기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
데이터 준비 단계
Amazon Quick Sight의 데이터 준비 경험은 데이터를 체계적으로 변환할 수 있는 11가지 강력한 단계 유형을 제공합니다. 각 단계는 데이터 준비 워크플로에서 특정 목적을 수행합니다.
단계는 구성 창의 직관적인 인터페이스를 통해 구성할 수 있으며, 미리 보기 창에 즉각적인 피드백이 표시됩니다. 단계를 순차적으로 결합하여 SQL 전문 지식 없이도 정교한 데이터 변환을 생성할 수 있습니다.
각 단계는 물리적 테이블 또는 이전 단계의 출력에서 입력을 수신할 수 있습니다. 대부분의 단계에서는 단일 입력을 허용하며 추가 및 조인 단계는 예외입니다. 이러한 단계에는 정확히 두 개의 입력이 필요합니다.
Input
입력 단계는 후속 단계에서 변환을 위해 여러 소스에서 데이터를 선택하고 가져올 수 있도록 하여 Quick Sight에서 데이터 준비 워크플로를 시작합니다.
입력 옵션
-
데이터 세트 추가
기존 Quick Sight 데이터 세트를 입력 소스로 활용하여 팀이 이미 준비하고 최적화한 데이터를 기반으로 구축합니다.
-
데이터 소스 추가
특정 데이터베이스 객체를 선택하고 연결 파라미터를 제공하여 Amazon Redshift, Athena, RDS 또는 기타 지원되는 소스와 같은 데이터베이스에 직접 연결합니다.
-
파일 업로드 추가
CSV, TSV, Excel 또는 JSON과 같은 형식으로 로컬 파일에서 직접 데이터를 가져옵니다.
구성
입력 단계에는 구성이 필요하지 않습니다. 미리 보기 창에는 가져온 데이터가 연결 세부 정보, 테이블 이름 및 열 메타데이터를 포함한 소스 정보와 함께 표시됩니다.
사용 노트
-
단일 워크플로 내에 여러 입력 단계가 존재할 수 있습니다.
-
워크플로의 언제든지 입력 단계를 추가할 수 있습니다.
계산된 열 추가
계산된 열 추가 단계를 사용하면 기존 열에 대해 계산을 수행하는 행 수준 표현식을 사용하여 새 열을 생성할 수 있습니다. 스칼라(행 수준) 함수와 연산자를 사용하여 새 열을 생성하고 기존 열을 참조하는 행 수준 계산을 적용할 수 있습니다.
구성
계산된 열 추가 단계를 구성하려면 구성 창에서 다음을 수행합니다.
사용 노트
-
이 단계에서는 스칼라(행 수준) 계산만 지원됩니다.
-
SPICE에서는 계산된 열이 구체화되고 후속 단계에서 표준 열로 작동합니다.
데이터 유형 변경
Quick Sight는 date, , 및의 4가지 추상 데이터 형식을 지원하여 데이터 형식 관리를 간소화decimalinteger합니다string. 이러한 추상 유형은 다양한 소스 데이터 형식을 Quick Sight에 자동으로 매핑하여 복잡성을 제거합니다. 예를 들어, , tinyintinteger, 및 smallintbigint는 모두에 매핑되는 반면integer, datetime, 및 datetimestamp는에 매핑됩니다date.
Quick Sight는 다양한 데이터 소스와 상호 작용할 때 모든 기본 데이터 유형 변환 및 계산을 자동으로 처리하므로 Quick Sight의 네 가지 데이터 유형만 이해하면 됩니다.
구성
데이터 유형 변경 단계를 구성하려면 구성 창에서 다음을 수행합니다.
-
변환할 열을 선택합니다.
-
대상 데이터 유형(
string,decimal, 또는integerdate)을 선택합니다. -
날짜 변환의 경우 입력 형식을 기반으로 형식 설정 및 미리 보기 결과를 지정합니다. Quick Sight에서 지원되는 날짜 형식을 참조하세요.
-
필요에 따라 변환할 열을 추가합니다.
사용 노트
-
효율성을 위해 한 번에 여러 열의 데이터 형식을 변환합니다.
-
SPICE를 사용하면 가져온 데이터에 모든 데이터 형식 변경이 구체화됩니다.
열 이름 바꾸기
열 이름 바꾸기 단계를 사용하면 열 이름을 보다 설명적이고 사용자 친화적이며 조직의 이름 지정 규칙에 맞게 수정할 수 있습니다.
