기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
셔플 최적화
join() 및 groupByKey()와 같은 특정 작업에서는 Spark가 셔플을 수행해야 합니다. 셔플은 데이터를 재분산하기 위한 Spark의 메커니즘으로, 이를 통해 여러 RDD 파티션에서 다르게 데이터가 그룹화됩니다. 셔플 작업은 성능 병목 현상을 해결하는 데 도움이 될 수 있습니다. 그러나 셔플 작업에는 일반적으로 Spark 실행기 사이에서 데이터를 복사하는 작업이 포함되므로 셔플은 복잡하고 비용이 많이 드는 작업입니다. 예를 들어 셔플에서는 다음과 같은 비용이 발생합니다.
-
디스크 I/O:
-
디스크에서 많은 수의 중간 파일을 생성합니다.
-
-
네트워크 I/O:
-
많은 네트워크 연결이 필요합니다(연결 수 =
Mapper × Reducer). -
레코드는 다른 Spark 실행기에서 호스팅될 수 있는 새 RDD 파티션으로 집계되므로 데이터세트의 상당 부분이 네트워크를 통해 Spark 실행기 사이에서 이동할 수 있습니다.
-
-
CPU 및 메모리 로드:
-
값을 정렬하고 데이터세트를 병합합니다. 이러한 작업은 실행기에서 계획되어 실행기에 과도한 로드를 부과합니다.
-
셔플은 Spark 애플리케이션의 성능 저하에서 가장 중요한 요인 중 하나입니다. 중간 데이터를 저장하는 동안 실행기의 로컬 디스크에서 공간을 소진하여 Spark 작업이 실패할 수 있습니다.
CloudWatch 지표와 Spark UI에서 셔플 성능을 평가할 수 있습니다.
CloudWatch 지표
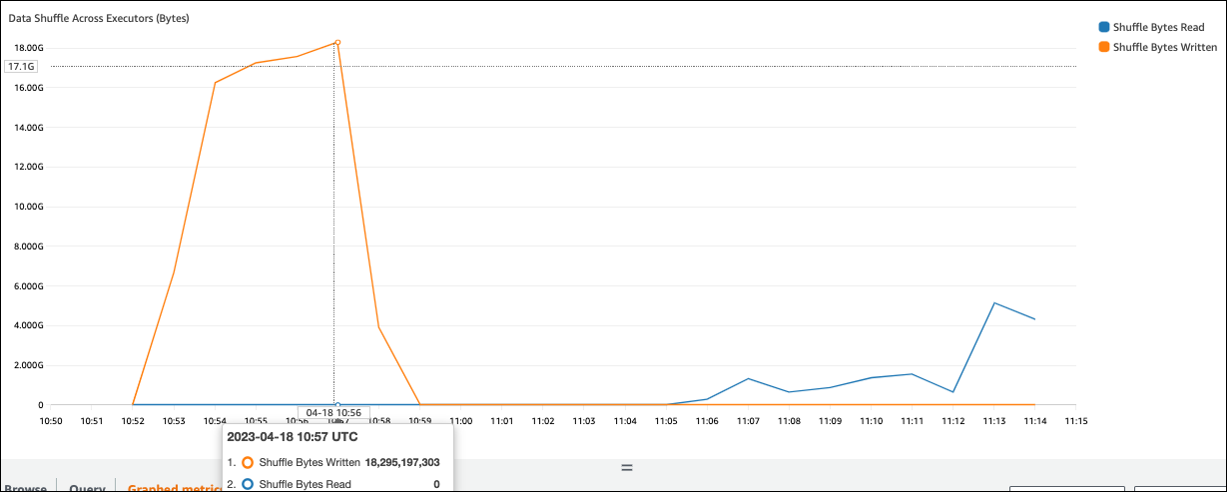
셔플 바이트 쓰기 값이 셔플 바이트 읽기와 비교하여 높은 경우 Spark 작업은 join() 또는 groupByKey()와 같은 셔플 작업
Spark UI
Spark UI의 스테이지 탭에서 셔플 읽기 크기/레코드 값을 확인할 수 있습니다. 실행기 탭에서도 볼 수 있습니다.
