기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
확산 및 수집 패턴
의도
확산 및 수집 패턴은 여러 수신자에게 유사하거나 관련된 요청을 브로드캐스팅하고 애그리게이터라는 구성 요소를 사용하여 응답을 단일 메시지로 다시 집계하는 메시지 라우팅 패턴입니다. 이 패턴은 병렬화를 지원하고, 처리 지연 시간을 줄이며, 비동기 통신을 처리하는 데 도움이 됩니다. 동기식 접근 방식을 사용하여 확산 및 수집 패턴을 구현하는 것은 간단하지만, 보다 강력한 접근 방식에서는 메시징 서비스를 사용하거나 사용하지 않고 비동기식 통신에서 메시지 라우팅으로 이를 구현합니다.
목적
애플리케이션 처리에서 순차적으로 처리하는 데 시간이 오래 걸릴 수 있는 요청은 병렬로 처리되는 여러 요청으로 분할될 수 있습니다. API 직접 호출을 통해 여러 외부 시스템에 요청을 보내 응답을 받을 수도 있습니다. 확산 및 수집 패턴은 여러 소스의 입력이 필요한 경우에 유용합니다. 확산 및 수집은 결과를 집계하여 정보에 입각한 의사 결정을 내리거나 요청에 가장 적합한 응답을 선택하는 데 도움이 됩니다.
확산 및 수집 패턴은 이름에 함축된 대로 두 단계로 구성됩니다.
-
확산 단계에서는 요청 메시지를 처리하고 여러 수신자에게 병렬로 보냅니다. 이 단계에서 애플리케이션은 요청을 네트워크 전체에 확산하고 즉각적인 응답을 기다리지 않고 계속 실행됩니다.
-
수집 단계에서 애플리케이션은 수신자로부터 응답을 수집하고 이를 필터링하거나 통합 응답으로 결합합니다. 모든 응답이 수집되면 단일 응답으로 집계되거나 추가 처리를 위해 가장 적합한 응답이 선택될 수 있습니다.
적용 가능성
다음과 같은 경우 확산 및 수집 패턴을 사용합니다.
-
정확한 응답을 생성하기 위해 다양한 API의 데이터를 집계하고 통합하려고 합니다. 이 패턴은 서로 다른 소스의 정보를 응집력 있는 하나의 전체로 통합합니다. 예를 들어 예약 시스템에서는 여러 외부 파트너의 견적을 얻기 위해 여러 수신자에 대한 요청을 생성할 수 있습니다.
-
트랜잭션을 완료하려면 동일한 요청을 여러 수신자에게 동시에 보내야 합니다. 예를 들어 이 패턴을 사용하여 인벤토리 데이터를 병렬로 쿼리해 제품의 가용성을 확인할 수 있습니다.
-
여러 수신자에게 요청을 분산하여 로드 밸런싱을 수행할 수 있는 신뢰할 있고 확장 가능한 시스템을 구현하려고 합니다. 한 수신자 측에서 실패하거나 높은 부하가 발생하는 경우에도 다른 수신자는 계속 요청을 처리할 수 있습니다.
-
여러 데이터 소스가 포함된 복잡한 쿼리를 구현할 때 성능을 최적화하려고 합니다. 쿼리를 관련 데이터베이스에 확산하고, 부분 결과를 수집하며, 포괄적인 답변으로 결합할 수 있습니다.
-
샤딩 및 복제를 위해 데이터 요청이 여러 데이터 처리 엔드포인트로 라우팅되는 map-reduce 처리 유형을 구현하고 있습니다. 부분 결과는 필터링되고 결합되어 올바른 응답을 구성합니다.
-
키 값 데이터베이스에서 쓰기 작업이 많은 워크로드의 파티션 키 공간에 쓰기 작업을 분산하려고 합니다. 애그리게이터는 각 샤드의 데이터를 쿼리하여 결과를 읽은 다음 단일 응답으로 통합합니다.
문제 및 고려 사항
-
내결함성:이 패턴은 병렬로 작동하는 여러 수신자에 의존하므로 실패를 정상적으로 처리하는 것이 중요합니다. 수신자 장애가 전체 시스템에 미치는 영향을 완화하기 위해 중복성, 복제 및 장애 감지와 같은 전략을 구현할 수 있습니다.
-
스케일 아웃 제한: 총 처리 노드 수가 증가하면 연결된 네트워크 오버헤드도 증가합니다. 네트워크를 통한 통신과 관련된 모든 요청은 지연 시간을 늘리고 병렬 작업의 이점을 저해할 수 있습니다.
