기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
AWS Glue를 사용하여 데이터 내보내기
빅 데이터 시나리오를 위한 서버리스 분석 서비스인 AWS Glue를 사용하여 MySQL 데이터를 Amazon S3에 아카이브할 수 있습니다. AWS Glue는 많은 데이터베이스 소스를 지원하는 널리 사용되는 분산 클러스터 컴퓨팅 프레임워크인 Apache Spark로 구동됩니다.
데이터베이스에서 Amazon S3로 아카이브된 데이터의 오프로드는 AWS Glue 작업에서 몇 줄의 코드로 수행할 수 있습니다. AWS Glue가 제공하는 가장 큰 이점은 수평 확장성과 종량제 모델로 운영 효율성과 비용 최적화를 제공한다는 점입니다.
다음 다이어그램에서는 데이터베이스 아카이빙을 위한 기본 아키텍처를 보여줍니다.
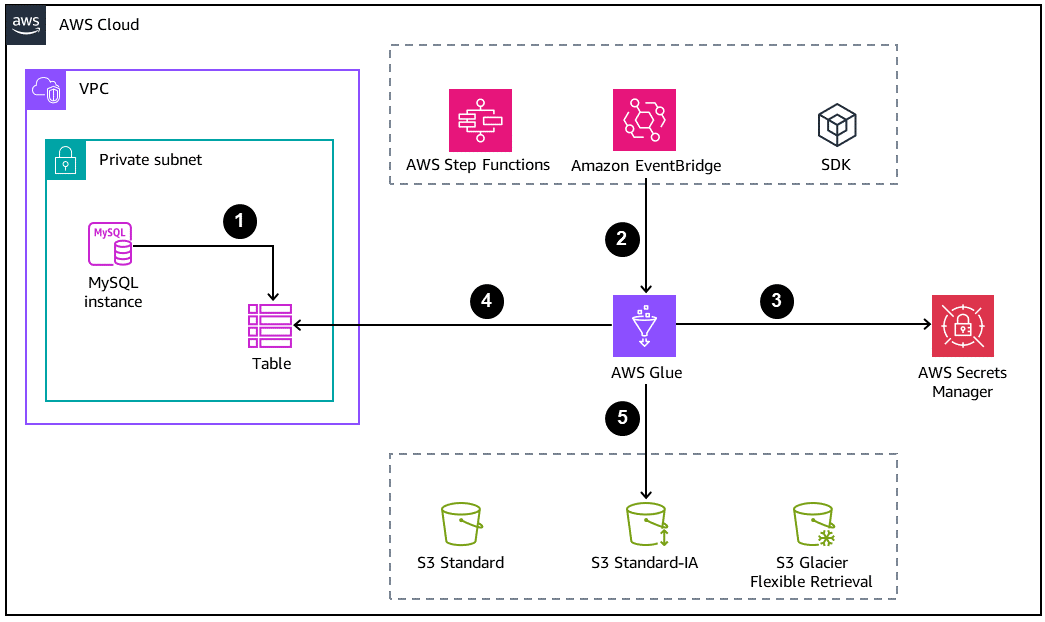
-
MySQL 데이터베이스는 Amazon S3에서 오프로드할 아카이브 또는 백업 테이블을 생성합니다.
-
AWS Glue 작업은 다음 방법 중 하나에 의해 시작됩니다.
-
AWS Step Functions 상태 시스템 내부 단계로 동기식
-
Amazon EventBridge 이벤트에 의해 비동기식
-
AWS CLI 또는 AWS SDK를 사용하여 수동 요청을 통해
-
-
DB 자격 증명은 AWS Secrets Manager에서 검색됩니다.
-
AWS Glue 작업은 Java Database Connectivity(JDBC) 연결을 사용하여 데이터베이스에 액세스하고 테이블을 읽습니다.
-
AWS Glue는 공간을 절약하는 개방형 열 기반 데이터 형식인 Parquet 형식으로 Amazon S3에 데이터를 씁니다.
AWS Glue 작업 구성
의도한 대로 작동하려면 AWS Glue 작업에 다음 구성 요소 및 구성이 필요합니다.
