기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
서버리스 AI 아키텍처 설계
서버리스 AI의 원칙을 실제 시스템으로 변환하려면 신중한 아키텍처가 필요합니다. 목표는 탄력적으로 확장되고 실시간으로 응답하는 모듈식 지능형 파이프라인 AWS 서비스 에 느슨하게 결합된를 통합하는 것입니다.
이 섹션에서는 생성형 AI 오케스트레이션, 실시간 추론, 엣지 컴퓨팅을 포함한 AWS 서버리스 서비스를 사용하여 클라우드 네이티브 AI 시스템을 조합하는 방법에 대한 규범적 지침을 제공합니다. 각 아키텍처 패턴은 일반적인 엔터프라이즈 사용 사례에 대응하여 관련성과 적용 가능성을 보장합니다.
이 섹션
기본 아키텍처 패턴
기존 이벤트 기반 애플리케이션 아키텍처에서 시스템은 확장성과 응답성을 지원하면서 문제를 분리하는 4개의 논리적 계층으로 구성됩니다. 상단에서 애플리케이션 계층은 사용자 상호 작용, APIs 및 UI 이벤트를 처리하여 종종 도메인별 이벤트를 시스템으로 트리거합니다. 그 아래에 오케스트레이션 계층은 상태 시스템 또는 서버리스 워크플로와 같은 도구를 사용하여 워크플로, 비즈니스 규칙 및 이벤트 시퀀싱을 관리합니다. 서비스 계층에는 이벤트에 응답하고 코어 로직을 실행하는 재사용 가능한 모듈식 함수 또는 마이크로서비스가 포함되어 있습니다. 기본적으로 데이터 계층은 지속성, 스트리밍 및 이벤트 소싱을 담당합니다. 데이터 계층은 데이터베이스, 객체 스토어 또는 이벤트 로그와 같은 서비스를 활용하여 변경 이벤트를 내보내고 소비합니다. 이러한 계층은 이벤트가 전체 스택에서 흐름을 구동하는 느슨하게 결합되고 확장 가능하며 유지 관리 가능한 아키텍처를 지원합니다.
서버리스 AI 시스템은 마찬가지로 독립적으로 확장, 발전 및 복구할 수 있는 느슨하게 결합된 이벤트 기반 서비스로 구성됩니다. 일관성과 확장성으로 이러한 시스템을 설계하려면 아키텍처를 5개의 개별 계층으로 보는 것이 중요합니다. 각 계층은 특정 함수를 제공하고 특별히 빌드된에 직접 매핑됩니다 AWS 서비스. 다음 다이어그램은 각 계층을 보여줍니다.
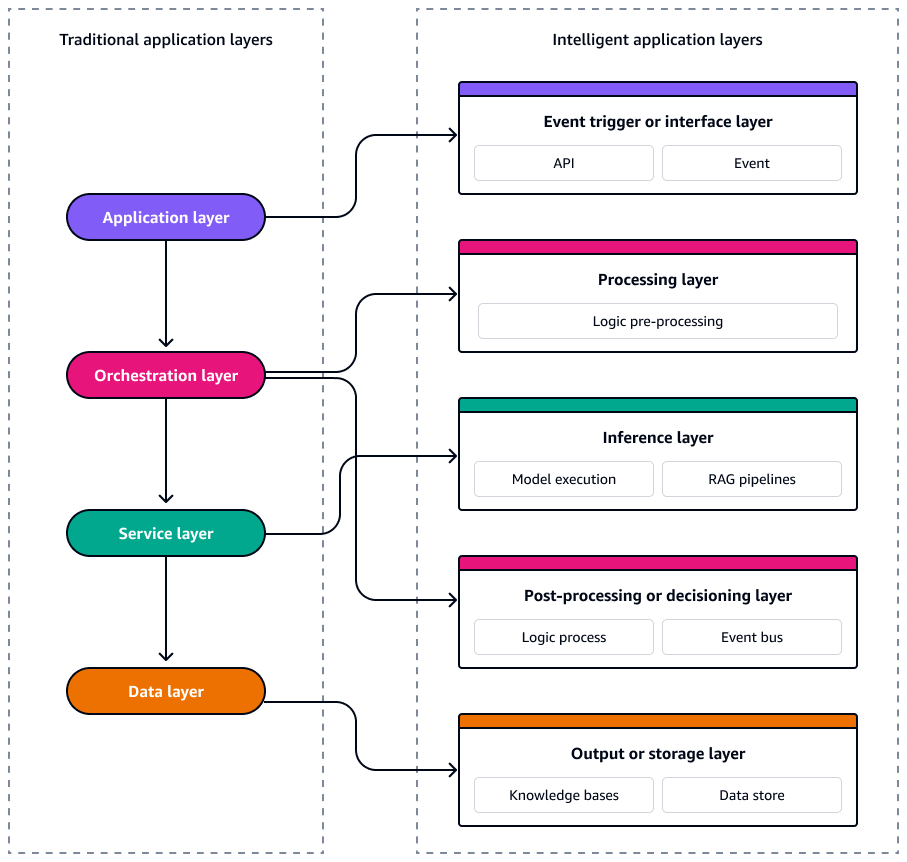
이 5개 계층은 복원력이 뛰어나고 관찰 가능하며 비용과 성능 모두에 최적화된 지능형 이벤트 기반 애플리케이션을 구축하기 위한 청사진을 형성합니다.