-
응답 시간 병목 현상: 최종 처리가 완료되기 전에 모든 수신자를 처리해야 하는 작업의 경우 전체 시스템의 성능이 가장 느린 수신자의 응답 시간으로 제한됩니다.
-
부분 응답: 요청이 여러 수신자에게 확산되면 일부 수신자에서 시간이 초과될 수 있습니다. 이러한 경우 구현은 응답이 불완전함을 클라이언트에 전달해야 합니다. UI 프론트엔드를 사용하여 응답 집계 세부 정보를 표시할 수도 있습니다.
-
데이터 일관성: 여러 수신자의 데이터를 처리할 때 최종 집계 결과가 정확하고 일관되도록 데이터 동기화 및 충돌 해결 기법을 신중하게 고려해야 합니다.
구현
전반적인 아키텍처
확산 및 수집 패턴은 루트 컨트롤러를 사용하여 요청을 처리할 수신자에게 요청을 분산합니다. 확산 단계에서 이 패턴은 두 가지 메커니즘을 사용하여 수신자에게 메시지를 보낼 수 있습니다.
-
분산을 통한 확산: 애플리케이션에는 결과를 얻기 위해 직접 호출해야 하는 알려진 수신자 목록이 있습니다. 수신자는 고유한 함수가 있는 다른 프로세스이거나 처리 로드를 분산하기 위해 스케일 아웃된 단일 프로세스일 수 있습니다. 처리 노드 중 하나라도 시간이 초과되거나 응답 지연이 표시되면 컨트롤러는 처리를 다른 노드로 다시 분산할 수 있습니다.
-
경매를 통한 확산: 애플리케이션은 게시 및 구독 패턴을 사용하여 관심 있는 수신자에게 메시지를 브로드캐스팅합니다. 이 경우 수신자는 언제든지 메시지를 구독하거나 구독을 취소할 수 있습니다.
분산을 통한 확산
분산을 통한 확산 방법에서 루트 컨트롤러는 수신 요청을 독립적인 태스크로 나누고 사용 가능한 수신자에게 할당합니다(확산 단계). 각 수신자(프로세스, 컨테이너 또는 Lambda 함수)는 계산에서 독립적으로 병렬로 작동하며 응답의 일부를 생성합니다. 수신자가 태스크를 완료하면 애그리게이터에 응답을 보냅니다(수집 단계). 애그리게이터는 부분 응답을 결합하고 최종 결과를 클라이언트에 반환합니다. 다음 다이어그램에서 이 워크플로를 보여줍니다.
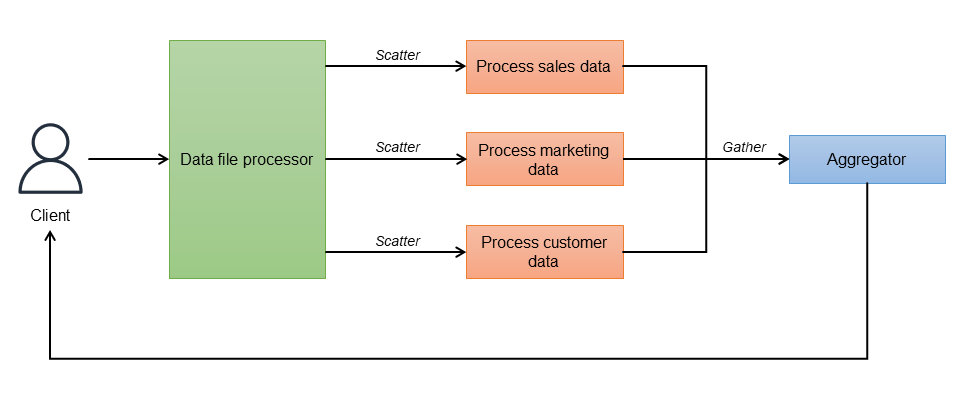
컨트롤러(데이터 파일 프로세서)는 전체 간접 호출 세트를 오케스트레이션하며 직접 호출할 모든 예약 엔드포인트를 인식합니다. 너무 오래 걸리는 응답을 무시하도록 제한 시간 파라미터를 구성할 수 있습니다. 요청이 전송되면 애그리게이터는 각 엔드포인트의 응답을 다시 기다립니다. 복원력을 구현하려면 로드 밸런싱을 위해 각 마이크로서비스를 여러 인스턴스와 함께 배포할 수 있습니다. 애그리게이터는 결과를 가져와 단일 응답 메시지로 결합하고 추가 처리 전에 중복 데이터를 제거합니다. 제한 시간이 초과된 응답은 무시됩니다. 별도의 애그리게이터 서비스를 사용하는 대신 컨트롤러가 애그리게이터 역할을 수행할 수도 있습니다.
