기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon Athena SQL에서 Iceberg 테이블 시작하기
Amazon Athena는 Iceberg에 대한 기본 지원을 제공합니다. Athena 설명서의 시작하기 섹션에 설명된 서비스 사전 조건을 설정하는 경우를 제외하고 추가 단계 또는 구성 없이 Iceberg를 사용할 수 있습니다. 이 섹션에서는 Athena에서 테이블을 생성하는 방법을 간략하게 소개합니다. 자세한 내용은이 안내서 뒷부분의 Athena SQL을 사용하여 Iceberg 테이블 작업을 참조하세요.
다른 엔진을 사용하여에서 Iceberg 테이블 AWS 을 생성할 수 있습니다. 이러한 테이블은 원활하게 작동합니다 AWS 서비스. Athena SQL을 사용하여 첫 번째 Iceberg 테이블을 생성하려면 다음 표준 문안 코드를 사용할 수 있습니다.
CREATE TABLE <table_name> ( col_1 string, col_2 string, col_3 bigint, col_ts timestamp) PARTITIONED BY (col_1, <<<partition_transform>>>(col_ts)) LOCATION 's3://<bucket>/<folder>/<table_name>/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
다음 섹션에서는 Athena에서 파티셔닝된 Iceberg 테이블과 파티셔닝되지 않은 Iceberg 테이블을 생성하는 예를 제공합니다. 자세한 내용은 Athena 설명서에 자세히 설명된 Iceberg 구문을 참조하세요.
파티셔닝되지 않은 테이블 생성
다음 예제 문은 Athena에서 분할되지 않은 Iceberg 테이블을 생성하도록 표준 문 SQL 코드를 사용자 지정합니다. Athena 콘솔
CREATE TABLE athena_iceberg_table ( color string, date string, name string, price bigint, product string, ts timestamp) LOCATION 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/athena_iceberg_table/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
쿼리 편집기 사용에 대한 step-by-step 지침은 Athena 설명서의 시작하기를 참조하세요.
파티셔닝된 테이블 생성
다음 문은 Iceberg의 숨겨진 파티셔닝 개념을 사용하여 날짜를 기반으로 파티day() 변환을 사용하여 타임스탬프 열에서 dd-mm-yyyy 형식을 사용하여 일일 파티션을 추출합니다. Iceberg는이 값을 데이터 세트의 새 열로 저장하지 않습니다. 대신 데이터를 작성하거나 쿼리할 때 값이 즉시 파생됩니다.
CREATE TABLE athena_iceberg_table_partitioned ( color string, date string, name string, price bigint, product string, ts timestamp) PARTITIONED BY (day(ts)) LOCATION 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/athena_iceberg_table/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
단일 CTAS 문을 사용하여 테이블 생성 및 데이터 로드
이전 섹션의 분할된 예제와 분할되지 않은 예제에서 Iceberg 테이블은 빈 테이블로 생성됩니다. INSERT 또는 MERGE 문을 사용하여 테이블에 데이터를 로드할 수 있습니다. 또는 CREATE TABLE AS SELECT (CTAS) 문을 사용하여 한 번에 Iceberg 테이블로 데이터를 생성하고 로드할 수 있습니다.
CTAS는 Athena에서 테이블을 생성하고 단일 문에 데이터를 로드하는 가장 좋은 방법입니다. 다음 예제에서는 CTAS를 사용하여 Athena의 기존 Hive/Parquet 테이블(iceberg_ctas_table)에서 Iceberg 테이블(hive_table)을 생성하는 방법을 보여줍니다.
CREATE TABLE iceberg_ctas_table WITH ( table_type = 'ICEBERG', is_external = false, location = 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/iceberg_ctas_table/' ) AS SELECT * FROM "iceberg_db"."hive_table" limit 20 --- SELECT * FROM "iceberg_db"."iceberg_ctas_table" limit 20
CTAS에 대한 자세한 내용은 Athena CTAS 설명서를 참조하세요.
데이터 삽입, 업데이트 및 삭제
Athena는 INSERT INTO, UPDATE, MERGE INTO및 DELETE FROM 문을 사용하여 Iceberg 테이블에 데이터를 쓰는 다양한 방법을 지원합니다.
참고
Athena SQL은 현재 copy-on-write 접근 방식을 지원하지 않습니다. UPDATE, MERGE INTO및 DELETE FROM 작업은 지정된 테이블 속성에 관계없이 위치 삭제와 함께 merge-on-read 접근 방식을 항상 사용합니다. copy-on-writewrite.delete.mode를 사용하도록 write.merge.mode, 및 write.update.mode와 같은 테이블 속성을 설정하면 쿼리가 실패하지 않지만 Athena는 쿼리를 무시하고 merge-on-read을 계속 사용합니다.