이벤트 트리거 또는 인터페이스 계층
이벤트 트리거 또는 인터페이스 계층은 서버리스 AI 시스템의 진입점입니다. 사용자 상호 작용, 시스템 이벤트 또는 데이터 변경 사항을 캡처하고 구조화된 이벤트로 아키텍처에 내보냅니다. 비동기 오케스트레이션을 활성화하고 다운스트림 처리 로직에서 업스트림 입력을 분리합니다.
이벤트 트리거 계층의 책임은 다음과 같습니다.
-
클릭, 메시지 및 업로드와 같은 사용자 작업 캡처
-
도메인 이벤트 또는 변경 알림 종료
-
다운스트림 소비를 위해 수신 데이터 정규화
AWS 서비스 이 계층에서 일반적으로 사용되는 에는 다음이 포함됩니다.
-
Amazon API Gateway는 REST 또는 WebSocket APIs.
-
Amazon EventBridge는 스키마 레지스트리를 사용하여 내부 또는 외부 이벤트를 라우팅합니다.
-
Amazon Simple Storage Service(Amazon S3)는 문서 업로드 및 미디어 파일과 같은 객체 생성 시 트리거됩니다.
-
Amazon Kinesis 및 Amazon Managed Streaming for Apache Kafka(Amazon MSK)는 대규모로 스트리밍 이벤트를 수집합니다.
예: 웹 양식을 통해 제출된 고객 지원 요청은 EventBridge 규칙을 트리거하여 Amazon Bedrock 에이전트 워크플로 다운스트림을 시작합니다.
처리 계층
처리 계층은 데이터를 AI 모델에 전달하기 전에 데이터를 변환하거나 보강합니다. 조회 테이블 또는 외부 APIs를 사용하여 입력 검증, 형식 지정, 메타데이터 태그 지정, 언어 감지 및 데이터 보강과 같은 사전 처리 작업을 처리합니다.
처리 계층의 책임은 다음과 같습니다.
-
원시 입력을 검증하고 정규화합니다.
-
언어 및 고객 ID와 같은 메타데이터를 추출하거나 주입합니다.
-
데이터 속성을 기반으로 하는 라우팅 또는 브랜치 로직입니다.
AWS 서비스 이 계층에서 일반적으로 사용되는 에는 다음이 포함됩니다.
-
AWS Lambda는 변환 로직을 위한 상태 비저장 이벤트 기반 컴퓨팅입니다.
-
AWS Step Functions 다단계 사전 처리 작업을 오케스트레이션합니다.
-
Amazon Comprehend는 사전 처리의 일부로 언어 감지, 개체 인식 또는 감정 분석을 제공합니다.
예: 업로드된 보험 청구는 AI 요약 전에 Lambda 및 Amazon Comprehend를 사용하여 개인 식별 정보(PII) 및 문서 유형에 대해 스캔됩니다.
추론 계층
AI 시스템의 핵심인 추론 계층은 기계 학습(ML) 또는 파운데이션 모델(FM) 추론을 실행합니다. 사용 사례에 따라 생성형, 예측형 또는 분류 모델이 하나 이상 포함될 수 있습니다.
추론 계층의 책임은 다음과 같습니다.
-
ML 또는 FM 모델 추론을 실행합니다.
-
예측, 분류 또는 생성된 콘텐츠를 생성합니다.
-
해당하는 경우 검색 증강 생성(RAG) 컨텍스트를 통합합니다.
AWS 서비스 이 계층에서 일반적으로 사용되는 에는 다음이 포함됩니다.
-
Amazon Bedrock은 Anthropic, Amazon(Amazon Nova용), 및와 같은 공급자의 파운데이션 모델 추론(텍스트, 이미지Meta, 멀티모달)을 제공합니다Mistral.
-
Amazon SageMaker Serverless Inference는 대규모로 사용자 지정 ML 모델을 실행합니다.
-
Amazon Bedrock Agents는 대규모 언어 모델(LLM) 기반 추론 및 목표 기반 오케스트레이션을 제공합니다.
예: Amazon Bedrock 에이전트는 Amazon Nova Pro를 사용하여 RAG를 사용한 엔터프라이즈 지식을 기반으로 복잡한 지원 쿼리에 대한 응답을 생성합니다.
사후 처리 또는 결정 계층
사후 처리 또는 결정 계층은 추론 결과를 구체화하거나 이에 따라 작동합니다. 응답의 형식을 지정하거나, 출력을 로깅하거나, 다운스트림 작업을 호출하거나, 모델 신뢰도, 분류 또는 외부 비즈니스 규칙에 따라 결정을 내릴 수 있습니다.
사후 처리 또는 결정 계층의 책임은 다음과 같습니다.
-
다운스트림 시스템 또는 디스플레이에 대한 AI 출력 형식을 지정합니다.
-
조건부 로직을 트리거하거나 APIs.