다음 스크린샷에서 각 실행기는 약 18.6GB/4,020,000개 레코드를 셔플 프로세스와 교환합니다(총 셔플 읽기 크기는 약 75GB).
셔플 유출(디스크) 열에는 디스크로의 많은 데이터 유출 메모리가 표시되며, 이로 인해 디스크가 가득 차거나 성능 문제가 발생할 수 있습니다.

이러한 증상이 관찰되고 성능 목표에 비해 단계가 너무 오래 걸리거나 Out Of Memory 또는 No space
left on device 오류로 인해 실패하는 경우 다음 솔루션을 고려합니다.
조인 최적화
테이블을 조인하는 join() 작업은 가장 일반적으로 사용되는 셔플 작업이지만 종종 성능 병목 현상이 되곤 합니다. 조인은 비용이 많이 드는 작업이므로 비즈니스 요구 사항에 필수적인 경우가 아니면 사용하지 않는 것이 좋습니다. 다음 질문을 통해 데이터 파이프라인을 효율적으로 사용하고 있는지 다시 확인합니다.
-
재사용할 수 있는 다른 작업에서도 수행되는 조인을 다시 계산하고 있나요?
-
출력의 소비자가 사용하지 않는 값으로 외래 키를 확인하기 위해 조인하고 있나요?
조인 작업이 비즈니스 요구 사항에 필수적임을 확인한 후라면 요구 사항을 충족하는 방식으로 조인을 최적화하기 위해 다음 옵션을 참조하세요.
조인 전에 푸시다운 사용
조인을 수행하기 전에 DataFrame에서 불필요한 행과 열을 필터링합니다. 이 경우 다음과 같은 이점이 있습니다.
-
셔플 중에 데이터 전송량 감소
-
Spark 실행기에서 처리량 감소
-
데이터 스캔량 감소
# Default df_joined = df1.join(df2, ["product_id"]) # Use Pushdown df1_select = df1.select("product_id","product_title","star_rating").filter(col("star_rating")>=4.0) df2_select = df2.select("product_id","category_id") df_joined = df1_select.join(df2_select, ["product_id"])
DataFrame 조인 사용
RDD API 또는 DynamicFrame 조인 대신 SparkSQL, DataFrame 및 Datasets와 같은 Spark 상위 수준 APIdyf.toDF()와 같은 메서드 직접 호출을 사용하여 DynamicFrame을 DataFrame으로 변환할 수 있습니다. Apache Spark의 주요 주제 섹션에서 설명한 대로 이러한 조인 작업은 내부적으로 Catalyst 옵티마이저의 쿼리 최적화를 활용합니다.
셔플 및 브로드캐스트 해시 조인 및 힌트
Spark는 셔플 조인과 브로드캐스트 해시 조인이라는 두 가지 유형의 조인을 지원합니다. 브로드캐스트 해시 조인은 셔플 작업이 필요하지 않으며 셔플 조인보다 필요한 처리가 적을 수 있습니다. 그러나 작은 테이블을 큰 테이블에 조인할 때만 적용됩니다. 단일 Spark 실행기의 메모리에 적합할 수 있는 테이블을 조인할 경우 브로드캐스트 해시 조인을 사용하는 방법을 고려합니다.
다음 다이어그램에서는 브로드캐스트 해시 조인 및 셔플 조인에 대한 상위 수준 구조와 단계를 보여줍니다.
