기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
조정 훈련
다음 섹션에서는 훈련을 확장할 수 있는 시나리오와 AWS 리소스를 사용하여 확장하는 방법을 다룹니다. 다음 상황 중 하나에서 훈련을 확장할 수 있습니다.
-
단일 GPU에서 여러 GPU로 확장
-
단일 인스턴스에서 다중 인스턴스로 확장
-
사용자 지정 훈련 스크립트 사용
단일 GPU에서 여러 GPU로 확장
기계 학습에 사용되는 데이터의 양이나 모델 크기로 인해 모델을 훈련하는 데 걸리는 시간이 기다릴 수 있는 시간보다 길어지는 상황이 발생할 수 있습니다. 모델이나 훈련 데이터가 너무 커서 훈련이 전혀 작동하지 않기도 합니다. 이 떄 한 가지 솔루션은 훈련에 사용하는 GPU 수를 늘리는 것입니다. GPU가 8개인 p3.16xlarge와(과) 같이 GPU가 여러 개인 인스턴스에서는 데이터와 처리가 8개의 GPU로 분할됩니다. 분산 훈련 라이브러리를 사용하면 모델을 훈련하는 데 걸리는 시간이 거의 선형적으로 빨라질 수 있습니다. 하나의 GPU로 p3.2xlarge에서 처리했을 때의 소요되는 시간의 약 1/8보다 조금 더 걸리는 수준입니다.
| 인스턴스 유형 | GPU |
|---|---|
| p3.2xlarge | 1 |
| p3.8xlarge | 4 |
| p3.16xlarge | 8 |
| p3dn.24xlarge | 8 |
참고
SageMaker 훈련에 사용되는 ml 인스턴스 유형에는 해당하는 p3 인스턴스 유형과 동일한 수의 GPU가 있습니다. 예를 들어, ml.p3.8xlarge의 GPU 수는 p3.8xlarge와(과) 같이 4개입니다.
단일 인스턴스에서 다중 인스턴스로 확장
훈련을 더 확장하고 싶다면 더 많은 인스턴스를 사용할 수 있습니다. 하지만 인스턴스를 더 추가하기 전에 더 큰 인스턴스 유형을 선택해야 합니다. 이전 테이블을 검토하여 각 p3 인스턴스 유형에 몇 개의 GPU가 있는지 확인하세요.
p3.2xlarge의 단일 GPU에서 p3.8xlarge의 GPU 4개로 전환했지만 더 많은 처리 성능이 필요하다고 판단한 경우 인스턴스 수를 늘리기 전에 p3.16xlarge을(를) 선택하면 성능이 향상되고 비용이 절감될 수 있습니다. 사용하는 라이브러리에 따라 다르지만, 단일 인스턴스에서 계속 훈련하는 것이 여러 인스턴스를 사용하는 시나리오보다 성능이 향상되고 비용도 절감됩니다.
인스턴스 수를 확장할 준비가 되면 SageMaker AI Python SDK estimator 기능에 instance_count를 설정하여 이 작업을 수행할 수 있습니다. 예를 들어 instance_type = p3.16xlarge와(과) instance_count =
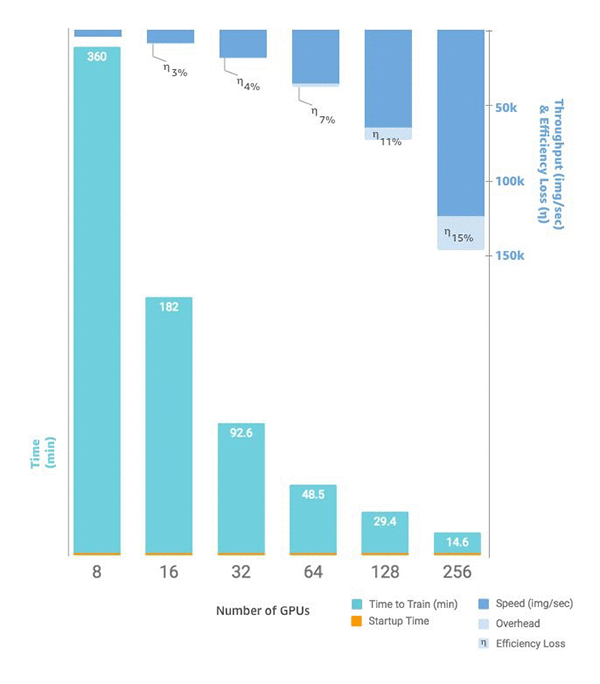
2을(를) 설정할 수 있습니다. 단일 인스턴스 p3.16xlarge에 8개의 GPU를 사용하는 대신 두 개의 동일한 인스턴스에 16개의 GPU를 사용할 수 있습니다. 다음 차트는 단일 인스턴스에서 8개의 GPU로 시작하여
사용자 지정 훈련 스크립트
SageMaker AI를 사용하면 인스턴스 및 GPU 수를 간단하게 배포하고 확장할 수 있지만 선택한 프레임워크에 따라 데이터와 결과를 관리하는 것은 매우 어려울 수 있으므로 외부 지원 라이브러리가 자주 사용됩니다. 이 가장 기본적인 형태의 분산 훈련을 수행하려면 훈련 스크립트를 수정하여 데이터 분산을 관리해야 합니다.
또한 SageMaker AI는 Horovod와 각 주요 딥 러닝 프레임워크에 기본으로 제공되는 분산 훈련 구현을 지원합니다. 이러한 프레임워크의 예시를 사용하기로 선택한 경우 딥 러닝 컨테이너용 SageMaker AI의 컨테이너 가이드와 구현을 보여주는 다양한 예시 노트북
