기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
# 모범 사례
스토리지 및 기술 모범 사례를 따르는 것이 좋습니다. 이러한 모범 사례는 데이터 중심 아키텍처를 최대한 활용하는 데 도움이 될 수 있습니다.
## 빅 데이터에 대한 스토리지 모범 사례
다음 표에서는 Amazon S3에서 빅 데이터 처리 로드를 위해 파일을 저장하는 일반적인 모범 사례를 설명합니다. 마지막 열은 사용자가 설정할 수 있는 수명 주기 정책에 관한 예제입니다. [Amazon S3 Intelligent-Tiering](https://aws.amazon.com/s3/storage-classes/intelligent-tiering/)이 활성화된 경우(데이터 액세스 패턴이 자동으로 변경될 때 자동 스토리지 비용 절감 제공) 정책을 수동으로 설정하지 않아도 됩니다.
| | | |
| --- |--- |--- |
| **데이터 계층 이름** | **설명** | **수명 주기 정책 전략 예제** |
| 원시 | 처리되지 않은 원시 데이터 포함
**참고**: 외부 데이터 소스의 경우 원시 데이터 계층은 일반적으로 데이터의 1:1 복사본이지만 수집 프로세스 중에 AWS 리전 또는 날짜를 기준으로 키로 AWS 데이터를 분할할 수 있습니다. | 1년이 지나면 파일을 S3 Standard-IA [스토리지 클래스](https://docs.aws.amazon.com/AmazonS3/latest/userguide/storage-class-intro.html)로 이동합니다. S3 Standard-IA에서 2년이 지나면 [Amazon Simple Storage Service Glacier(Amazon S3 Glacier)](https://docs.aws.amazon.com/amazonglacier/latest/dev/introduction.html)에 파일을 아카이브합니다.
Amazon Glacier(기존 독립 실행형 볼트 기반 서비스)는 2025년 12월 15일부터 기존 고객에게 영향을 주지 않고 더 이상 신규 고객을 받지 않습니다.
Amazon Glacier는 데이터를 볼트에 저장하고 Amazon S3 및 Amazon S3 Glacier 스토리지 클래스와 구별되는 자체 API를 갖춘 독립 실행형 서비스입니다. 기존 데이터는 Amazon Glacier에서 무기한으로 안전하게 보관되며 액세스 가능합니다. 마이그레이션은 필요하지 않습니다. 저비용 장기 아카이브 스토리지의 경우는 [S3 버킷 기반 API, 전체 가용성, 저렴한 비용 및 서비스 통합을 통해 우수한 고객 경험을 제공하는 Amazon S3 Glacier 스토리지 클래스](https://aws.amazon.com/s3/storage-classes/glacier/)를 AWS 권장합니다. S3 APIs AWS 리전 AWS 향상된 기능을 원하는 경우 Amazon S3 볼트에서 Amazon [AWS S3 Glacier 스토리지 클래스로 데이터를 전송하기 위한 솔루션 지침을 사용하여 Amazon S3 Glacier 스토리지 클래스로 마이그레이션하는 것이 좋습니다.](https://aws.amazon.com/solutions/guidance/data-transfer-from-amazon-s3-glacier-vaults-to-amazon-s3/) |
