기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
평가자 및 반사 구체화 루프를 위한 워크플로
이 워크플로는 한 LLM이 결과를 생성하고 다른 LLM이 결과를 평가하거나 평가하는 피드백 루프를 제공합니다. 이를 통해 자기 성찰, 최적화 및 반복적인 개선이 촉진됩니다.
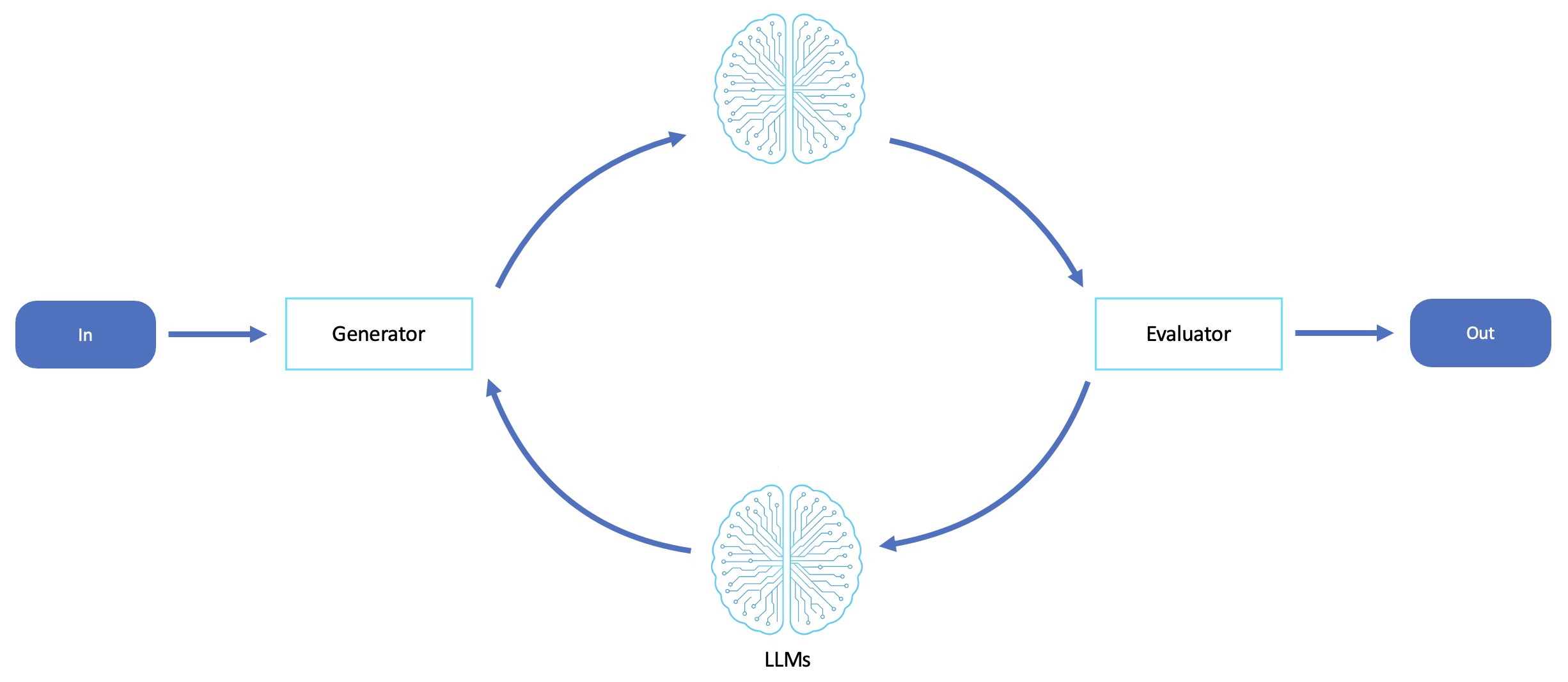
평가자 워크플로는 출력 품질, 정확도 및 정렬이 중요하고 단일 패스 생성을 신뢰할 수 없거나 충분하지 않은 시나리오에 적합합니다. 이 워크플로는 에이전트가 더 높은 정확성 표준을 충족하거나 피드백을 기반으로 개선된 대안을 탐색하기 위해 자체 비판, 반복 및 개선해야 하는 경우에 유용합니다.
이 워크플로는 다음과 같은 경우에 특히 효과적입니다.
-
출력에는 주관적 품질 지표(예: 스타일, 어조 및 가독성) 또는 목표 기준(예: 정확성, 안전성 및 성능)이 포함됩니다.
-
에이전트는 절충을 통해 추론하거나, 제약 조건을 평가하거나, 목표를 향해 최적화해야 합니다.
-
특히 규제, 고객 대면 또는 크리에이티브 도메인에서 기본 제공 중복성 및 품질 보증이 필요합니다.
-
Human-in-the-loop 검토는 비용이 많이 들거나 사용할 수 없으며 자율 검증이 필요합니다.
이 워크플로는 콘텐츠 생성, 코드 합성 및 검토, 정책 적용, 정렬 검사, 명령 튜닝 및 RAG 사후 처리에 사용됩니다. 또한 지속적인 피드백이 시간이 지남에 따라 더 나은 응답을 형성하여 신뢰할 수 있고 자율적인 의사 결정 루프를 구축하는 데 도움이 되는 자체 개선 에이전트에도 유용합니다.
일반 사용 사례
-
블루 팀 에이전트와 비교한 레드 팀 에이전트
-
코드 또는 계획을 생성, 평가 및 수정하는 에이전트
-
품질 보증, 할루시네이션 감지 및 스타일 적용
기능
-
다양한 모델을 사용하여 분리된 생성 및 평가를 지원합니다(예: Claude for generation 및 Mistral for evaluation).
-
피드백은 구조화되어 있으며 수정된 출력을 표시하는 데 사용됩니다.
-
다중 반복 또는 수렴 임계값 지원
