기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
데이터베이스 분해 중 테이블 관계 분리
이 섹션에서는 모놀리식 데이터베이스 분해 중에 복잡한 테이블 관계 및 JOIN 작업을 분석하는 방법에 대한 지침을 제공합니다. 테이블 조인은 둘 이상의 테이블에 있는 행을 둘 사이의 관련 열을 기반으로 결합합니다. 이러한 관계를 분리하는 목적은 마이크로서비스 전반에서 데이터 무결성을 유지하면서 테이블 간의 높은 결합을 줄이는 것입니다.
이 섹션은 다음 주제를 포함합니다:
비정규화 전략
비정규화는 테이블 간에 데이터를 결합하거나 복제하여 의도적으로 중복성을 도입하는 데이터베이스 설계 전략입니다. 대규모 데이터베이스를 작은 데이터베이스로 분리할 때는 서비스 간에 일부 데이터를 복제하는 것이 합리적일 수 있습니다. 예를 들어 마케팅 서비스와 주문 서비스 모두에 이름 및 이메일 주소와 같은 기본 고객 세부 정보를 저장하면 지속적인 교차 서비스 조회가 필요하지 않습니다. 마케팅 서비스는 캠페인 타겟팅을 위해 고객 기본 설정과 연락처 정보가 필요할 수 있지만 주문 서비스는 주문 처리 및 알림을 위해 동일한 데이터가 필요합니다. 이로 인해 일부 데이터 중복이 생성되지만 서비스 성능과 독립성이 크게 향상되어 마케팅 팀이 실시간 고객 서비스 조회에 의존하지 않고 캠페인을 운영할 수 있습니다.
비정규화를 구현할 때는 데이터 액세스 패턴을 신중하게 분석하여 식별하는 자주 액세스하는 필드에 집중합니다. Oracle AWR 보고서 또는와 같은 도구를 사용하여 일반적으로 함께 검색되는 데이터를 pg_stat_statements파악할 수 있습니다. 도메인 전문가는 자연 데이터 그룹에 대한 귀중한 인사이트를 제공할 수도 있습니다. 비정규화는 all-or-nothing 접근 방식이 아니라 시스템 성능을 크게 개선하거나 복잡한 종속성을 줄이는 중복 데이터만 사용한다는 점을 기억하세요.
Reference-by-key 전략
reference-by-key 전략은 실제 관련 데이터를 저장하지 않고 고유한 키를 통해 엔터티 간의 관계를 유지하는 데이터베이스 설계 패턴입니다. 최신 마이크로서비스는 기존의 외래 키 관계 대신 관련 데이터의 고유 식별자만 저장하는 경우가 많습니다. 예를 들어 주문 테이블에 모든 고객 세부 정보를 보관하는 대신 주문 서비스는 고객 ID만 저장하고 필요한 경우 API 직접 호출을 통해 추가 고객 정보를 검색합니다. 이 접근 방식은 관련 데이터에 대한 액세스를 보장하면서 서비스 독립성을 유지합니다.
CQRS 패턴
명령 쿼리 책임 분리(CQRS) 패턴은 데이터 스토어의 읽기 및 쓰기 작업을 구분합니다. 이 패턴은 고성능 요구 사항, 특히 비대칭 읽기/쓰기 로드가 있는 복잡한 시스템에서 특히 유용합니다. 애플리케이션에 여러 소스의 데이터가 자주 필요한 경우 복잡한 조인 대신 전용 CQRS 모델을 생성할 수 있습니다. 예를 들어 모든 요청에 Product, Pricing및 Inventory 테이블을 조인하는 대신 필요한 데이터가 포함된 통합 Product Catalog 테이블을 유지 관리합니다. 이 접근 방식의 이점은 추가 테이블의 비용을 능가할 수 있습니다.
