기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
압축을 사용하여 테이블 유지 관리
Iceberg에는 테이블에 데이터를 쓴 후 테이블 유지 관리 작업을
Iceberg 압축
Iceberg에서는 압축을 사용하여 다음 4가지 작업을 수행할 수 있습니다.
-
작은 파일을 일반적으로 크기가 100MB를 초과하는 더 큰 파일로 결합합니다. 이 기술을 빈 패킹이라고 합니다.
-
삭제 파일을 데이터 파일과 병합합니다. 삭제 파일은 merge-on-read 접근 방식을 사용하는 업데이트 또는 삭제에 의해 생성됩니다.
-
(재)쿼리 패턴에 따라 데이터 정렬. 데이터는 정렬 순서 없이 또는 쓰기 및 업데이트에 적합한 정렬 순서로 작성할 수 있습니다.
-
공간 채우기 곡선을 사용하여 데이터를 클러스터링하여 고유한 쿼리 패턴, 특히 z 순서 정렬을 최적화합니다.
에서 Amazon Athena를 통해 또는 Amazon EMR 또는에서 Spark를 사용하여 Iceberg에 대한 테이블 압축 및 유지 관리 작업을 실행할 AWS수 있습니다 AWS Glue.
rewrite_data_files
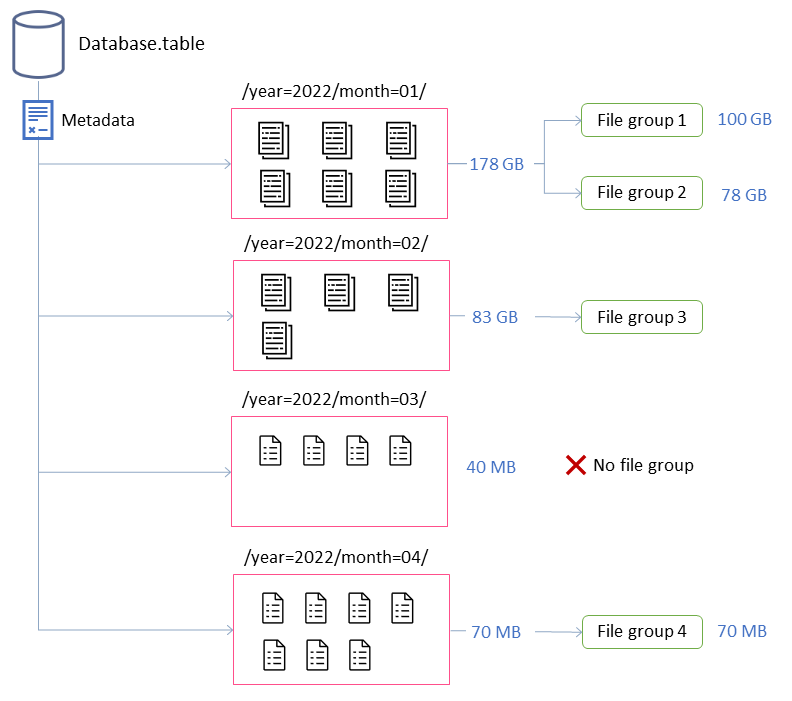
이 예제에서 Iceberg 테이블은 4개의 파티션으로 구성됩니다. 파티션마다 크기가 다르고 파일 수가 다릅니다. Spark 애플리케이션을 시작하여 압축을 실행하면 애플리케이션은 처리할 총 4개의 파일 그룹을 생성합니다. 파일 그룹은 단일 Spark 작업에서 처리할 파일 모음을 나타내는 Iceberg 추상화입니다. 즉, 압축을 실행하는 Spark 애플리케이션은 데이터를 처리하는 4개의 Spark 작업을 생성합니다.
압축 동작 튜닝
다음 키 속성은 압축을 위해 데이터 파일을 선택하는 방법을 제어합니다.
-
MAX_FILE_GROUP_SIZE_BYTES
는 기본적으로 단일 파일 그룹(Spark 작업)의 데이터 제한을 100GB로 설정합니다. 이 속성은 파티션이 없는 테이블 또는 수백 기가바이트에 걸친 파티션이 있는 테이블에서 특히 중요합니다. 이 제한을 설정하면 작업을 계획하고 진행하면서 클러스터의 리소스 소진을 방지하는 작업을 세분화할 수 있습니다. 참고: 각 파일 그룹은 별도로 정렬됩니다. 따라서 파티션 수준 정렬을 수행하려면 파티션 크기에 맞게이 제한을 조정해야 합니다.
-
MIN_FILE_SIZE_BYTES
또는 MIN_FILE_SIZE_DEFAULT_RATIO 는 기본적으로 테이블 수준에서 설정된 대상 파일 크기의 75%로 설정됩니다. 예를 들어 테이블의 대상 크기가 512MB인 경우 384MB보다 작은 모든 파일이 압축될 파일 세트에 포함됩니다. -
MAX_FILE_SIZE_BYTES
또는 MAX_FILE_SIZE_DEFAULT_RATIO 는 기본적으로 대상 파일 크기의 180%로 설정됩니다. 최소 파일 크기를 설정하는 두 가지 속성과 마찬가지로 이러한 속성은 압축 작업의 후보 파일을 식별하는 데 사용됩니다. -
MIN_INPUT_FILES
는 테이블 파티션 크기가 대상 파일 크기보다 작은 경우 압축할 최소 파일 수를 지정합니다. 이 속성의 값은 파일 수(기본값은 5)를 기준으로 파일을 압축할 가치가 있는지 여부를 결정하는 데 사용됩니다. -
DELETE_FILE_THRESHOLD
는 압축에 포함되기 전에 파일에 대한 최소 삭제 작업 수를 지정합니다. 달리 지정하지 않는 한 압축은 삭제 파일을 데이터 파일과 결합하지 않습니다. 이 기능을 활성화하려면이 속성을 사용하여 임계값을 설정해야 합니다. 이 임계값은 개별 데이터 파일에 고유하므로 3으로 설정하면 데이터 파일을 참조하는 삭제 파일이 3개 이상 있는 경우에만 데이터 파일이 다시 작성됩니다.
