기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
# 코드 예제: SDK for Python
이 섹션은 SageMaker Calify의 온라인 설명 가능성을 사용하는 엔드포인트를 생성하고 간접 호출하기 위한 샘플 코드를 제공합니다. 다음 코드 예제는 [AWS SDK for Python](https://aws.amazon.com/sdk-for-python/)을 사용합니다.
## 테이블 형식 데이터
다음 예시에서는 테이블 형식 데이터와 `model_name`이라는 SageMaker AI 모델을 사용합니다. 이 예제에서 모델 컨테이너는 CSV 형식의 데이터를 받아들이고 각 레코드에는 네 가지 수치적 특징이 있습니다. 이 최소 구성에서는 **데모용으로 사용하기 위해** SHAP 기준 데이터가 0으로 설정됩니다. `ShapBaseline`에 더 적합한 값을 선택하는 방법은 [설명 가능성에 대한 SHAP 기준](clarify-feature-attribute-shap-baselines.md) 섹션을 참조하세요.
다음과 같이 엔드포인트를 구성합니다.
```
endpoint_config_name = 'tabular_explainer_endpoint_config'
response = sagemaker_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[{
'VariantName': 'AllTraffic',
'ModelName': model_name,
'InitialInstanceCount': 1,
'InstanceType': 'ml.m5.xlarge',
}],
ExplainerConfig={
'ClarifyExplainerConfig': {
'ShapConfig': {
'ShapBaselineConfig': {
'ShapBaseline': '0,0,0,0',
},
},
},
},
)
```
다음과 같이 엔드포인트 구성을 사용하여 엔드포인트를 생성하세요.
```
endpoint_name = 'tabular_explainer_endpoint'
response = sagemaker_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name,
)
```
`DescribeEndpoint` API를 사용하여 다음과 같이 엔드포인트 생성 진행 상태를 검사하세요.
```
response = sagemaker_client.describe_endpoint(
EndpointName=endpoint_name,
)
response['EndpointStatus']
```
엔드포인트 상태가 “서비스 중”이 되면 다음과 같이 테스트 레코드로 엔드포인트를 간접 호출합니다.
```
response = sagemaker_runtime_client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType='text/csv',
Accept='text/csv',
Body='1,2,3,4',
)
```
**참고**
이전 코드 예제에서 다중 모델 엔드포인트의 경우 요청에 추가 `TargetModel` 파라미터를 전달하여 엔드포인트에서 대상으로 지정할 모델을 지정합니다.
응답의 상태 코드가 200(오류 없음)이라고 가정하고 다음과 같이 응답 본문을 로드합니다.
```
import codecs
import json
json.load(codecs.getreader('utf-8')(response['Body']))
```
엔드포인트의 기본 작업은 레코드를 설명하는 것입니다. 다음 예제는 반환된 JSON 객체의 출력을 보여줍니다.
```
{
"version": "1.0",
"predictions": {
"content_type": "text/csv; charset=utf-8",
"data": "0.0006380207487381"
},
"explanations": {
"kernel_shap": [
[
{
"attributions": [
{
"attribution": [-0.00433456]
}
]
},
{
"attributions": [
{
"attribution": [-0.005369821]
}
]
},
{
"attributions": [
{
"attribution": [0.007917749]
}
]
},
{
"attributions": [
{
"attribution": [-0.00261214]
}
]
}
]
]
}
}
```
`EnableExplanations` 파라미터를 사용하면 다음과 같이 온디맨드 설명을 활성화할 수 있습니다.
```
response = sagemaker_runtime_client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType='text/csv',
Accept='text/csv',
Body='1,2,3,4',
EnableExplanations='[0]>`0.8`',
)
```
**참고**
이전 코드 예제에서 다중 모델 엔드포인트의 경우 요청에 추가 `TargetModel` 파라미터를 전달하여 엔드포인트에서 대상으로 지정할 모델을 지정합니다.
이 예시에서는 예측값이 `0.8`의 임곗값보다 작으므로 레코드가 설명되지 않습니다.
```
{
"version": "1.0",
"predictions": {
"content_type": "text/csv; charset=utf-8",
"data": "0.6380207487381995"
},
"explanations": {}
}
```
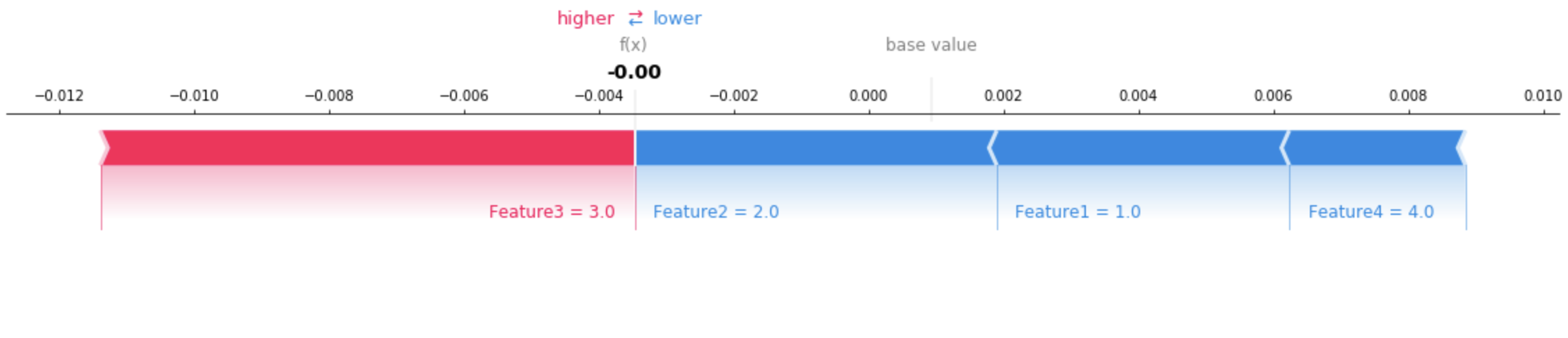
시각화 도구를 사용하면 반환된 설명을 해석하는 데 도움이 됩니다. 다음 이미지는 SHAP 플롯을 사용하여 각 특징이 예측에 어떻게 기여하는지 이해하는 방법을 보여줍니다. 다이어그램의 기본값(예상 값이라고도 함)은 훈련 데이터세트의 평균 예측값입니다. 기대값을 더 높게 올리는 특징은 빨간색이고, 기대값을 낮게 내리는 특징은 파란색입니다. 자세한 내용은 [SHAP 추가 포스 레이아웃](https://shap.readthedocs.io/en/latest/generated/shap.plots.force.html)을 참조하세요.