Product, Price및 Inventory 서비스에 제품 정보가 자주 필요한 시나리오를 생각해 보세요. 공유 테이블에 직접 액세스하도록 이러한 서비스를 구성하는 대신 전용 Product Catalog 서비스를 생성합니다. 이 서비스는 통합 제품 정보가 포함된 자체 데이터베이스를 유지합니다. 제품 관련 쿼리에 대한 단일 정보 소스 역할을 합니다. 제품 세부 정보, 가격 또는 인벤토리 수준이 변경되면 각 서비스는 이벤트를 게시하여 Product Catalog 서비스를 업데이트할 수 있습니다. 이렇게 하면 서비스 독립성을 유지하면서 데이터 일관성을 유지할 수 있습니다. 다음 이미지는 Amazon EventBridge
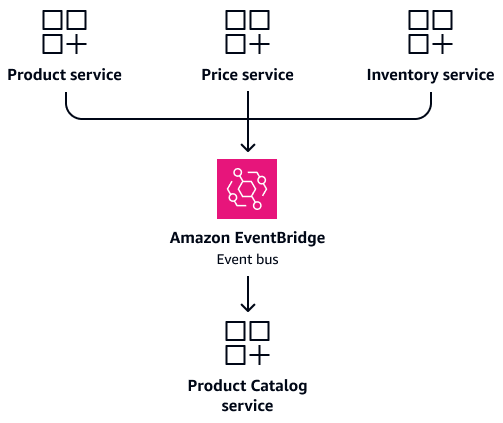
다음 섹션이벤트 기반 데이터 동기화인에서 설명한 대로 이벤트를 통해 CQRS 모델을 최신 상태로 유지합니다. 제품 세부 정보, 가격 또는 인벤토리 수준이 변경되면 각 서비스가 이벤트를 게시합니다. Product Catalog 서비스는 이러한 이벤트를 구독하고 통합 보기를 업데이트합니다. 이는 복잡한 조인 없이 빠른 읽기를 제공하며 서비스 독립성을 유지합니다.
이벤트 기반 데이터 동기화
이벤트 기반 데이터 동기화는 데이터 변경 사항이 캡처되고 이벤트로 전파되는 패턴으로, 이를 통해 다양한 시스템 또는 구성 요소가 동기화된 데이터 상태를 유지할 수 있습니다. 데이터가 변경되면 모든 관련 데이터베이스를 즉시 업데이트하는 대신 이벤트를 게시하여 구독한 서비스에 알립니다. 예를 들어 고객이 Customer 서비스의 배송 주소를 변경하면 CustomerUpdated 이벤트가 각 Order 서비스의 일정에 따라 서비스 및 Delivery 서비스에 대한 업데이트를 시작합니다. 이 접근 방식은 강체 테이블 조인을 유연하고 확장 가능한 이벤트 기반 업데이트로 대체합니다. 일부 서비스에는 오래된 데이터가 잠시 있을 수 있지만 단점은 시스템 확장성과 서비스 독립성이 향상된다는 것입니다.
테이블 조인에 대한 대안 구현
일반적으로 마이그레이션 및 검증이 더 간단하므로 읽기 작업으로 데이터베이스 분해를 시작합니다. 읽기 경로가 안정되면 더 복잡한 쓰기 작업을 처리합니다. 중요한 고성능 요구 사항의 경우 CQRS 패턴 구현을 고려하세요. 쓰기를 위해 다른 데이터베이스를 유지하면서 읽기에 최적화된 별도의 데이터베이스를 사용합니다.
교차 서비스 호출을 위한 재시도 로직을 추가하고 적절한 캐싱 계층을 구현하여 복원력이 뛰어난 시스템을 구축합니다. 서비스 상호 작용을 면밀히 모니터링하고 데이터 일관성 문제에 대한 알림을 설정합니다. 최종 목표는 모든 곳에서 완벽한 일관성이 아니라 비즈니스 요구 사항에 적합한 데이터 정확도를 유지하면서 잘 작동하는 독립적인 서비스를 만드는 것입니다.
마이크로서비스의 분리된 특성은 데이터 관리에 다음과 같은 새로운 복잡성을 도입합니다.
-
데이터가 배포됩니다. 이제 데이터는 독립 서비스에서 관리하는 별도의 데이터베이스에 상주합니다.
-
서비스 간 실시간 동기화는 종종 비실용적이므로 최종 일관성 모델이 필요합니다.
-
단일 데이터베이스 트랜잭션 내에서 이전에 발생한 작업은 이제 여러 서비스에 걸쳐 있습니다.
이러한 문제를 해결하려면 다음을 수행합니다.
-
이벤트 기반 아키텍처 구현 - 메시지 대기열 및 이벤트 게시를 사용하여 서비스 전체에 데이터 변경 사항을 전파합니다. 자세한 내용은 서버리스 랜드에서 이벤트 중심 아키텍처 구축을 참조하세요
. -
Saga 오케스트레이션 패턴 채택 -이 패턴은 분산 트랜잭션을 관리하고 서비스 전반에서 데이터 무결성을 유지하는 데 도움이 됩니다. 자세한 내용은 AWS 블로그에서 Saga 오케스트레이션 패턴을 사용하여 서버리스 분산 애플리케이션 구축을
참조하세요. -
장애에 대한 설계 - 재시도 메커니즘, 회로 차단기 및 보상 트랜잭션을 통합하여 네트워크 문제 또는 서비스 장애를 처리합니다.