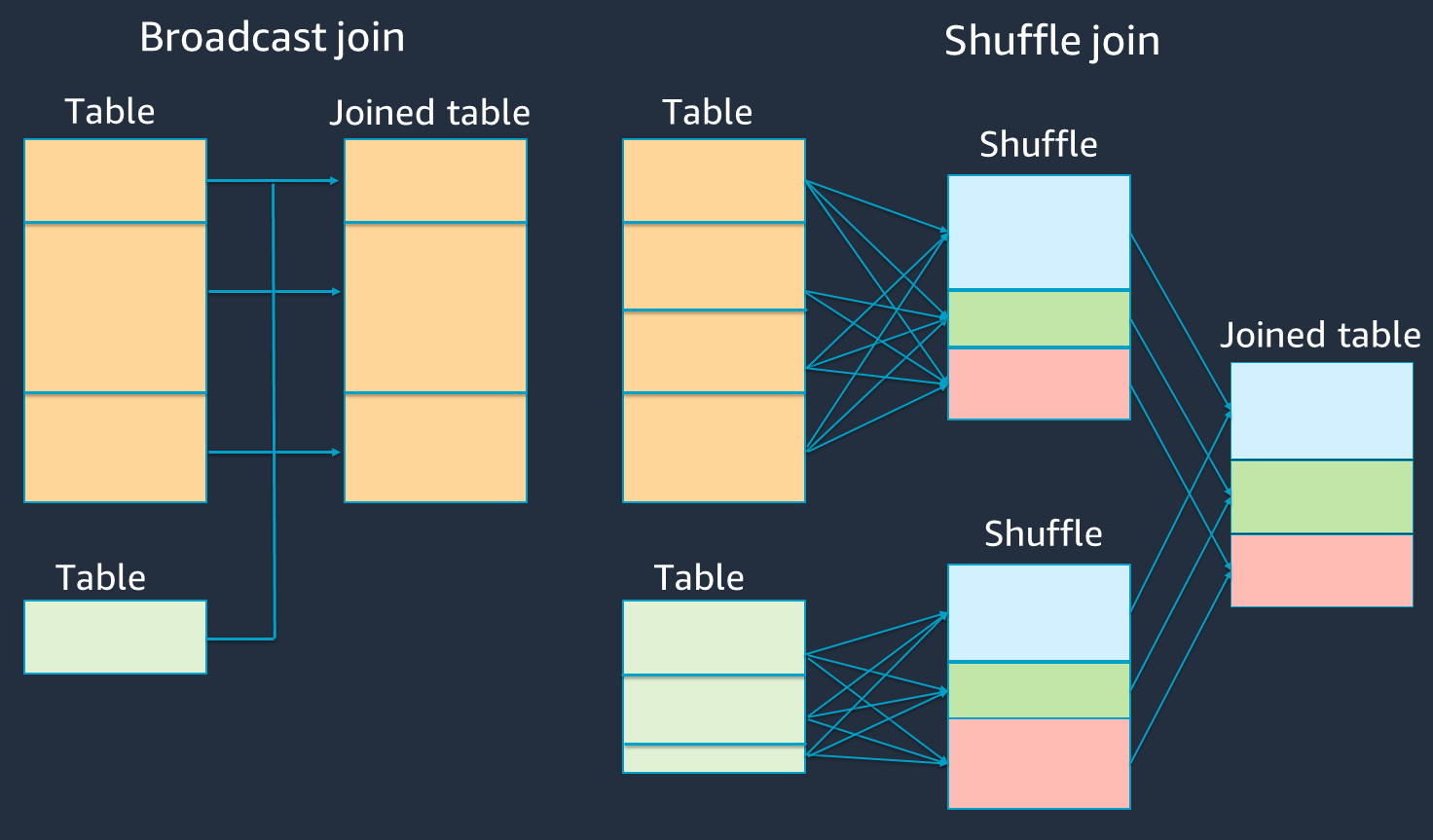
각 조인의 세부 정보는 다음과 같습니다.
-
셔플 조인:
-
셔플 해시 조인은 정렬 없이 두 테이블을 조인하고 두 테이블 간에 조인을 분산합니다. Spark 실행기의 메모리에 저장할 수 있는 작은 테이블의 조인에 적합합니다.
-
정렬 병합 조인은 조인할 두 테이블을 키별로 분산하고 조인하기 전에 정렬합니다. 큰 테이블의 조인에 적합합니다.
-
-
브로드캐스트 해시 조인:
-
브로드캐스트 해시 조인은 더 작은 RDD 또는 테이블을 각 워커 노드로 푸시합니다. 그런 다음 더 큰 RDD 또는 테이블의 각 파티션과 맵 측 결합을 수행합니다.
이 방법은 RDD 또는 테이블 중 하나가 메모리에 적합하거나 메모리에 적합하도록 만들 수 있는 조인에 적절합니다. 셔플이 필요하지 않으므로 가능하면 브로드캐스트 해시 조인을 수행하는 것이 좋습니다. 다음과 같이 조인 힌트를 사용하여 Spark에 브로드캐스트 조인을 요청할 수 있습니다.