경매를 통한 확산
컨트롤러가 수신자를 인식하지 못하거나 수신자가 느슨하게 결합된 경우 경매 방법으로 확산을 사용할 수 있습니다. 이 방법에서 수신자는 주제를 구독하고 컨트롤러는 주제에 요청을 게시합니다. 수신자는 결과를 응답 대기열에 게시합니다. 루트 컨트롤러는 수신자를 인식하지 못하므로 수집 프로세스는 애그리게이터(다른 메시징 패턴)를 사용하여 응답을 수집하고 단일 응답 메시지로 추출합니다. 애그리게이터는 고유 ID를 사용하여 요청 그룹을 식별합니다.
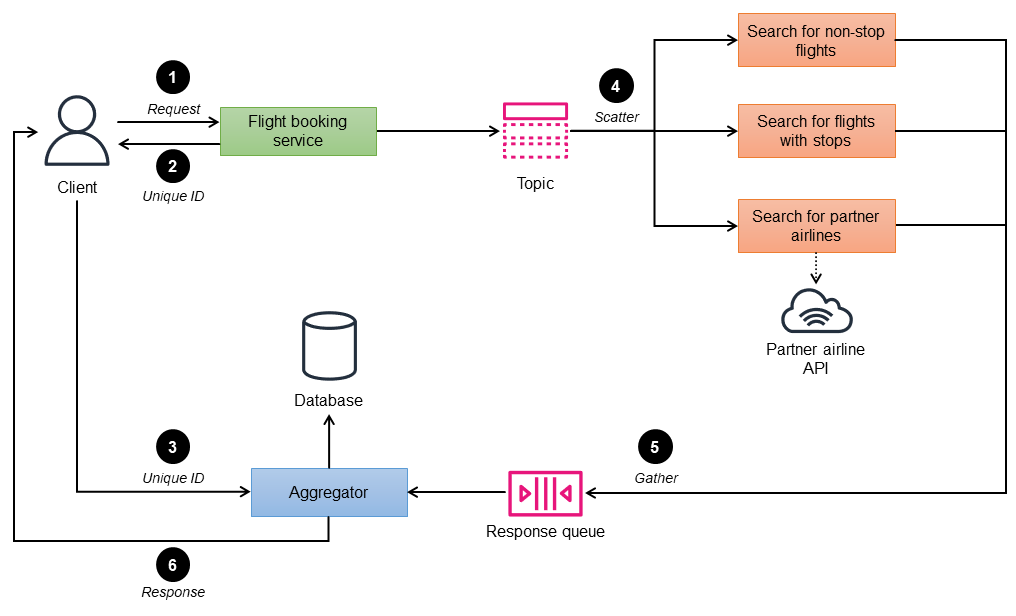
예를 들어 다음 다이어그램에서는 항공사 웹 사이트에서 항공편 예약 서비스를 구현하는 데 경매를 통한 확산 방법이 사용됩니다. 사용자는 이 웹 사이트를 자체 항공사 및 파트너 항공사에서 항공편을 검색하고 표시할 수 있으며, 웹 사이트에서는 검색 상태를 실시간으로 표시해야 합니다. 항공편 예약 서비스는 직항편, 경유지가 있는 항공편, 파트너 항공사와 같은 세 가지 검색 마이크로서비스로 구성됩니다. 파트너 항공사 검색은 파트너의 API 엔드포인트를 직접 호출하여 응답을 가져옵니다.
-
항공편 예약 서비스(컨트롤러)는 클라이언트의 입력으로 검색 기준을 사용하고 요청을 처리하며 주제에 게시합니다.
-
컨트롤러는 고유 ID를 사용하여 각 요청 그룹을 식별합니다.
-
클라이언트는 6단계에서 애그리게이터에 고유 ID를 전송합니다.
-
예약 주제를 구독하는 예약 검색 마이크로서비스가 요청을 수신합니다.
-
마이크로서비스는 요청을 처리하고 지정된 검색 기준에 대한 좌석 가용성을 응답 대기열로 반환합니다.