이러한 속성은 이전 다이어그램에서 파일 그룹의 형성에 대한 인사이트를 제공합니다.
예를 들어 레이블이 지정된 파티션은 최대 크기 제약 조건인 100GB를 초과하기 때문에 두 개의 파일 그룹을 month=01 포함합니다. 반면 파티션은 100GB 미만이므로 단일 파일 그룹을 month=02 포함합니다. month=03 파티션이 파일 5개의 기본 최소 입력 파일 요구 사항을 충족하지 않습니다. 따라서 압축되지 않습니다. 마지막으로 month=04 파티션에 원하는 크기의 단일 파일을 형성하기에 충분한 데이터가 포함되어 있지 않지만 파티션에 5개 이상의 작은 파일이 포함되어 있기 때문에 파일이 압축됩니다.
Amazon EMR 또는에서 실행되는 Spark에 대해 이러한 파라미터를 설정할 수 있습니다 AWS Glue. Amazon Athena의 경우 접두사 )로 시작하는 테이블 속성을 사용하여 유사한 속성을 관리할 수 있습니다optimize_.
Amazon EMR 또는에서 Spark로 압축 실행 AWS Glue
이 섹션에서는 Iceberg의 압축 유틸리티를 실행하기 위해 Spark 클러스터의 크기를 적절하게 조정하는 방법을 설명합니다. 다음 예제에서는 Amazon EMR Serverless를 사용하지만 Amazon EMR on EC2 또는 EKS 또는에서 동일한 방법론을 사용할 수 있습니다 AWS Glue.
파일 그룹과 Spark 작업 간의 상관 관계를 활용하여 클러스터 리소스를 계획할 수 있습니다. 파일 그룹당 최대 크기인 100GB를 고려하여 파일 그룹을 순차적으로 처리하려면 다음 Spark 속성을 설정할 수 있습니다.
-
spark.dynamicAllocation.enabled=FALSE -
spark.executor.memory=20 GB -
spark.executor.instances=5
압축 속도를 높이려면 병렬로 압축되는 파일 그룹 수를 늘려 수평적으로 확장할 수 있습니다. 수동 또는 동적 조정을 사용하여 Amazon EMR을 조정할 수도 있습니다.
-
수동 조정(예: 4배)
-
MAX_CONCURRENT_FILE_GROUP_REWRITES=4(계수) -
spark.executor.instances=5(예제에 사용된 값) x4(계수) =20 -
spark.dynamicAllocation.enabled=FALSE
-
-
동적 조정
-
spark.dynamicAllocation.enabled=TRUE(기본값, 작업 필요 없음) -
MAX_CONCURRENT_FILE_GROUP_REWRITES
= N(이 값을 기본적으로 100spark.dynamicAllocation.maxExecutors인와 정렬합니다. 예제의 실행기 구성에 따라를 20N으로 설정할 수 있습니다.)
다음은 클러스터 크기를 조정하는 데 도움이 되는 지침입니다. 하지만 워크로드에 가장 적합한 설정을 찾으려면 Spark 작업의 성능도 모니터링해야 합니다.
-
Amazon Athena로 압축 실행
Athena는 OPTIMIZE 문을 통해 Iceberg의 압축 유틸리티를 관리형 기능으로 구현합니다. 인프라를 평가할 필요 없이이 문을 사용하여 압축을 실행할 수 있습니다.
이 문은 빈 패킹 알고리즘을 사용하여 작은 파일을 더 큰 파일로 그룹화하고 삭제 파일을 기존 데이터 파일과 병합합니다. 계층적 정렬 또는 z 순서 정렬을 사용하여 데이터를 클러스터링하려면 Amazon EMR 또는에서 Spark를 사용합니다 AWS Glue.
OPTIMIZE 문에 테이블 속성을 전달하여 테이블 생성 시 또는 문을 사용하여 테이블 생성 후 CREATE TABLE 문의 기본 동작을 변경할 수 ALTER TABLE 있습니다. 기본값은 Athena 설명서를 참조하세요.
압축 실행을 위한 권장 사항
사용 사례: |
권장 사항 |
|---|---|
일정에 따라 빈 패킹 압축 실행 |
|
이벤트를 기반으로 빈 패킹 압축 실행 |
|
압축을 실행하여 데이터 정렬 |
|
압축을 실행하여 z 순서 정렬을 사용하여 데이터 클러스터링 |
|
지연 도착 데이터로 인해 다른 애플리케이션에서 업데이트할 수 있는 파티션에서 압축 실행 |
|
콜드 파티션(더 이상 활성 쓰기를 수신하지 않는 데이터 파티션)에서 압축 실행 |
|