# DataFrame from pySpark.sql.functions import broadcast df_joined= df_big.join(broadcast(df_small), right_df[key] == left_df[key], how='inner') -- SparkSQL SELECT /*+ BROADCAST(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key;조인 힌트에 대한 자세한 내용은 Join hints
를 참조하세요.
-
In AWS Glue 3.0 이상에서는 적응형 쿼리 실행
In AWS Glue 3.0에서는를 설정하여 적응형 쿼리 실행을 활성화할 수 있습니다spark.sql.adaptive.enabled=true. 적응형 쿼리 실행은 AWS Glue 4.0에서 기본적으로 활성화됩니다.
셔플 및 브로드캐스트 해시 조인과 관련된 추가 파라미터를 설정할 수 있습니다.
-
spark.sql.adaptive.localShuffleReader.enabled -
spark.sql.adaptive.autoBroadcastJoinThreshold
관련 파라미터에 대한 자세한 내용은 Converting sort-merge join to broadcast join
In AWS Glue 3.0 이상에서는 셔플에 다른 조인 힌트를 사용하여 동작을 조정할 수 있습니다.
-- Join Hints for shuffle sort merge join SELECT /*+ SHUFFLE_MERGE(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; SELECT /*+ MERGEJOIN(t2) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; SELECT /*+ MERGE(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; -- Join Hints for shuffle hash join SELECT /*+ SHUFFLE_HASH(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; -- Join Hints for shuffle-and-replicate nested loop join SELECT /*+ SHUFFLE_REPLICATE_NL(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key;
버킷팅 사용
정렬 병합 조인에는 셔플과 정렬 그리고 병합이라는 두 단계가 필요합니다. 이 두 단계로 인해 Spark 실행기에 과부하가 걸리고, 일부 실행기가 병합되고 다른 실행기가 동시에 정렬될 때 OOM 및 성능 문제가 발생할 수 있습니다. 이러한 경우 버킷팅
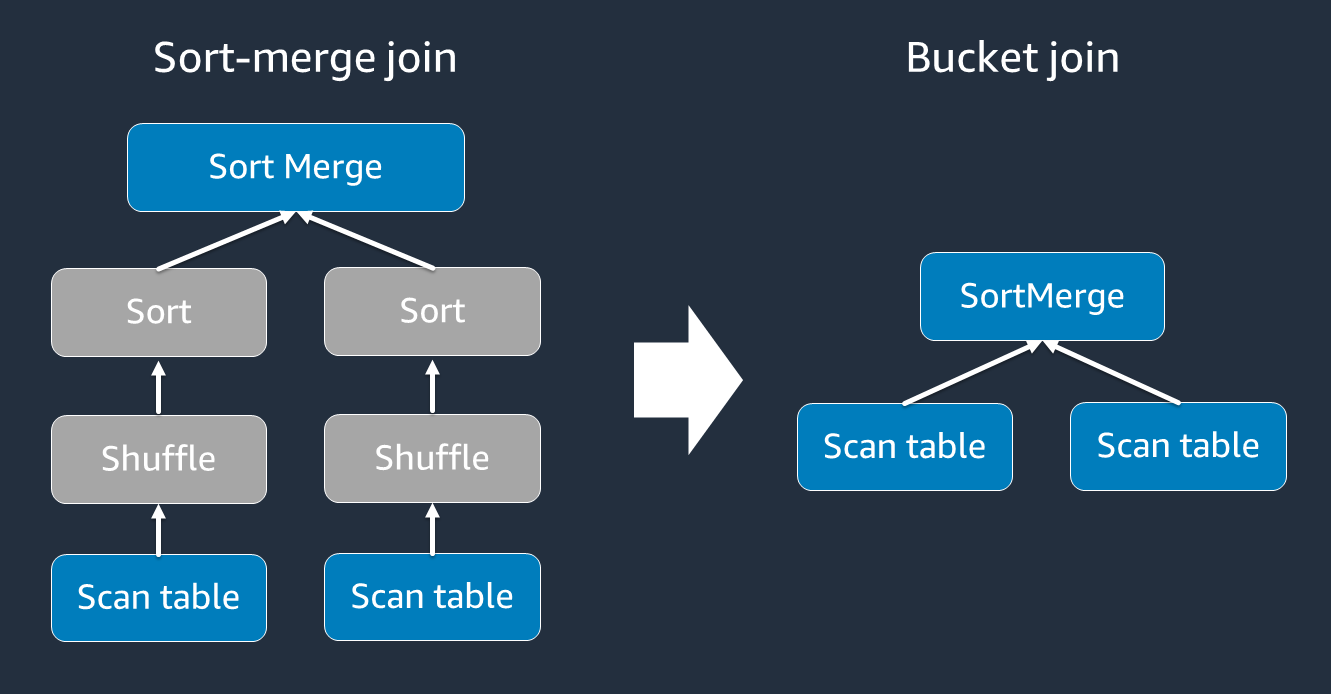
버킷 테이블은 다음과 같은 경우에 유용합니다.