-
애그리게이터는 임시 데이터베이스에 저장된 모든 응답 메시지를 수집하고, 항공편을 고유 ID별로 그룹화하며, 단일 통합 응답을 생성하고, 클라이언트로 다시 보냅니다.
를 사용한 구현 AWS 서비스
분산을 통한 확산
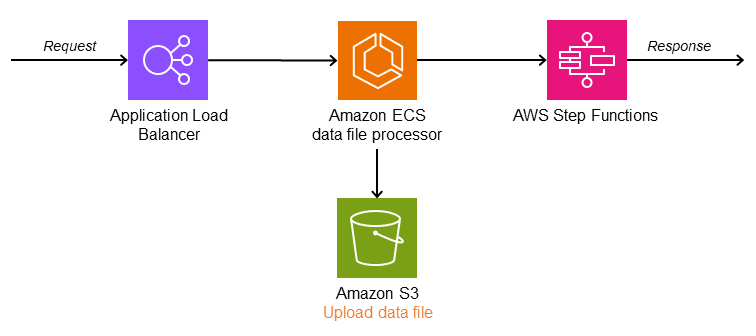
다음 아키텍처에서 루트 컨트롤러는 수신 요청 데이터를 개별 Amazon Simple Storage Service(SAmazon S3 ECS)입니다. AWS Step Functions 워크플로는 데이터를 다운로드하고 병렬 파일 처리를 시작합니다. Parallel 상태는 모든 작업이 응답을 반환할 때까지 기다립니다. AWS Lambda 함수는 데이터를 집계하여 Amazon S3에 다시 저장합니다.
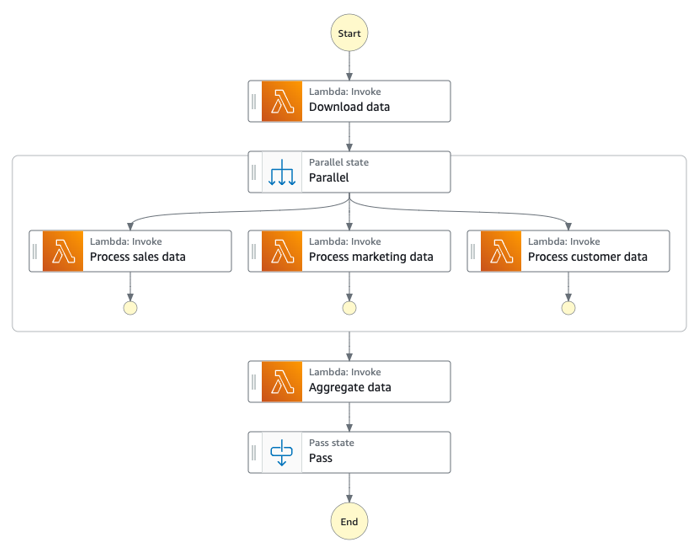
다음 다이어그램에서는 Parallel 상태의 Step Functions 워크플로를 보여줍니다.
경매를 통한 확산
다음 다이어그램은 경매 방법별 산점도의 AWS 아키텍처를 보여줍니다. 루트 컨트롤러 항공편 예약 서비스는 항공편 검색 요청을 여러 마이크로서비스로 확산합니다. 게시 및 구독 채널은 통신을 위한 관리형 메시징 서비스인 Amazon Simple Notification Service(Amazon SNS)로 구현됩니다. Amazon SNS는 분리된 마이크로서비스 애플리케이션 사이에서 메시지 또는 사용자와의 직접 통신을 지원합니다. 관리 및 확장성 향상을 위해 Amazon Elastic Kubernetes Service(Amazon EKS) 또는 Amazon Elastic Container Service(Amazon ECS)에서 수신자 마이크로서비스를 배포할 수 있습니다. 항공편 결과 서비스는 결과를 클라이언트에 반환합니다. 또는 Amazon ECS 또는 Amazon EKS와 같은 AWS Lambda 다른 컨테이너 오케스트레이션 서비스에서 구현할 수 있습니다.