구성
열 이름 바꾸기 단계를 구성하려면 구성 창에서 다음을 수행합니다.
-
이름을 지정할 열을 선택합니다.
-
선택한 열의 새 이름을 입력합니다.
-
필요에 따라 이름을 바꿀 열을 더 추가합니다.
사용 노트
-
모든 열 이름은 데이터 세트 내에서 고유해야 합니다.
열 선택
열 선택 단계를 사용하면 열을 포함, 제외 및 재정렬하여 데이터 세트를 간소화할 수 있습니다. 이렇게 하면 불필요한 열을 제거하고 분석을 위해 나머지 열을 논리적 시퀀스로 구성하여 데이터 구조를 최적화할 수 있습니다.
구성
열 선택 단계를 구성하려면 구성 창에서 다음을 수행합니다.
-
출력에 포함할 특정 열을 선택합니다.
-
원하는 순서대로 열을 선택하여 시퀀스를 설정합니다.
-
모두 선택을 사용하여 나머지 열을 원래 순서로 포함합니다.
-
원치 않는 열은 선택하지 않은 상태로 두어 제외합니다.
주요 기능
-
출력 열은 선택 순서대로 표시됩니다.
-
모두 선택은 원래 열 시퀀스를 보존합니다.
사용 노트
-
선택하지 않은 열은 후속 단계에서 제거됩니다.
-
불필요한 열을 제거하여 데이터 세트 크기를 최적화합니다.
Append
추가 단계에서는 SQL UNION ALL 작업과 유사한 두 테이블을 수직으로 결합합니다. Quick Sight는 시퀀스가 아닌 이름별로 열을 자동으로 일치시켜 테이블의 열 순서가 다르거나 열 수가 다르더라도 효율적인 데이터 통합을 지원합니다.
구성
추가 단계를 구성하려면 구성 창에서 다음을 수행합니다.
-
추가할 입력 테이블 2개를 선택합니다.
-
출력 열 시퀀스를 검토합니다.
-
두 테이블 모두에 있는 열과 단일 테이블에 있는 열을 검사합니다.
주요 기능
-
시퀀스 대신 이름별로 열을 일치시킵니다.
-
중복을 포함하여 두 테이블의 모든 행을 유지합니다.
-
열 수가 서로 다른 테이블을 지원합니다.
-
일치하는 열에 대한 표 1의 열 시퀀스를 따른 다음 표 2에서 고유한 열을 추가합니다.
-
모든 열에 대한 명확한 소스 표시기를 표시합니다.
사용 노트
-
이름이 다른 열을 추가할 때는 먼저 이름 바꾸기 단계를 사용합니다.
-
각 추가 단계는 정확히 두 개의 테이블을 결합합니다. 더 많은 테이블에 대해 추가 추가 단계를 사용합니다.
조인
Join 단계는 지정된 열의 일치하는 값을 기반으로 두 테이블의 데이터를 수평적으로 결합합니다. Quick Sight는 왼쪽 외부, 오른쪽 외부, 전체 외부 및 내부 조인 유형을 지원하여 분석 요구 사항에 맞는 유연한 옵션을 제공합니다. 이 단계에는 중복 열 이름을 자동으로 처리하는 지능형 열 충돌 해결이 포함되어 있습니다. 자체 조인은 특정 조인 유형으로 사용할 수 없지만 워크플로 발산을 사용하여 유사한 결과를 얻을 수 있습니다.
구성
조인 단계를 구성하려면 구성 창에서 다음을 수행합니다.
-
조인할 두 개의 입력 테이블을 선택합니다.
-
조인 유형(왼쪽 외부, 오른쪽 외부, 전체 외부 또는 내부)을 선택합니다.
-
각 테이블에서 조인 키를 지정합니다.
-
자동 해결된 열 이름 충돌을 검토합니다.
주요 기능
-
다양한 분석 요구 사항에 맞게 여러 조인 유형을 지원합니다.
-
중복된 열 이름을 자동으로 확인합니다.
-
계산된 열을 조인 키로 허용합니다.
사용 노트
-
조인 키에는 호환되는 데이터 형식이 있어야 합니다. 필요한 경우 데이터 형식 변경 단계를 사용합니다.
-
각 조인 단계는 정확히 두 개의 테이블을 결합합니다. 더 많은 테이블에는 추가 조인 단계를 사용합니다.