-
AWS Glue 연결 - 데이터베이스에 액세스하기 위해 작업에 연결하는 AWS Glue Data Catalog 객체입니다. 작업은 여러 데이터베이스에 대한 직접 호출을 위해 여러 연결을 보유할 수 있습니다. 연결에는 안전하게 저장된 데이터베이스 자격 증명이 포함됩니다.
-
GlueContext - SparkContext
의 사용자 지정 래퍼입니다. GlueContext 클래스는 Amazon S3 및 데이터베이스 소스와 상호 작용하기 위해 고차 API 작업을 제공합니다. 이를 통해 Data Catalog와 통합할 수 있습니다. 그러면 Glue 연결 내에서 처리되는 데이터베이스 연결을 위해 드라이버에 의존하지 않아도 됩니다. 또한 GlueContext 클래스는 원래 SparkContext 클래스에서는 불가능한 Amazon S3 API 작업을 처리하는 방법도 제공합니다. -
IAM 정책 및 역할 - AWS Glue는 다른 AWS 서비스와 상호 작용하므로 필요한 최소 권한으로 적절한 역할을 설정해야 합니다. AWS Glue와 상호 작용하기 위해 적절한 권한이 필요한 서비스는 다음과 같습니다.
-
Amazon S3
-
AWS Secrets Manager
-
AWS Key Management Service (AWS KMS)
-
모범 사례
-
오프로드할 행 수가 많은 전체 테이블을 읽으려는 경우 기본 라이터 인스턴스의 성능을 저하시키지 않고 읽기 복제본 엔드포인트를 사용하여 읽기 처리량을 늘리는 것이 좋습니다.
-
작업 처리에 사용되는 노드 수에서 효율성을 달성하려면 AWS Glue 3.0에서 오토 스케일링을 켭니다.
-
S3 버킷이 데이터 레이크 아키텍처의 일부인 경우 데이터를 물리적 파티션으로 구성하여 오프로드하는 것이 좋습니다. 파티션 스키마는 액세스 패턴을 기반으로 해야 합니다. 날짜 값에 기반한 분할이 가장 권장되는 사례 중 하나입니다.
-
데이터를 Parquet 또는 Optimized Row Columnar(ORC)와 같은 개방형 형식으로 저장하면 Amazon Athena 및 Amazon Redshift와 같은 다른 분석 서비스에서 데이터를 사용할 수 있습니다.
-
다른 분산 서비스에서 오프로드된 데이터 읽기를 최적화하려면 출력 파일 수를 제어해야 합니다. 많은 수의 작은 파일보다 적은 수의 더 큰 파일을 갖는 것이 대부분 항상 유용합니다. Spark에는 파트 파일 생성을 제어하는 기본 제공 구성 파일 및 메서드가 있습니다.
-
정의에 따라 아카이브된 데이터는 자주 액세스하는 데이터세트입니다. 스토리지의 비용 효율성을 달성하려면 Amazon S3 클래스를 보다 저렴한 계층으로 이전해야 합니다. 두 가지 접근 방식을 사용하여 수행할 수 있습니다.
-
오프로드 중 계층의 동기식 이전 - 오프로드된 데이터를 프로세스 중에 이전해야 한다는 점을 미리 알고 있는 경우 Amazon S3에 데이터를 쓰는 동일한 AWS Glue 작업 내에서 GlueContext 메커니즘 transition_s3_path를 사용할 수 있습니다.
-
S3 수명 주기를 사용하여 비동기식 이전 - Amazon S3 스토리지 클래스 이전 및 만료에 적합한 파라미터를 사용하여 S3 수명 주기 규칙을 설정합니다. 버킷에서 이를 구성하면 영구적으로 유지됩니다.
-
-
데이터베이스가 배포되는 가상 프라이빗 클라우드(VPC) 내에서 충분한 IP 주소 범위
의 서브넷을 생성하고 구성합니다. 그러면 많은 데이터 처리 장치(DPU)가 구성될 때 네트워크 주소 수가 부족하여 AWS Glue 작업이 실패하는 것을 방지할 수 있습니다.