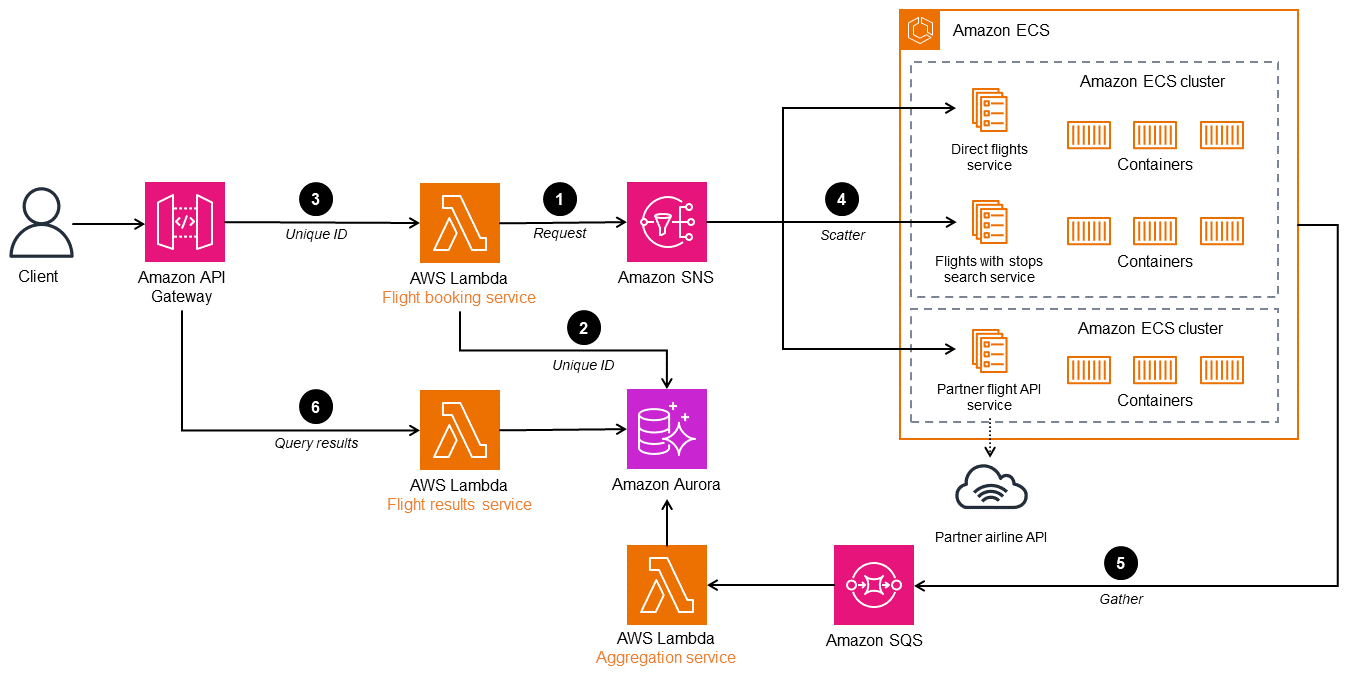
-
항공편 예약 서비스(컨트롤러)는 클라이언트의 입력으로 검색 기준을 사용하고 요청을 처리하며 SNS 주제에 게시합니다.
-
컨트롤러는 Amazon Aurora 데이터베이스에 고유 ID를 게시하여 요청을 식별합니다.
-
클라이언트는 6단계에서 클라이언트에 고유 ID를 전송합니다.
-
예약 주제를 구독하는 예약 검색 마이크로서비스가 요청을 수신합니다.
-
마이크로서비스는 요청을 처리하고 지정된 검색 기준에 대한 좌석 가용성을 Amazon Simple Queue Service(Amazon SQS)의 응답 대기열로 반환합니다. 애그리게이터는 모든 응답 메시지를 수집하고 임시 데이터베이스에 저장합니다.
-
항공편 결과 서비스는 항공편을 고유 ID로 그룹화하고 단일 통합 응답을 생성한 후 클라이언트로 다시 보냅니다.
이 아키텍처에 다른 항공사 검색을 추가하려면 SNS 주제를 구독하고 SQS 대기열에 게시하는 마이크로서비스를 추가합니다.
요약하면, 확산 및 수집 패턴을 사용할 경우 분산 시스템에서 효율적인 병렬화를 달성하고 지연 시간을 줄이며 비동기 통신을 원활하게 처리할 수 있습니다.
GitHub 리포지토리
이 패턴에 대한 샘플 아키텍처의 전체 구현은 https://github.com/aws-samples/asynchronous-messaging-workshop/tree/master/code/lab-3
워크숍
-
Decoupled Microservices 워크숍의 Scatter-gather lab
블로그 참조
관련 콘텐츠
-
게시 및 구독 패턴