| 단계 | 소비에 최적화된 중간 처리 데이터 포함
**예제**: CSV에서 Apache Parquet으로 변환된 원시 파일 또는 데이터 변환 | 정의된 기간 이후에 또는 조직의 요구 사항에 따라 데이터를 삭제할 수 있습니다.
짧은 시간(예: 90일 후) 후에 데이터 레이크에서 일부 데이터 파생물(예: 원래 JSON 형식의 Apache Avro 변환)을 제거할 수 있습니다. |
| 분석 | 특정 사용 사례에 대해 집계된 데이터를 사용 가능한 형식으로 포함
**예**: Apache Parquet | 데이터를 S3 Standard-IA로 이동한 다음 정의된 기간 이후에 또는 조직의 요구 사항에 따라 데이터를 삭제할 수 있습니다. |
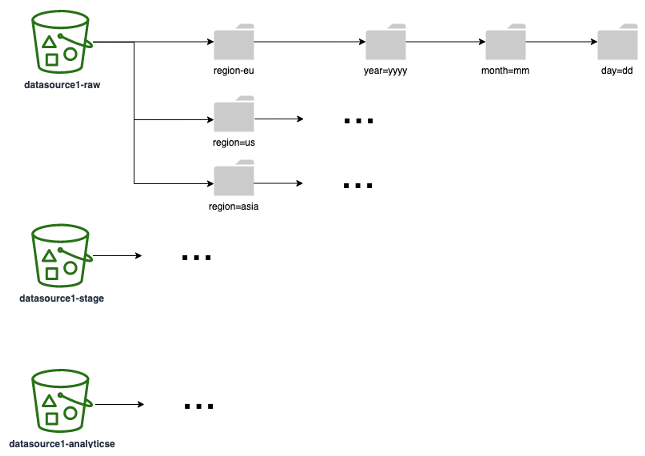
다음 다이어그램에서는 모든 데이터 계층에서 사용할 수 있는 분할 전략(하나의 S3 폴더/접두사에 해당)에 대한 예제를 보여줍니다. 다운스트림에서 데이터가 사용되는 방식에 따라 분할 전략을 선택하는 것이 좋습니다. 예를 들어 데이터를 기반으로 보고서를 작성하는 경우(보고서의 가장 일반적인 쿼리가 리전 및 날짜를 기준으로 결과를 필터링하는 경우) 쿼리 성능과 런타임을 개선하기 위해 리전과 날짜를 파티션으로 포함해야 합니다.
## 기술 모범 사례
기술 모범 사례는 데이터 중심 아키텍처를 설계하는 데 사용하는 특정 AWS 서비스 및 처리 기술에 따라 달라집니다. 그러나 다음 모범 사례를 염두에 두는 것이 좋습니다. 이러한 모범 사례는 일반적인 데이터 처리 사용 사례에 적용됩니다.
| | |
| --- |--- |
| **영역** | **모범 사례** |
| SQL | 데이터에 속성을 프로젝션하여 쿼리해야 하는 데이터의 양을 줄입니다. 전체 테이블을 구문 분석하는 대신 데이터 프로젝션을 사용하여 테이블의 특정 필수 열만 스캔하고 반환할 수 있습니다.
여러 테이블 간의 조인은 리소스 집약적인 요구로 인해 성능에 상당한 영향을 미칠 수 있으므로 가능하면 대규모 조인은 피합니다. |
| Apache Spark | AWS Glue (AWS Big Data 블로그)에서 워크로드 파티셔닝을 사용하여 [Spark 애플리케이션을 최적화](https://aws.amazon.com/blogs/big-data/optimizing-spark-applications-with-workload-partitioning-in-aws-glue/)합니다.
AWS Glue (AWS Big Data 블로그)에서 [메모리 관리를 최적화](https://aws.amazon.com/blogs/big-data/optimize-memory-management-in-aws-glue/)합니다. |
| 데이터베이스 설계 | [아키텍처 데이터베이스 모범 사례](https://aws.amazon.com/architecture/databases/?cards-all.sort-by=item.additionalFields.sortDate&cards-all.sort-order=desc&awsf.content-type=*all&awsf.methodology=*all)(AWS 아키텍처 센터)를 따릅니다. |
| 데이터 정리 | `catalogPartitionPredicate`에서 [서버 측 파티션 정리](https://docs.aws.amazon.com/glue/latest/dg/partition-indexes.html)를 사용합니다. |
| 스케일링 | [수평적 스케일링](https://wa.aws.amazon.com/wellarchitected/2020-07-02T19-33-23/wat.concept.horizontal-scaling.en.html)을 이해하고 구현합니다. |