale across hundreds or thousands of users by using many different technologies. Data lakes don't provide native support for the following functionality:
-
Performing efficient record-level updates and deletions as data changes in your business
-
Managing query performance as tables grow to millions of files and hundreds of thousands of partitions
-
Ensuring data consistency across multiple concurrent writers and readers
-
Preventing data corruption when write operations fail partway through the operation
-
Evolving table schemas over time without (partially) rewriting datasets
These challenges have become particularly prevalent in use cases such as handling change data capture (CDC) or use cases pertaining to privacy, deletion of data, and streaming data ingestion, which can result in sub-optimal tables.
Data lakes that use the traditional Hive-format tables support write operations only for entire files. This makes updates and deletes difficult to implement, time consuming, and costly. Moreover, concurrency controls and guarantees offered in ACID-compliant systems are needed to ensure data integrity and consistency.
These challenges leave users with a dilemma: choose between a fully integrated but proprietary platform, or opt for a vendor-neutral but resource-intensive, self-built data lake that requires constant maintenance and migration to realize its potential value.
To help overcome these challenges, Iceberg provides additional database-like
functionality that simplifies the optimization and management overhead of data lakes,
while still supporting storage on cost-effective systems such as Amazon S3
Introduction to Apache Iceberg
Apache Iceberg is an open-source table format that provides features in data lake tables that were historically only available in databases or data warehouses. It's designed for scale and performance, and is well-suited for managing tables that are over hundreds of gigabytes. Some of the main features of Iceberg tables are:
-
Delete, update, and merge. Iceberg supports standard SQL commands for data warehousing for use with data lake tables.
-
Fast scan planning and advanced filtering. Iceberg stores metadata such as partition and column-level statistics that can be used by engines to speed up planning and running queries.
-
Full schema evolution. Iceberg supports adding, dropping, updating, or renaming columns without side-effects.
-
Partition evolution. You can update the partition layout of a table as data volume or query patterns change. Iceberg supports changing the columns that a table is partitioned on, or adding columns to, or removing columns from, composite partitions.
-
Hidden partitioning. This feature prevents reading unnecessary partitions automatically. This eliminates the need for users to understand the table's partitioning details or to add extra filters to their queries.
-
Version rollback. Users can quickly correct problems by reverting to a pre-transaction state.
-
Time travel. Users can query a specific previous version of a table.
-
Serializable isolation. Table changes are atomic, so readers never see partial or uncommitted changes.
-
Concurrent writers. Iceberg uses optimistic concurrency to allow multiple transactions to succeed. In case of conflicts, one of the writers has to retry the transaction.
-
Open file formats. Iceberg supports multiple open source file formats, including Apache Parquet
, Apache Avro , and Apache ORC .
In summary, data lakes that use the Iceberg format benefit from transactional
consistency, speed, scale, and schema evolution. For more information about these and
other Iceberg features, see the Apache Iceberg documentation
AWS support for Apache Iceberg
Apache Iceberg is supported by AWS services such as Amazon EMR
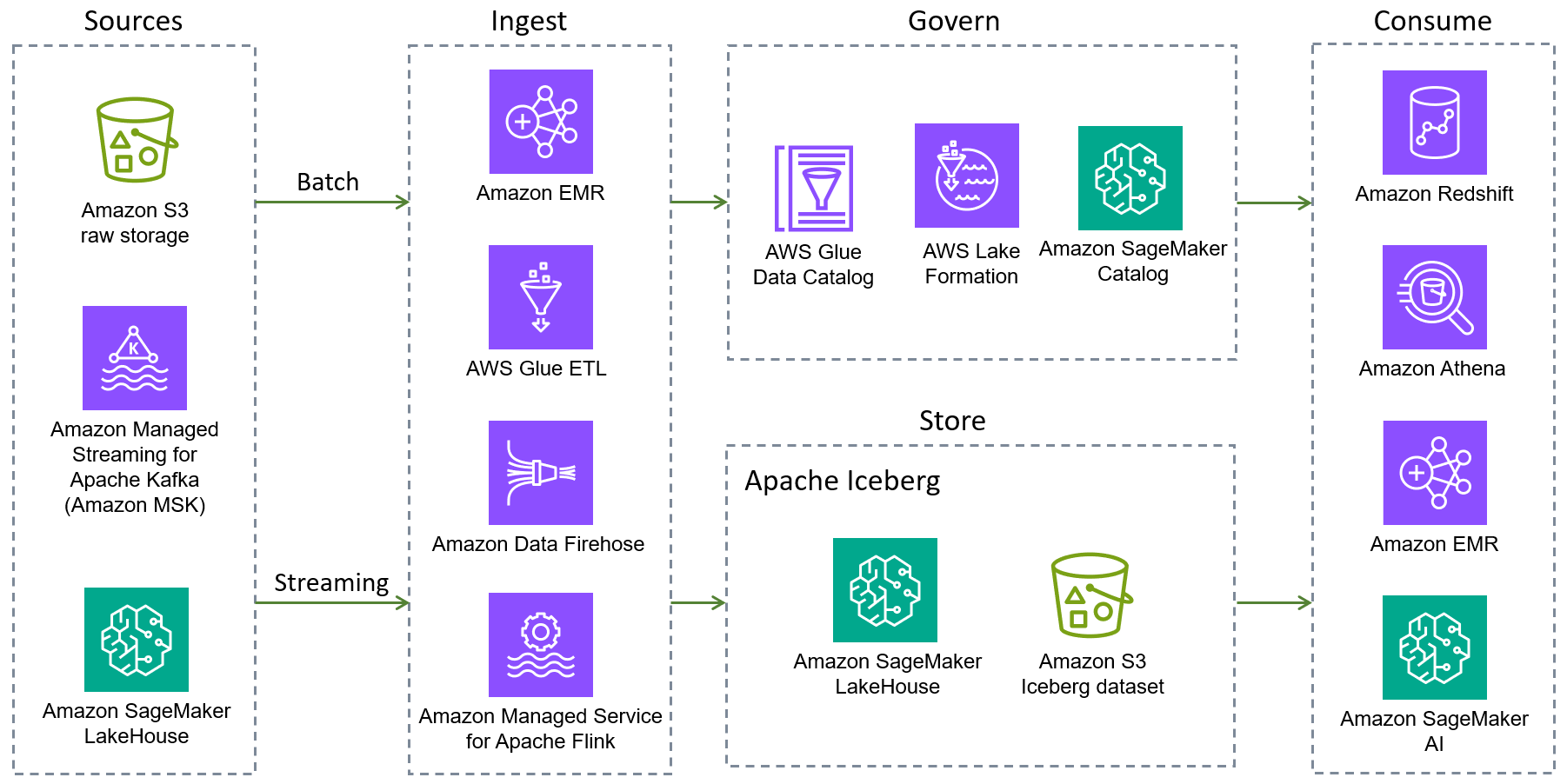
The following AWS services provide native Iceberg integrations. There are additional AWS services that can interact with Iceberg, either indirectly or by packaging the Iceberg libraries.
