기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
상태 모니터링 시스템
SageMaker HyperPod 상태 모니터링 시스템에는 두 가지 구성 요소가 포함되어 있습니다.
-
호스트 상태 모니터 역할을 하는 상태 모니터링 에이전트(HMA)와 out-of-node 상태 모니터 세트를 포함하여 노드에 설치된 에이전트를 모니터링합니다.
-
SageMaker HyperPod에서 관리하는 노드 복구 시스템. 상태 모니터링 시스템은 모니터링 에이전트를 통해 노드 상태를 지속적으로 모니터링한 다음 노드 복구 시스템을 사용하여 장애가 감지되면 자동으로 조치를 취합니다.

SageMaker HyperPod 상태 모니터링 에이전트에서 수행하는 상태 확인
SageMaker HyperPod 상태 모니터링 에이전트는 다음을 확인합니다.
NVIDIA GPU
-
nvidia-smi출력 오류 -
Amazon Elastic Compute Cloud(EC2) 플랫폼에서 생성된 로그의 다양한 오류
-
GPU 개수 검증 - 특정 인스턴스 유형의 예상 GPUs 수(예: ml.p5.48xlarge 인스턴스 유형의 GPUs 8개)와에서 반환한 개수 간에 불일치가 있는 경우
nvidia-smiHMA는 노드를 재부팅합니다.
AWS훈련
-
AWS Neuron 모니터
의 출력 오류 -
Neuron 노드 문제 감지기에 의해 생성된 출력( AWSNeuron 노드 문제 감지기에 대한 자세한 내용은 Amazon EKS 클러스터 내의 AWSNeuron 노드에 대한 노드 문제 감지 및 복구를 참조하세요
.) -
Amazon EC2 플랫폼에서 생성된 로그의 다양한 오류
-
Neuron 디바이스 수 검증 - 특정 인스턴스 유형의 실제 뉴런 디바이스 수와에서 반환한 수 간에 불일치가 있는 경우
neuron-lsHMA는 노드를 재부팅합니다.
위의 검사는 노드에서 HyperPod가 지속적으로 실행되는 수동 백그라운드 상태 확인입니다. 이러한 검사 외에도 HyperPod는 HyperPod 클러스터를 생성하고 업데이트하는 동안 심층(또는 활성) 상태 확인도 실행합니다. 심층 상태 확인에 대해 자세히 알아봅니다.
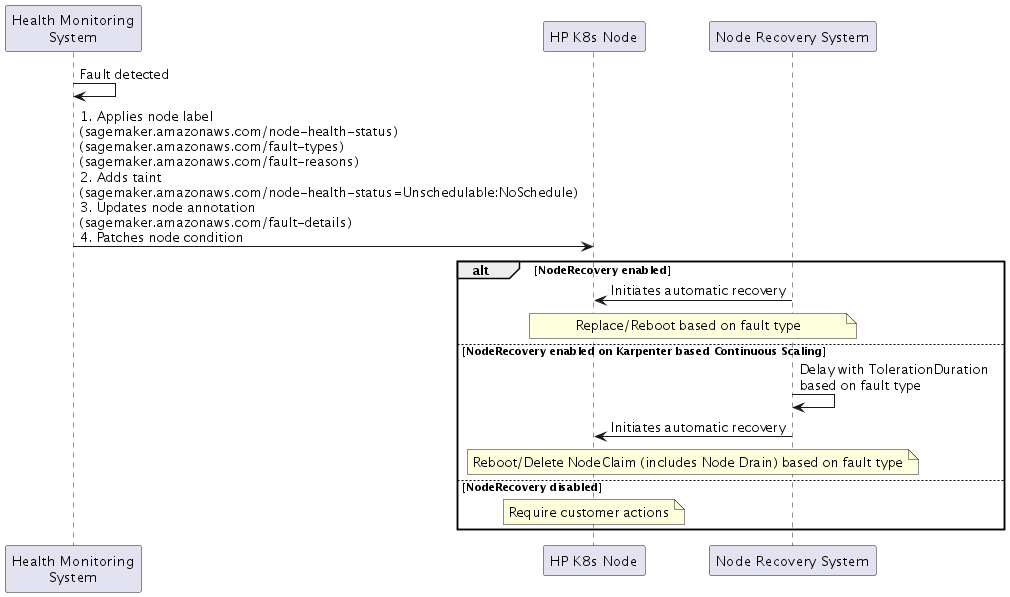
결함 감지
SageMaker HyperPod는 장애를 감지하면 네 부분으로 구성된 응답을 구현합니다.
-
노드 레이블
-
상태:
sagemaker.amazonaws.com/node-health-status -
결함 유형: 상위 수준 분류를 위한
sagemaker.amazonaws.com/fault-types레이블 -
결함 이유: 자세한 결함 정보에 대한
sagemaker.amazonaws.com/fault-reasons레이블
-
-
노드 테인트
-
sagemaker.amazonaws.com/node-health-status=Unschedulable:NoSchedule
-
-
노드 주석
-
결함 세부 정보:
sagemaker.amazonaws.com/fault-details -
노드에서 발생한 타임스탬프로 최대 20개의 오류를 기록합니다.
-
-
노드 조건(Kubernetes 노드 조건
) -
노드 조건의 현재 상태를 반영합니다.
-
유형: 결함 유형과 동일
-
상태:
True -
이유: 결함 이유와 동일
-
LastTransitionTime: 결함 발생 시간
-
-
SageMaker HyperPod 상태 모니터링 에이전트에서 생성된 로그
SageMaker HyperPod 상태 모니터링 에이전트는 즉시 사용 가능한 상태 확인 기능이며 모든 HyperPod 클러스터에서 지속적으로 실행됩니다. 상태 모니터링 에이전트는 클러스터 로그 그룹 /aws/sagemaker/Clusters/의 CloudWatch에 GPU 또는 Trn 인스턴스에서 감지된 상태 이벤트를 게시합니다.
HyperPod 상태 모니터링 에이전트의 감지 로그는 각 노드에 대해 SagemakerHealthMonitoringAgent 이름이 지정된 별도의 로그 스트림으로 생성됩니다. 다음과 같이 CloudWatch 로그 인사이트를 사용하여 감지 로그를 쿼리할 수 있습니다.
fields @timestamp, @message | filter @message like /HealthMonitoringAgentDetectionEvent/
이는 다음과 비슷한 출력을 반환합니다.
2024-08-21T11:35:35.532-07:00 {"level":"info","ts":"2024-08-21T18:35:35Z","msg":"NPD caught event: %v","details: ":{"severity":"warn","timestamp":"2024-08-22T20:59:29Z","reason":"XidHardwareFailure","message":"Node condition NvidiaErrorReboot is now: True, reason: XidHardwareFailure, message: \"NVRM: Xid (PCI:0000:b9:00): 71, pid=<unknown>, name=<unknown>, NVLink: fatal error detected on link 6(0x10000, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0)\""},"HealthMonitoringAgentDetectionEvent":"HealthEvent"} 2024-08-21T11:35:35.532-07:00 {"level":"info","ts":"2024-08-21T18:35:35Z","msg":"NPD caught event: %v","details: ":{"severity":"warn","timestamp":"2024-08-22T20:59:29Z","reason":"XidHardwareFailure","message":"Node condition NvidiaErrorReboot is now: True, reason: XidHardwareFailure, message: \"NVRM: Xid (PCI:0000:b9:00): 71, pid=<unknown>, name=<unknown>, NVLink: fatal error detected on link 6(0x10000, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0)\""},"HealthMonitoringAgentDetectionEvent":"HealthEvent"}