-
조인 후 이름 바꾸기 단계를 생성하여 자동 해결된 열 헤더를 사용자 지정합니다.
Aggregate
집계 단계를 사용하면 열을 그룹화하고 집계 작업을 적용하여 데이터를 요약할 수 있습니다. 이 강력한 변환은 세부 데이터를 지정된 차원을 기반으로 의미 있는 요약으로 압축합니다. Quick Sight는 직관적인 인터페이스를 통해 복잡한 SQL 작업을 간소화하여 ListAgg 및와 같은 고급 문자열 작업을 포함한 포괄적인 집계 함수를 제공합니다ListAgg distinct.
구성
집계 단계를 구성하려면 구성 창에서 다음을 수행합니다.
-
그룹화할 열을 선택합니다.
-
측정 열에 대한 집계 함수를 선택합니다.
-
출력 열 이름을 사용자 지정합니다.
-
ListAgg및ListAgg distinct의 경우:-
집계할 열을 선택합니다.
-
구분자(쉼표, 대시, 세미콜론 또는 세로선)를 선택합니다.
-
-
요약된 데이터를 미리 봅니다.
데이터 유형당 지원되는 함수
| 데이터 형식 | 지원되는 함수 |
|---|---|
|
Numeric |
|
|
Date |
|
|
문자열 |
|
주요 기능
-
동일한 단계 내의 열에 서로 다른 집계 함수를 적용합니다.
-
집계 함수가 없는 그룹화는 SQL SELECT DISTINCT 역할을 합니다.
-
ListAgg는 모든 값을 연결합니다. 에는 고유한 값만ListAgg distinct포함됩니다. -
ListAgg함수는 기본적으로 오름차순 정렬 순서를 유지합니다.
사용 노트
-
집계는 데이터 세트의 행 수를 크게 줄입니다.
-
ListAgg및는date값을ListAgg distinct지원하지만는 지원하지 않습니다datetime. -
구분자를 사용하여 문자열 연결 출력을 사용자 지정합니다.
필터
필터 단계를 사용하면 특정 기준을 충족하는 행만 포함하여 데이터세트의 범위를 좁힐 수 있습니다. 단일 단계 내에 여러 필터 조건을 적용할 수 있으며, 모두 AND 로직을 통해 결합되어 분석을 관련 데이터에 집중할 수 있습니다.
구성
필터 단계를 구성하려면 구성 창에서 다음을 수행합니다.
-
필터링할 열을 선택합니다.
-
비교 연산자를 선택합니다.
-
열의 데이터 유형에 따라 필터 값을 지정합니다.
-
필요한 경우 다른 열에 필터 조건을 추가합니다.
참고
-
"is in" 또는 "is not in"이 있는 문자열 필터: 여러 값(행당 하나)을 입력합니다.
-
숫자 및 날짜 필터: 단일 값을 입력합니다(두 값이 필요한 " 사이" 제외).
데이터 유형당 지원되는 연산자
| 데이터 형식 | 지원되는 연산자 |
|---|---|
|
정수 및 소수 |
같음, 같지 않음 보다 큼, 보다 작음 보다 크거나 같음, 보다 작거나 같음 사이에 있음 |
|
Date |
이후, 이전 사이에 있음 이후 또는 같음, 이전 또는 같음 |
|
문자열 |
같음, 같지 않음 로 시작, 로 종료 포함, 포함되지 않음 에 있음,에 없음 |
사용 노트
-
한 번에 여러 필터 조건을 적용합니다.
-
다양한 데이터 유형에 걸쳐 조건을 혼합합니다.
-
필터링된 결과를 실시간으로 미리 봅니다.