-
스토리지 또는 분석을 위해 보강된 데이터를 라우팅합니다.
AWS 서비스 이 계층에서 일반적으로 사용되는 에는 다음이 포함됩니다.
-
Lambda는 결과의 형식을 지정하거나, 변환을 적용하거나, APIs.
-
Amazon Simple Notification Service(Amazon SNS) 및 EventBridge는 모델 출력을 기반으로 추가 이벤트를 내보냅니다.
-
Step Functions는 체인 로직을 적용합니다. 예를 들어 감정이 "분노"와 같은 경우 지원 사례를 에스컬레이션합니다.
예: LLM의 제품 권장 사항은 사용자에게 권장 사항을 보내기 전에 Lambda 함수를 사용하여 실시간 인벤토리에 대해 교차 검증됩니다.
출력 또는 스토리지 계층
마지막으로 출력 또는 스토리지 계층은 사용자 또는 시스템에 대한 결과 전달을 처리하고 감사, 분석 또는 피드백 루프를 위한 구조화된 출력을 유지합니다.
출력 또는 스토리지 계층의 책임은 다음과 같습니다.
-
APIs 또는 UIs.
-
구조화된 출력 및 로그를 유지합니다.
-
데이터 레이크 또는 재훈련 파이프라인에 피드합니다.
AWS 서비스 이 계층에서 일반적으로 사용되는 에는 다음이 포함됩니다.
-
Amazon S3는 추론 로그, 요약 또는 생성된 콘텐츠를 저장합니다.
-
Amazon DynamoDB는 세션별 AI 출력을 위한 지연 시간이 짧은 키-값 스토리지를 제공합니다.
-
Amazon OpenSearch Service는 검색 및 분석을 위한 인덱스 구조화 출력을 제공합니다.
-
API Gateway 및 WebSocket APIs 프런트엔드 또는 모바일 클라이언트에 반환 응답을 제공합니다.
예: Amazon Bedrock에서 생성한 법률 문서 요약은 Amazon S3에 저장되고 OpenSearch Service에 인덱싱되어 의미 체계 엔터프라이즈 검색을 활성화합니다.
계층 간 설계 고려 사항
다음과 같은 주요 설계 고려 사항 및 패턴이 모든 아키텍처 계층에 적용됩니다.
-
복원력 - 각 계층은 독립적으로 실패하고 재시도해야 합니다(예: Lambda의 DLQs Letter Queue)).
-
관찰성 - 각 단계의 구조화된 로그, 트레이스 및 지표를 Amazon CloudWatch로 내보내 동작 드리프트를 감지합니다.
-
보안 - 계층 간 데이터 암호화에 AWS Identity and Access Management (IAM) 역할 분리 및 AWS Key Management Service (AWS KMS)를 사용합니다.
-
비용 최적화 - 가능하면 비동기식 실행을 사용하고 적절한 크기의 모델을 선택합니다.
-
확장성 - 모듈식 설계를 통해 서비스를 독립적으로 교체하거나 업그레이드할 수 있습니다.
이 5개 계층은 AI 기반 워크로드를 위한 확장 가능한 모듈식 서버리스 참조 아키텍처를 형성합니다 AWS. 각 계층은 독립적으로 개발, 배포 및 최적화할 수 있으므로 신속한 반복, 운영 우수성 및 비즈니스 도메인 간 우려 사항의 명확한 분리가 가능합니다.
이 계층화된 패턴을 설계 스캐폴드로 사용하면 기업은 서버리스 AI에 대한 접근 방식을 표준화하고 프로토타입에서 프로덕션으로의 경로를 자신 있게 가속화할 수 있습니다.
아키텍처 설계 고려 사항
의 서버리스 AI 아키텍처 AWS 를 사용하면 모듈식, 확장 가능 및 프로덕션 등급의 지능형 애플리케이션을 구축할 수 있습니다. 엣지에서 모델을 배포하든, 다단계 추론 파이프라인을 오케스트레이션하든, 생성형 AI 어시스턴트를 구축하든는 차세대 AI 네이티브 애플리케이션을 지원할 AWS 서비스 수 있습니다.
서버리스 AI 아키텍처를 설계할 때는 다음 주요 설계 중점 사항과 모범 사례를 염두에 두세요.
-
보안 - 세분화된 IAM 역할을 사용하고, 프롬프트 및 출력을 암호화하고, API 액세스를 제한합니다.
-
관찰성 - 모든 파이프라인 단계에 대해 CloudWatch AWS X-Ray, 및 사용자 지정 로그를 통합합니다.
-
확장성 - Lambda, Amazon Bedrock, SageMaker Serverless Inference와 같은 서버리스 구성 요소만 사용합니다.
-
지연 시간 - Lambda@Edge, 프로비저닝된 동시성 또는 비동기 추론을 활용합니다.
-
모듈성 - 각 작업에 대해 이벤트 트리거와 격리된 함수를 사용하여 파이프라인을 설계합니다.
-
재사용성 - Step Functions를 사용하여 프롬프트를 파라미터화하고, 공유 Lambda 계층을 사용하고, 로직을 분리합니다.