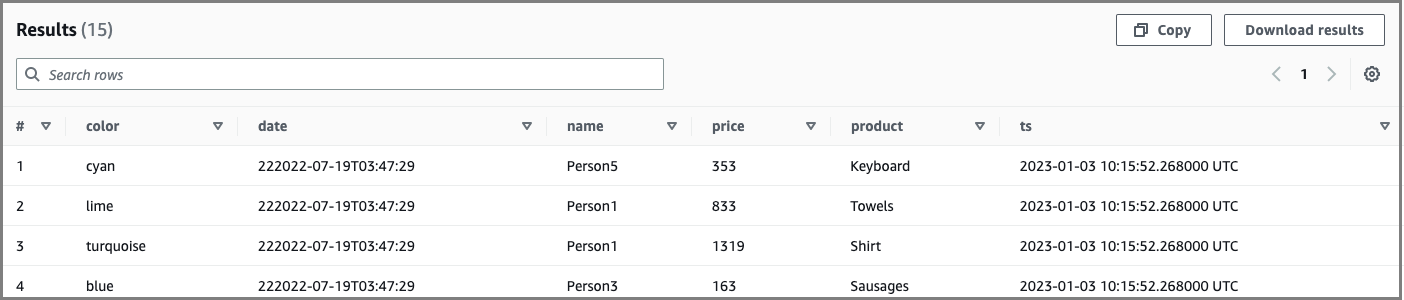
다음 문은 INSERT INTO를 사용하여 Iceberg 테이블에 데이터를 추가합니다.
INSERT INTO "iceberg_db"."ice_table" VALUES ( 'red', '222022-07-19T03:47:29', 'PersonNew', 178, 'Tuna', now() ) SELECT * FROM "iceberg_db"."ice_table" where color = 'red' limit 10;
샘플 출력:

자세한 내용은 Athena 설명서를 참조하세요.
Iceberg 테이블 쿼리
이전 예제와 같이 Athena SQL을 사용하여 Iceberg 테이블에 대해 일반 SQL 쿼리를 실행할 수 있습니다.
Athena는 일반적인 쿼리 외에도 Iceberg 테이블에 대한 시간 이동 쿼리도 지원합니다. 앞서 설명한 것처럼 Iceberg 테이블의 업데이트 또는 삭제를 통해 기존 레코드를 변경할 수 있으므로 시간 이동 쿼리를 사용하여 타임스탬프 또는 스냅샷 ID를 기반으로 테이블의 이전 버전을 다시 살펴보는 것이 편리합니다.
예를 들어 다음 문은의 색상 값을 업데이트한 다음 Person52023년 1월 4일부터 이전 값을 표시합니다.
UPDATE ice_table SET color='new_color' WHERE name='Person5' SELECT * FROM "iceberg_db"."ice_table" FOR TIMESTAMP AS OF TIMESTAMP '2023-01-04 12:00:00 UTC'
샘플 출력:
시간 이동 쿼리의 구문과 추가 예제는 Athena 설명서를 참조하세요.
Iceberg 테이블 구조
이제 Iceberg 테이블 작업의 기본 단계를 살펴보았으므로 Iceberg 테이블의 복잡한 세부 정보와 설계에 대해 자세히 살펴보겠습니다.
이 가이드의 앞부분에서 설명한 기능을 활성화하기 위해 Iceberg는 데이터 및 메타데이터 파일의 계층적 계층으로 설계되었습니다. 이러한 계층은 메타데이터를 지능적으로 관리하여 쿼리 계획 및 실행을 최적화합니다.
다음 다이어그램은 테이블을 저장하는 데 AWS 서비스 사용되는와 Amazon S3에 파일 배치라는 두 가지 관점을 통해 Iceberg 테이블의 구성을 보여줍니다.