[테이블 형식의 데이터에 대한 전체 예제 노트북](https://github.com/aws/amazon-sagemaker-examples/blob/main/sagemaker-clarify/online_explainability/tabular/tabular_online_explainability_with_sagemaker_clarify.ipynb)을 참조하세요.
## 텍스트 데이터
이 섹션은 텍스트 데이터에 대한 온라인 설명 가능성 엔드포인트를 생성하고 간접 호출하는 코드 예제를 제공합니다. SDK for Python을 사용하는 코드 예제.
다음 예시는 텍스트 데이터와 `model_name`이라는 SageMaker AI 모델을 사용합니다. 이 예제에서 모델 컨테이너는 CSV 형식의 데이터를 받아들이고 각 레코드는 단일 문자열입니다.
```
endpoint_config_name = 'text_explainer_endpoint_config'
response = sagemaker_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[{
'VariantName': 'AllTraffic',
'ModelName': model_name,
'InitialInstanceCount': 1,
'InstanceType': 'ml.m5.xlarge',
}],
ExplainerConfig={
'ClarifyExplainerConfig': {
'InferenceConfig': {
'FeatureTypes': ['text'],
'MaxRecordCount': 100,
},
'ShapConfig': {
'ShapBaselineConfig': {
'ShapBaseline': '""',
},
'TextConfig': {
'Granularity': 'token',
'Language': 'en',
},
'NumberOfSamples': 100,
},
},
},
)
```
+ `ShapBaseline`: 자연어 처리(NLP) 프로세스를 위해 예약된 특수 토큰입니다.
+ `FeatureTypes`: 기능을 텍스트로 식별합니다. 이 파라미터를 제공하지 않으면 설명자가 기능 유형을 추론하려고 시도합니다.
+ `TextConfig`: 텍스트 특징 분석을 위한 세분성 단위와 언어를 지정합니다. 이 예제에서 언어는 영어이고, 세분성 `token`은 영어 텍스트로 된 단어를 의미합니다.
+ `NumberOfSamples`: 합성 데이터세트 크기의 상한을 설정하기 위한 제한입니다.
+ `MaxRecordCount`: 요청에서 모델 컨테이너가 처리할 수 있는 최대 레코드 수입니다. 이 파라미터가 성능 안정화를 위해 설정됩니다.
다음과 같이 엔드포인트 구성을 사용하여 엔드포인트를 생성하세요.
```
endpoint_name = 'text_explainer_endpoint'
response = sagemaker_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name,
)
```
엔드포인트의 상태가 `InService`가 되면 엔드포인트를 간접 호출합니다. 다음 코드 샘플은 다음과 같이 테스트 레코드를 사용합니다.
```
response = sagemaker_runtime_client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType='text/csv',
Accept='text/csv',
Body='"This is a good product"',
)
```
요청이 성공적으로 완료되면 응답 본문은 다음과 유사한 유효한 JSON 객체를 반환합니다.
```
{
"version": "1.0",
"predictions": {
"content_type": "text/csv",
"data": "0.9766594\n"
},
"explanations": {
"kernel_shap": [
[
{
"attributions": [
{
"attribution": [
-0.007270948666666712
],
"description": {
"partial_text": "This",
"start_idx": 0
}
},
{
"attribution": [
-0.018199033666666628
],
"description": {
"partial_text": "is",
"start_idx": 5
}
},
{
"attribution": [
0.01970993241666666
],
"description": {
"partial_text": "a",
"start_idx": 8
}
},
{
"attribution": [
0.1253469515833334
],
"description": {
"partial_text": "good",
"start_idx": 10
}
},
{
"attribution": [
0.03291143366666657
],
"description": {
"partial_text": "product",
"start_idx": 15
}
}
],
"feature_type": "text"
}
]
]
}
}
```
시각화 도구를 사용하면 반환된 텍스트 속성을 해석하는 데 도움이 됩니다. 다음 이미지는 캡텀 시각화 유틸리티를 사용하여 각 단어가 예측에 미치는 영향을 이해하는 방법을 보여줍니다. 채도가 높을수록 단어의 중요도가 높아집니다. 이 예제에서 채도가 높은 밝은 빨간색은 부정적인 기여도가 높음을 나타냅니다. 채도가 높은 녹색은 긍정적인 기여도가 높음을 나타냅니다. 흰색은 단어의 기여도가 중립적임을 나타냅니다. 속성의 파싱 및 렌더링에 대한 추가 정보는 [캡텀](https://github.com/pytorch/captum) 라이브러리를 참조하세요.

[텍스트 데이터에 대한 전체 예제 노트북](https://github.com/aws/amazon-sagemaker-examples/blob/main/sagemaker-clarify/online_explainability/natural_language_processing/nlp_online_explainability_with_sagemaker_clarify.ipynb)을 참조하세요.