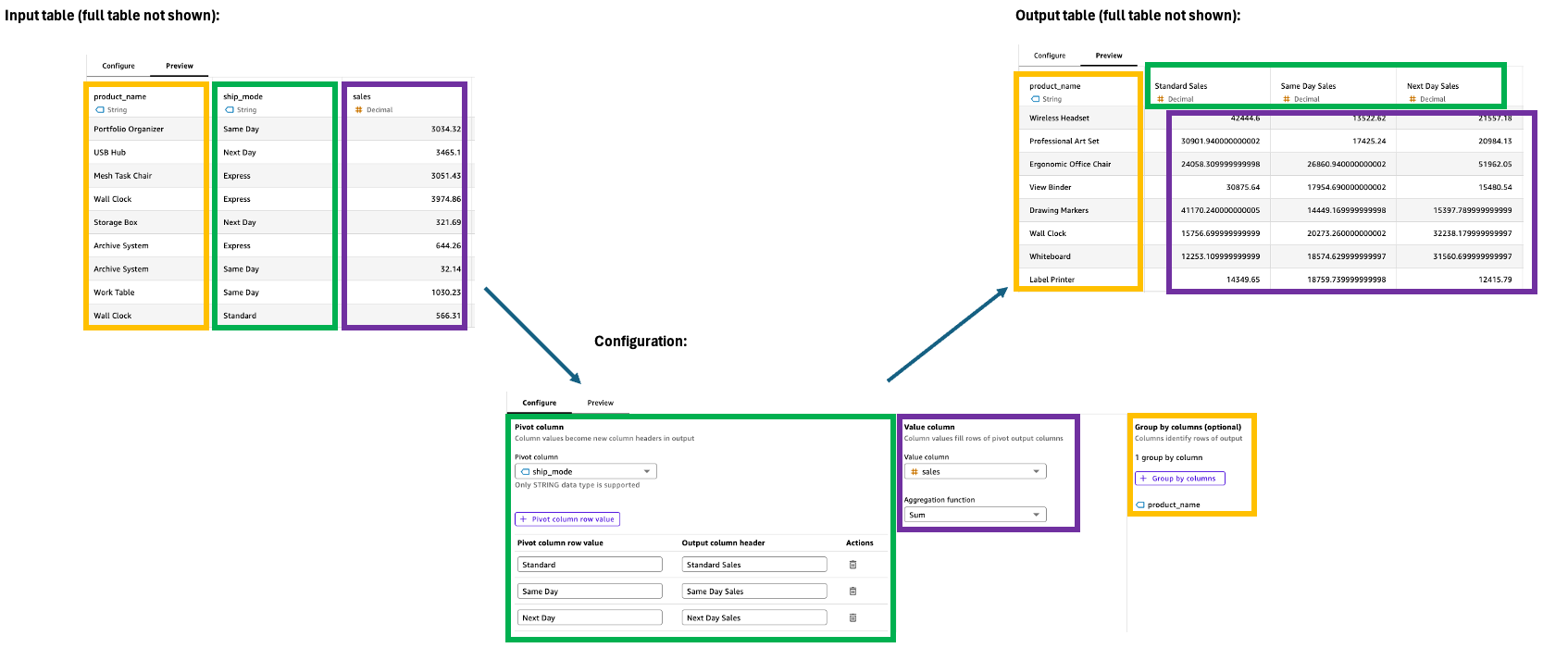
Pivot(피벗)
피벗 단계는 행 값을 고유한 열로 변환하여 데이터를 긴 형식에서 넓은 형식으로 변환하므로 비교 및 분석이 더 쉬워집니다. 이 변환에는 출력 열을 효과적으로 관리하기 위한 값 필터링, 집계 및 그룹화에 대한 사양이 필요합니다.
구성
피벗 단계를 구성하려면 구성 창에서 다음을 사용합니다.
-
피벗 열: 값이 열 헤더(예: 범주)가 될 열을 선택합니다.
-
피벗 열 행 값: 포함할 특정 값을 필터링합니다(예: 기술, 사무실 공급).
-
출력 열 헤더: 새 열 헤더를 사용자 지정합니다(기본값은 피벗 열 값).
-
값 열: 집계할 열을 선택합니다(예: 판매).
-
집계 함수: 집계 방법(예: 합계)을 선택합니다.
-
그룹화 기준: 열 구성(예: 세그먼트)을 지정합니다.
데이터 유형당 지원되는 연산자
| 데이터 형식 | 지원되는 연산자 |
|---|---|
|
정수 및 소수 |
|
|
Date |
|
|
문자열 |
|
사용 노트
-
피벗된 각 열에는 값 열의 집계된 값이 포함됩니다.
-
명확성을 위해 열 헤더를 사용자 지정합니다.
-
변환 결과를 실시간으로 미리 봅니다.