-
account_id와 같은 동일한 키를 통해 자주 조인되는 데이터 -
공통 열에서 버킷팅할 수 있는 기본 및 델타 테이블과 같은 일일 누적 테이블 로드
다음 코드를 사용하여 버킷팅된 테이블을 생성할 수 있습니다.
df.write.bucketBy(50, "account_id").sortBy("age").saveAsTable("bucketed_table")
조인 전 조인 키의 DataFrames 다시 분할
조인 전에 조인 키에서 두 DataFrames를 다시 분할하려면 다음 명령문을 사용합니다.
df1_repartitioned = df1.repartition(N,"join_key") df2_repartitioned = df2.repartition(N,"join_key") df_joined = df1_repartitioned.join(df2_repartitioned,"product_id")
이렇게 하면 조인을 시작하기 전에 조인 키에서 두 개의 개별 RDD가 분할됩니다. 두 RDD가 동일한 분할 코드로 동일한 키에 분할되는 경우 조인에 대해 셔플을 수행하기 전에 함께 조인하려는 RDD 레코드가 동일한 작업자에 함께 존재할 가능성이 큽니다. 이렇게 하면 조인 중에 네트워크 활동 및 데이터 스큐를 줄여 성능이 향상될 수 있습니다.
데이터 스큐 재정의
데이터 스큐는 Spark 작업에서 가장 일반적인 병목 현상 원인 중 하나입니다. 데이터가 RDD 파티션에 균일하게 분산되지 않을 경우 나타납니다. 이 경우 해당 파티션에 대한 태스크가 다른 태스크보다 훨씬 오래 걸리므로 애플리케이션의 전체 처리 시간이 지연됩니다.
데이터 스큐를 식별하려면 Spark UI에서 다음 지표를 평가합니다.
-
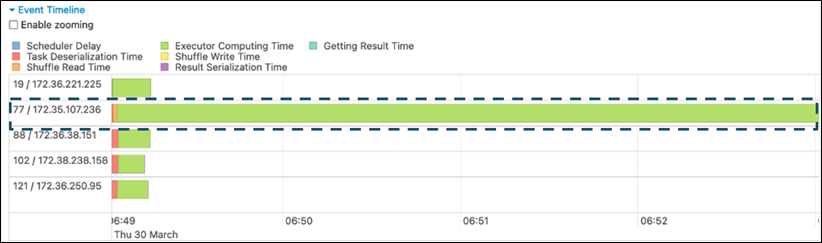
Spark UI의 단계 탭에서 이벤트 타임라인 페이지를 검토합니다. 다음 스크린샷에서는 고르지 않은 작업 분산을 볼 수 있습니다. 균등하지 않게 분산되거나 실행하는 데 너무 오래 걸리는 태스크는 데이터 스큐를 나타낼 수 있습니다.
-
또 다른 중요한 페이지는 Spark 태스크에 대한 통계를 보여주는 요약 지표입니다. 다음 스크린샷은 지속 시간, GC 시간, 유출(메모리), 유출(디스크) 등에 대한 백분위수를 포함한 지표를 보여줍니다.

