기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
의 Apache Iceberg용 참조 아키텍처 AWS
이 섹션에서는 배치 수집 및 배치와 스트리밍 데이터 수집을 결합하는 데이터 레이크와 같은 다양한 사용 사례에 모범 사례를 적용하는 방법의 예를 제공합니다.
야간 배치 수집
이 가상 사용 사례의 경우 Iceberg 테이블이 매일 밤 신용 카드 거래를 수집한다고 가정해 보겠습니다. 각 배치에는 증분 업데이트만 포함되며, 대상 테이블에 병합해야 합니다. 매년 여러 번 전체 기록 데이터가 수신됩니다. 이 시나리오에서는 다음 아키텍처 및 구성을 사용하는 것이 좋습니다.
참고: 이것은 예시일 뿐입니다. 최적의 구성은 데이터 및 요구 사항에 따라 달라집니다.
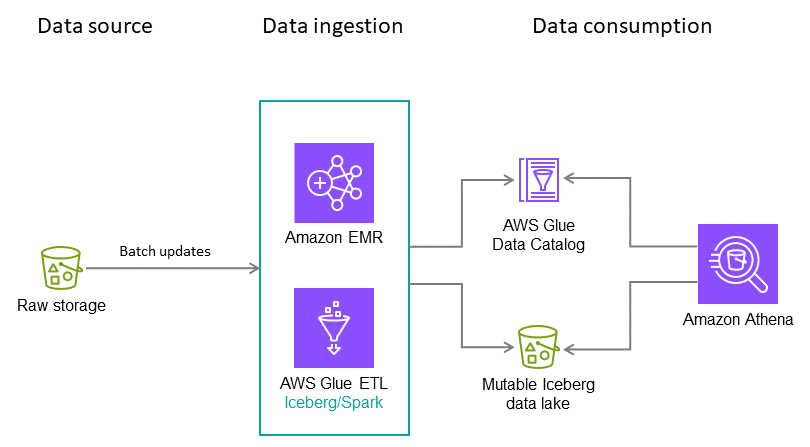
권장 사항:
-
Apache Spark 태스크는 128MB 청크로 데이터를 처리하기 때문에 파일 크기: 128MB.
-
쓰기 유형: copy-on-write. 이 가이드의 앞부분에서 자세히 설명한 대로이 접근 방식은 데이터가 읽기 최적화 방식으로 작성되도록 하는 데 도움이 됩니다.
-
파티션 변수: year/month/day. 가상 사용 사례에서는 최근 데이터를 가장 자주 쿼리하지만, 지난 2년간의 데이터에 대해 전체 테이블 스캔을 실행하는 경우가 있습니다. 파티셔닝의 목표는 사용 사례의 요구 사항에 따라 빠른 읽기 작업을 추진하는 것입니다.
-
정렬 순서: 타임스탬프
-
데이터 카탈로그: AWS Glue Data Catalog
배치 수집과 실시간에 가까운 수집을 결합한 데이터 레이크
계정 및 리전 간에 배치 및 스트리밍 데이터를 공유하는 Amazon S3의 데이터 레이크를 프로비저닝할 수 있습니다. 아키텍처 다이어그램 및 세부 정보는 AWS 블로그 게시물 Build a transactional data lake using Apache Iceberg AWS Glue, and AWS Lake Formation Amazon Athena를 사용한 교차 계정 데이터 공유