-
버전 스탬핑 사용 - 데이터 버전을 추적하여 충돌을 관리하고 최신 업데이트가 적용되었는지 확인합니다.
-
정기적인 조정 - 정기적인 데이터 동기화 프로세스를 구현하여 불일치를 포착하고 수정합니다.
시나리오 기반 예제
다음 스키마 예제에는 테이블과 Customer 테이블이라는 두 개의 Order 테이블이 있습니다.
-- Customer table CREATE TABLE customer ( customer_id INT PRIMARY KEY, first_name VARCHAR(100), last_name VARCHAR(100), email VARCHAR(255), phone VARCHAR(20), address TEXT, created_at TIMESTAMP ); -- Order table CREATE TABLE order ( order_id INT PRIMARY KEY, customer_id INT, order_date TIMESTAMP, total_amount DECIMAL(10,2), status VARCHAR(50), FOREIGN KEY (customer_id) REFERENCES customers(id) );
다음은 비정규화된 접근 방식을 사용하는 방법의 예입니다.
CREATE TABLE order ( order_id INT PRIMARY KEY, customer_id INT, -- Reference only customer_first_name VARCHAR(100), -- Denormalized customer_last_name VARCHAR(100), -- Denormalized customer_email VARCHAR(255), -- Denormalized order_date TIMESTAMP, total_amount DECIMAL(10,2), status VARCHAR(50) );
새 Order 테이블에는 정규화되지 않은 고객 이름과 이메일 주소가 있습니다. customer_id가 참조되고 Customer 테이블에 외래 키 제약이 없습니다. 다음은이 비정규화된 접근 방식의 이점입니다.
-
Order서비스는 고객 세부 정보와 함께 주문 기록을 표시할 수 있으며Customer마이크로서비스에 대한 API 호출이 필요하지 않습니다. -
Customer서비스가 다운된 경우Order서비스는 완전히 작동합니다. -
주문 처리 및 보고에 대한 쿼리는 더 빠르게 실행됩니다.
다음 다이어그램은 Order 마이크로서비스에 대한 getOrder(customer_id), getOrder(order_id), getCustomerOders(customer_id)및 createOrder(Order order) API 호출을 사용하여 주문 데이터를 검색하는 모놀리식 애플리케이션을 보여줍니다.
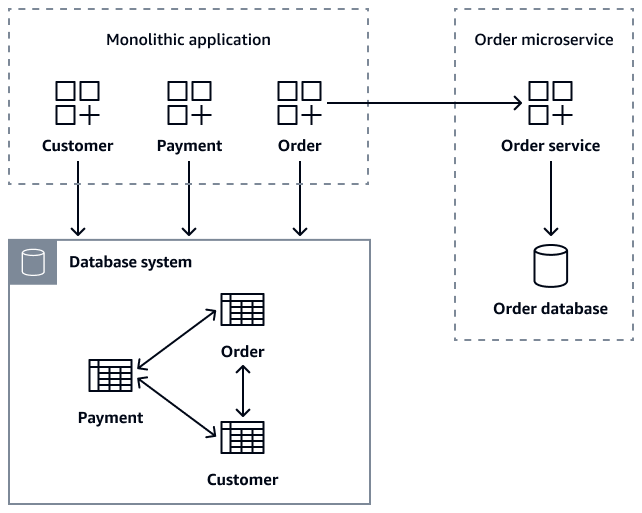
마이크로서비스 마이그레이션 중에 이전 안전 조치로 모놀리식 데이터베이스의 Order 테이블을 유지 관리하여 레거시 애플리케이션이 계속 작동하도록 할 수 있습니다. 그러나 모든 새로운 주문 관련 작업은 백업으로 레거시 데이터베이스에 쓰는 동시에 자체 데이터베이스를 유지 관리하는 Order 마이크로서비스 API를 통해 라우팅되는 것이 중요합니다. 이 이중 쓰기 패턴은 안전망을 제공합니다. 이를 통해 시스템 안정성을 유지하면서 점진적으로 마이그레이션할 수 있습니다. 모든 고객이 새 마이크로서비스로 성공적으로 마이그레이션한 후에는 모놀리식 데이터베이스에서 레거시 Order 테이블을 더 이상 사용하지 않을 수 있습니다. 모놀리식 애플리케이션과 데이터베이스를 별도의 Customer Order 마이크로서비스로 분해한 후 데이터 일관성을 유지하는 것이 주요 과제가 됩니다.