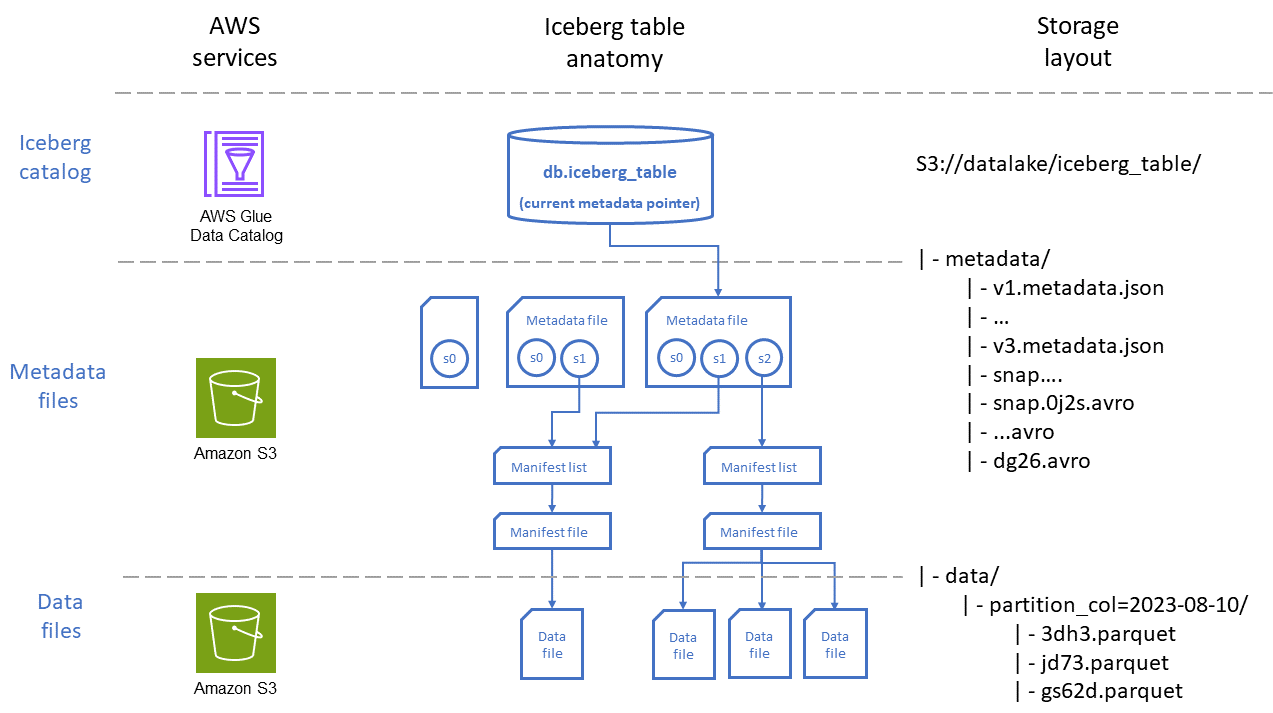
다이어그램과 같이 Iceberg 테이블은 세 가지 기본 계층으로 구성됩니다.
-
Iceberg 카탈로그: AWS Glue Data Catalog integrate는 기본적으로 Iceberg와 통합되며 대부분의 사용 사례에서 실행되는 워크로드에 가장 적합한 옵션입니다 AWS. Iceberg 테이블과 상호 작용하는 서비스(예: Athena)는 카탈로그를 사용하여 데이터를 읽거나 쓸 테이블의 현재 스냅샷 버전을 찾습니다.
-
메타데이터 계층: 메타데이터 파일, 즉 매니페스트 파일 및 매니페스트 목록 파일은 테이블의 스키마, 파티션 전략, 데이터 파일의 위치와 같은 정보와 각 데이터 파일에 저장된 레코드의 최소 및 최대 범위와 같은 열 수준 통계를 추적합니다. 이러한 메타데이터 파일은 테이블 경로 내의 Amazon S3에 저장됩니다.
-
매니페스트 파일에는 위치, 형식, 크기, 체크섬 및 기타 관련 정보를 포함하여 각 데이터 파일에 대한 레코드가 포함됩니다.
-
매니페스트 목록은 매니페스트 파일의 인덱스를 제공합니다. 테이블에서 매니페스트 파일 수가 증가함에 따라 해당 정보를 더 작은 하위 섹션으로 나누면 쿼리로 스캔해야 하는 매니페스트 파일 수를 줄이는 데 도움이 됩니다.
-
메타데이터 파일에는 매니페스트 목록, 스키마, 파티션 메타데이터, 스냅샷 파일 및 테이블의 메타데이터를 관리하는 데 사용되는 기타 파일을 포함하여 전체 Iceberg 테이블에 대한 정보가 포함됩니다.
-
-
데이터 계층:이 계층에는 쿼리가 실행될 데이터 레코드가 있는 파일이 포함됩니다. 이러한 파일은 Apache Parquet
, Apache Avro, Apache ORC 등 다양한 형식으로 저장할 수 있습니다. -
데이터 파일에는 테이블에 대한 데이터 레코드가 포함됩니다.
-
Iceberg 테이블에서 행 수준 삭제 및 업데이트 작업을 인코딩하는 파일을 삭제합니다. Iceberg 설명서에 설명된 대로 Iceberg
에는 두 가지 유형의 삭제 파일이 있습니다. 이러한 파일은 merge-on-read 모드를 사용하여 작업에 의해 생성됩니다.
-