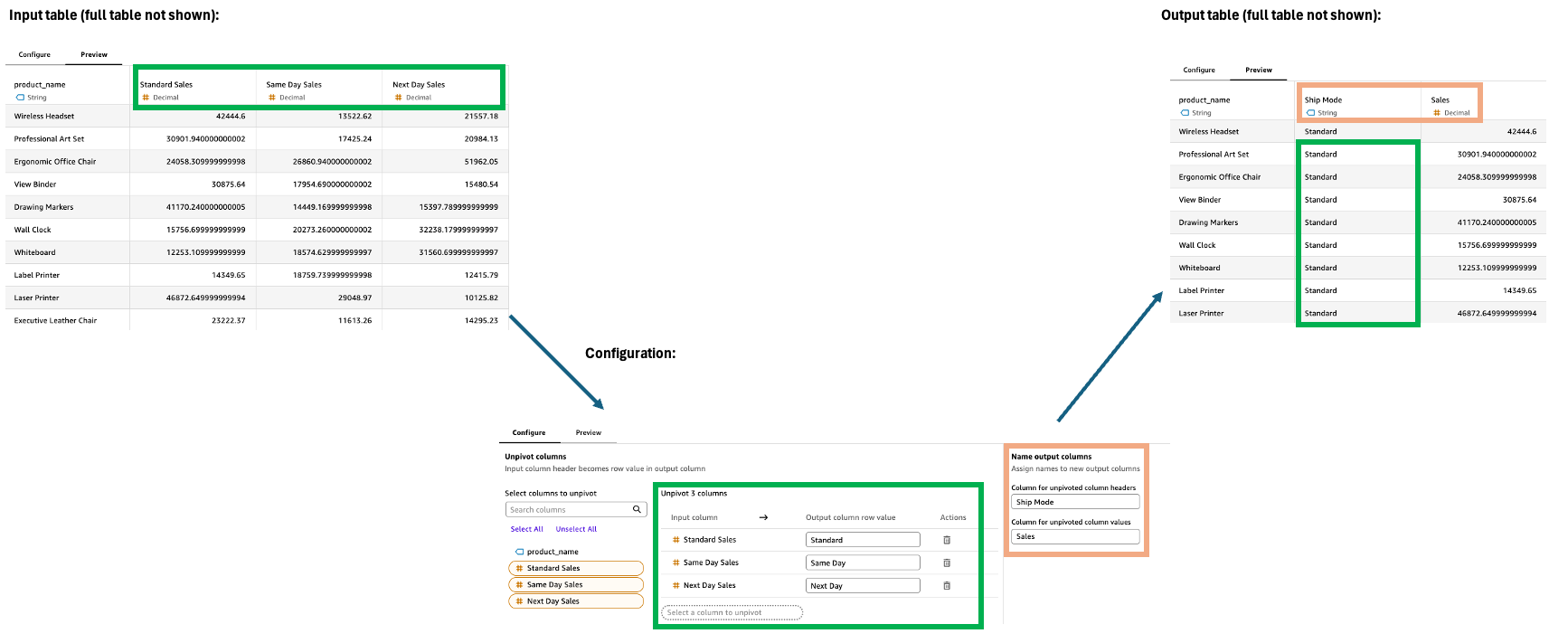
피벗 해제
피벗 해제 단계는 열을 행으로 변환하여 넓은 데이터를 더 길고 좁은 형식으로 변환합니다. 이 변환을 통해 여러 열에 분산된 데이터를 보다 구조화된 형식으로 구성하여 분석 및 시각화를 더 쉽게 수행할 수 있습니다.
구성
피벗 해제 단계를 구성하려면 구성 창에서 다음을 수행합니다.
-
행으로 피벗 해제할 열을 선택합니다.
-
출력 열 행 값을 정의합니다. 기본값은 원래 열 이름입니다. 몇 가지 예로는 기술, 사무실 공급 및 가구가 있습니다.
-
두 개의 새 출력 열의 이름을 지정합니다.
-
피벗되지 않은 열 헤더: 이전 열 이름의 이름(예: 범주)
-
피벗되지 않은 열 값: 피벗되지 않은 값의 이름(예: Sales)
-
주요 기능
-
출력에 피벗되지 않은 모든 열을 유지합니다.
-
두 개의 새 열을 자동으로 생성합니다. 하나는 이전 열 이름용이고 다른 하나는 해당 값에 대한 것입니다.
-
광범위한 데이터를 긴 형식으로 변환합니다.
사용 노트
-
피벗되지 않은 모든 열에는 호환되는 데이터 형식이 있어야 합니다.
-
행 수는 일반적으로 피벗을 해제한 후 증가합니다.
-
변경 사항을 적용하기 전에 실시간으로 미리 봅니다.
