기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
고급 워크플로 기능
Amazon Quick Sight의 데이터 준비 경험은 복잡하고 재사용 가능한 데이터 변환을 생성하는 기능을 향상시키는 정교한 기능을 제공합니다. 이 섹션에서는 워크플로 잠재력을 확장하는 두 가지 강력한 기능을 다룹니다.
발산을 사용하면 단일 단계에서 여러 변환 경로를 생성하여 나중에 다시 결합할 수 있는 병렬 처리 스트림을 허용할 수 있습니다. 이 기능은 자체 조인 및 병렬 변환과 같은 복잡한 시나리오에 특히 유용합니다.
복합 데이터 세트를 사용하면 기존 데이터 세트를 구성 요소로 사용하여 계층적 데이터 구조를 구축할 수 있습니다. 이 기능은 팀 간의 협업을 촉진하고 재사용 가능한 계층화된 변환을 통해 일관된 비즈니스 로직을 보장합니다.
이러한 기능은 함께 작동하여 유연한 워크플로 설계, 향상된 팀 협업 및 재사용 가능한 데이터 변환을 제공합니다. 또한 명확한 데이터 계보를 보장하고 확장 가능한 데이터 준비 솔루션을 지원하여 조직이 점점 더 복잡해지는 데이터 시나리오를 효율성과 명확성으로 처리할 수 있도록 지원합니다.
발산
Divergence를 사용하면 워크플로의 단일 단계에서 여러 병렬 변환 경로를 생성할 수 있습니다. 이러한 경로를 독립적으로 변환하고 나중에 다시 결합할 수 있으므로 자체 조인과 같은 복잡한 데이터 준비 시나리오가 가능합니다.
분산 경로 생성
워크플로에서 Divergence를 시작하려면 다음을 수행합니다.
-
발산을 생성할 단계를 선택합니다.
-
나타나는 + 아이콘을 선택합니다.
-
표시되는 새 브랜치를 구성합니다.
-
원하는 변환을 각 경로에 적용합니다.
-
조인 또는 추가 단계를 사용하여 경로를 단일 출력으로 다시 결합합니다.
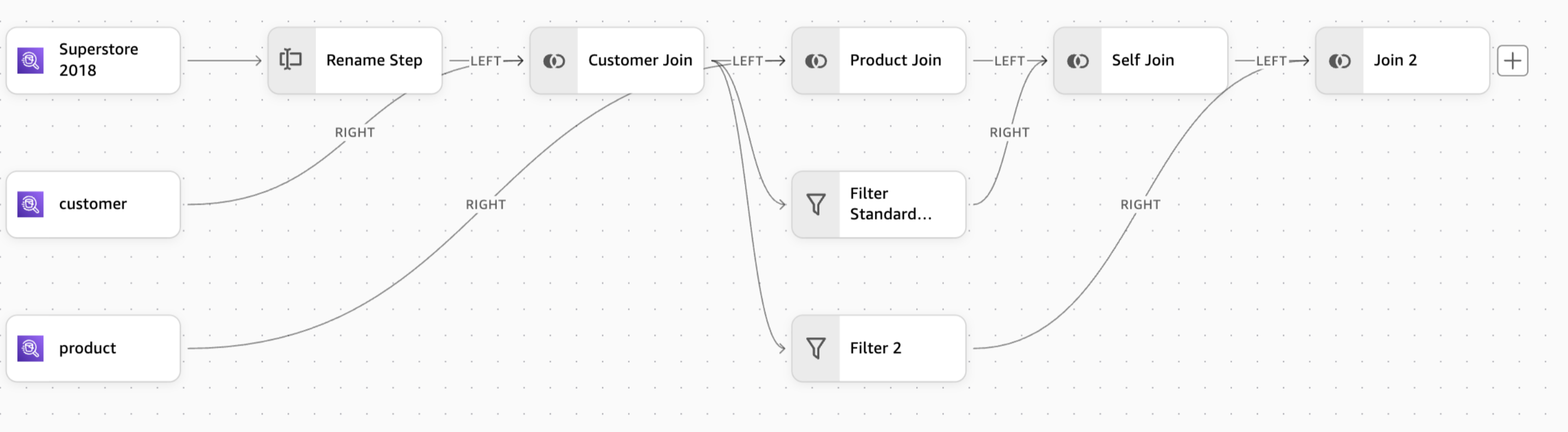
주요 기능
-
단일 단계에서 최대 5개의 분산 경로를 생성합니다.
-
각 경로에 서로 다른 변환을 적용합니다.
-
조인 또는 추가 단계를 사용하여 경로를 조합합니다.
-
각 경로의 변경 사항을 독립적으로 미리 봅니다.
모범 사례
-
자체 조인을 구현하려면 발산을 사용합니다.
-
병렬 변환을 위한 데이터 복사본을 생성합니다.
-
재결합 전략(조인 또는 추가)을 계획합니다.
-
워크플로 가시성을 높이기 위해 명확한 경로 이름 지정을 유지합니다.
복합 데이터 세트
복합 데이터 세트를 사용하면 기존 데이터 세트를 기반으로 구축하여 조직 전체에서 공유하고 재사용할 수 있는 계층적 데이터 변환 구조를 생성할 수 있습니다. Quick Sight는 SPICE 모드와 직접 쿼리 모드 모두에서 최대 10개의 복합 데이터 세트를 지원합니다.
복합 데이터 세트 생성
워크플로에서 복합 데이터 세트를 생성하려면:
-
새 데이터 세트를 생성할 때 입력 단계를 선택합니다.
-
데이터 추가에서 데이터 세트를 소스로 선택합니다.
-
빌드할 기존 데이터 세트를 선택합니다.
-
필요에 따라 추가 변환을 적용합니다.
-
를 새 데이터 세트로 저장합니다.
주요 기능
-
계층적 데이터 변환 구조를 구축합니다.
-
최대 10개 수준의 데이터 세트 중첩을 지원합니다.
-
SPICE 및 Direct Query와 호환됩니다.
-
명확한 데이터 계보를 유지합니다.
-
팀별 변환을 활성화합니다.
이 기능은 여러 팀 간의 협업을 개선합니다. 예:
| Role | 작업 | 출력 |
|---|---|---|
|
글로벌 분석가 |
글로벌 비즈니스 로직으로 데이터 세트를 생성합니다. |
데이터 세트 A |
|
미주 분석가 |
데이터 세트 A를 사용하고 리전 로직을 추가합니다. |
데이터 세트 B |
|
미국 서부 분석가 |
데이터 세트 B를 사용하고 로컬 로직을 추가합니다. |
데이터 세트 C |
이 계층적 접근 방식은 변환 계층의 명확한 소유권을 할당하여 조직 전체에서 일관된 비즈니스 로직을 촉진합니다. 최대 10개 수준의 데이터 세트 중첩을 지원하면서 추적 가능한 데이터 계보를 생성하여 제어되고 체계적인 데이터 변환 관리를 지원합니다.
모범 사례
-
각 변환 계층에 대한 명확한 소유권을 설정합니다.
-
데이터 세트 관계 및 종속성을 문서화합니다.
-
비즈니스 요구 사항에 따라 계층 구조 깊이를 계획합니다.
-
일관된 이름 지정 규칙을 유지합니다.
-
업스트림 데이터 세트를 주의 깊게 검토하고 업데이트합니다.