태스크가 균등하게 분산되면 모든 백분위수에서 비슷한 숫자가 표시됩니다. 데이터 스큐가 있는 경우 각 백분위수에 편향된 값이 표시됩니다. 이 예제에서 태스크 지속 시간은 최소, 25번째 백분위수, 중앙값, 75번째 백분위수에서 13초 미만입니다. 최대 태스크는 75번째 백분위수보다 100배 더 많은 데이터를 처리했지만 해당 지속 시간은 6.4분으로 약 30배 더 깁니다. 즉, 하나 이상의 태스크(또는 태스크의 최대 25%)이 나머지 태스크보다 훨씬 오래 걸렸습니다.
데이터 스큐가 표시되면 다음을 시도하세요.
-
AWS Glue 3.0을 사용하는 경우를 설정하여 적응형 쿼리 실행을 활성화합니다
spark.sql.adaptive.enabled=true. 적응형 쿼리 실행은 기본적으로 AWS Glue 4.0에서 활성화됩니다.다음 관련 파라미터를 설정하여 조인이 도입한 데이터 스큐에 적응형 쿼리 실행을 사용할 수도 있습니다.
-
spark.sql.adaptive.skewJoin.skewedPartitionFactor -
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes -
spark.sql.adaptive.advisoryPartitionSizeInBytes=128m (128 mebibytes or larger should be good) -
spark.sql.adaptive.coalescePartitions.enabled=true (when you want to coalesce partitions)
자세한 내용은 Apache Spark 설명서
를 참조하세요. -
-
조인 키에 대해 큰 범위의 값이 있는 키를 사용합니다. 셔플 조인에서 키의 각 해시 값에 대해 파티션이 결정됩니다. 조인 키의 카디널리티가 너무 낮으면 해시 함수가 여러 파티션에서 데이터를 분산하는 잘못된 작업을 수행할 가능성이 더 큽니다. 따라서 애플리케이션 및 비즈니스 로직이 이를 지원하는 경우 더 높은 카디널리티 키 또는 복합 키를 사용하는 방법을 고려합니다.
# Use Single Primary Key df_joined = df1_select.join(df2_select, ["primary_key"]) # Use Composite Key df_joined = df1_select.join(df2_select, ["primary_key","secondary_key"])
캐시 사용
반복 DataFrames 사용하는 경우 df.cache() 또는 df.persist()를 사용하여 각 Spark 실행기의 메모리 및 디스크에 계산 결과를 캐싱함으로써 추가 셔플 또는 계산을 피합니다. Spark는 디스크에 RDD를 유지하거나 여러 노드(스토리지 수준
예를 들어 df.persist()를 추가하여 DataFrames를 유지할 수 있습니다. 캐시가 더 이상 필요하지 않은 경우 unpersist를 사용하여 캐싱된 데이터를 삭제할 수 있습니다.
df = spark.read.parquet("s3://<Bucket>/parquet/product_category=Books/") df_high_rate = df.filter(col("star_rating")>=4.0) df_high_rate.persist() df_joined1 = df_high_rate.join(<Table1>, ["key"]) df_joined2 = df_high_rate.join(<Table2>, ["key"]) df_joined3 = df_high_rate.join(<Table3>, ["key"]) ... df_high_rate.unpersist()
불필요한 Spark 작업 제거
count, show 또는 collect와 같은 불필요한 작업을 실행하지 마세요. Apache Spark 섹션의 주요 주제에서 설명한 대로 Spark는 지연됩니다. 변환된 각 RDD는 작업을 실행할 때마다 다시 계산될 수 있습니다. Spark 작업을 많이 사용하면 각 작업에 대해 여러 소스 액세스, 태스크 계산 및 셔플 실행이 직접 호출됩니다.
상용 환경에서 collect() 또는 기타 작업이 필요하지 않은 경우 제거하는 것을 고려합니다.
참고
상용 환경에서는 Spark collect()를 최대한 사용하지 마세요. collect() 작업은 Spark 실행기의 모든 계산 결과를 Spark 드라이버에 반환하므로 이로 인해 Spark 드라이버가 OOM 오류를 반환할 수 있습니다. OOM 오류를 방지하기 위해 Spark는 기본적으로 spark.driver.maxResultSize = 1GB를 설정합니다. 그러면 Spark 드라이버에 반환되는 최대 데이터 크기를 1GB로 제한합니다.