-
Amazon S3 is the best place to build data lakes because of its durability, availability, scalability, security, compliance, and audit capabilities. Iceberg was designed and built to interact with Amazon S3 seamlessly, and provides support for many Amazon S3 features as listed in the Iceberg documentation
. In addition, Amazon S3 Tables deliver the first cloud object store with built-in Iceberg support and streamline storing tabular data at scale. With S3 Tables support for Iceberg, you can easily query your tabular data by using popular AWS and third-party query engines. -
The next generation of SageMaker
is built on an open lakehouse architecture that unifies data access across Amazon S3 data lakes, Amazon Redshift data warehouses, and third-party and federated data sources. These capabilities help you build powerful analytics and AI/ML applications on a single copy of data. The lakehouse is fully compatible with Iceberg, so you have the flexibility to access and query data in place by using the Iceberg REST API. -
Amazon EMR is a big data solution for petabyte-scale data processing, interactive analytics, and machine learning by using open source frameworks such as Apache Spark, Flink, Trino, and Hive. Amazon EMR can run on customized Amazon Elastic Compute Cloud (Amazon EC2) clusters, Amazon Elastic Kubernetes Service (Amazon EKS), AWS Outposts, or Amazon EMR Serverless.
-
Amazon Athena is a serverless, interactive analytics service that's built on open source frameworks. It supports open-table and file formats and provides a simplified, flexible way to analyze petabytes of data where it lives. Athena provides native support for read, time travel, write, and DDL queries for Iceberg and uses the AWS Glue Data Catalog for the Iceberg metastore.
-
Amazon Redshift is a petabyte-scale cloud data warehouse that supports both cluster-based and serverless deployment options. Amazon Redshift Spectrum can query external tables that are registered with the AWS Glue Data Catalog and stored on Amazon S3. Redshift Spectrum also provides support for the Iceberg storage format.
-
AWS Glue is a serverless data integration service that makes it easier to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML), and application development. It is fully integrated with Iceberg. Specifically, you can perform read and write operations on Iceberg tables by using AWS Glue jobs, manage tables through the AWS Glue Data Catalog (Hive metastore-compatible), discover and register tables automatically by using AWS Glue crawlers, and evaluate data quality in Iceberg tables through the AWS Glue Data Quality feature. The AWS Glue Data Catalog also supports collecting column statistics, calculating and updating the number of distinct values (NDVs) for each column in Iceberg tables, and automatic table optimizations (compaction, snapshot retention, orphan file deletion). AWS Glue also supports zero-ETL integrations from a list of AWS services and third-party applications into Iceberg tables.
-
Amazon Data Firehose is a fully managed service for delivering real-time streaming data to destinations such as Amazon S3, Amazon Redshift, Amazon OpenSearch Service, Amazon OpenSearch Serverless, Splunk, Apache Iceberg tables, and any custom HTTP or HTTP endpoints owned by supported third-party service providers, including Datadog, Dynatrace, LogicMonitor, MongoDB, New Relic, Coralogix, and Elastic. With Firehose, you don't need to write applications or manage resources. You configure your data producers to send data to Firehose, and it automatically delivers the data to the destination that you specified. You can also configure Firehose to transform your data before delivering it.
-
Amazon Managed Service for Apache Flink is a fully managed Amazon service that lets you use an Apache Flink application to process streaming data. It supports both reading from and writing to Iceberg tables, and enables real-time data processing and analytics.
-
Amazon SageMaker AI supports the storage of feature sets in Amazon SageMaker AI Feature Store by using Iceberg format.
-
AWS Lake Formation provides coarse and fine-grained access control permissions to access data, including Iceberg tables consumed by Athena or Amazon Redshift. To learn more about permissions support for Iceberg tables, see the Lake Formation documentation.
AWS has a wide range of services that support Iceberg, but covering all these services is beyond the scope of this guide. The following sections cover Spark (batch and structured streaming) on Amazon EMR and AWS Glue, as well as Athena SQL. The following section provides a quick look at Iceberg support in Athena SQL.
