기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
기본 추론 에이전트
기본 추론 에이전트는 쿼리에 대한 응답으로 논리적 추론 또는 의사 결정을 수행하는 가장 간단한 형태의 에이전트 AI입니다. 사용자 또는 시스템의 입력을 수락하고 쿼리를 처리하고 구조화된 프롬프트를 사용하여 응답을 생성합니다.
이 패턴은 주어진 컨텍스트를 기반으로 한 단일 단계 추론, 분류 또는 요약이 필요한 작업에 유용합니다. 메모리, 도구 또는 상태 관리를 사용하지 않으므로 대규모 워크플로에서 상태 비저장, 경량 및 고도로 구성 가능합니다.
아키텍처
기본 추론 에이전트의 흐름은 다음 다이어그램에 나와 있습니다.
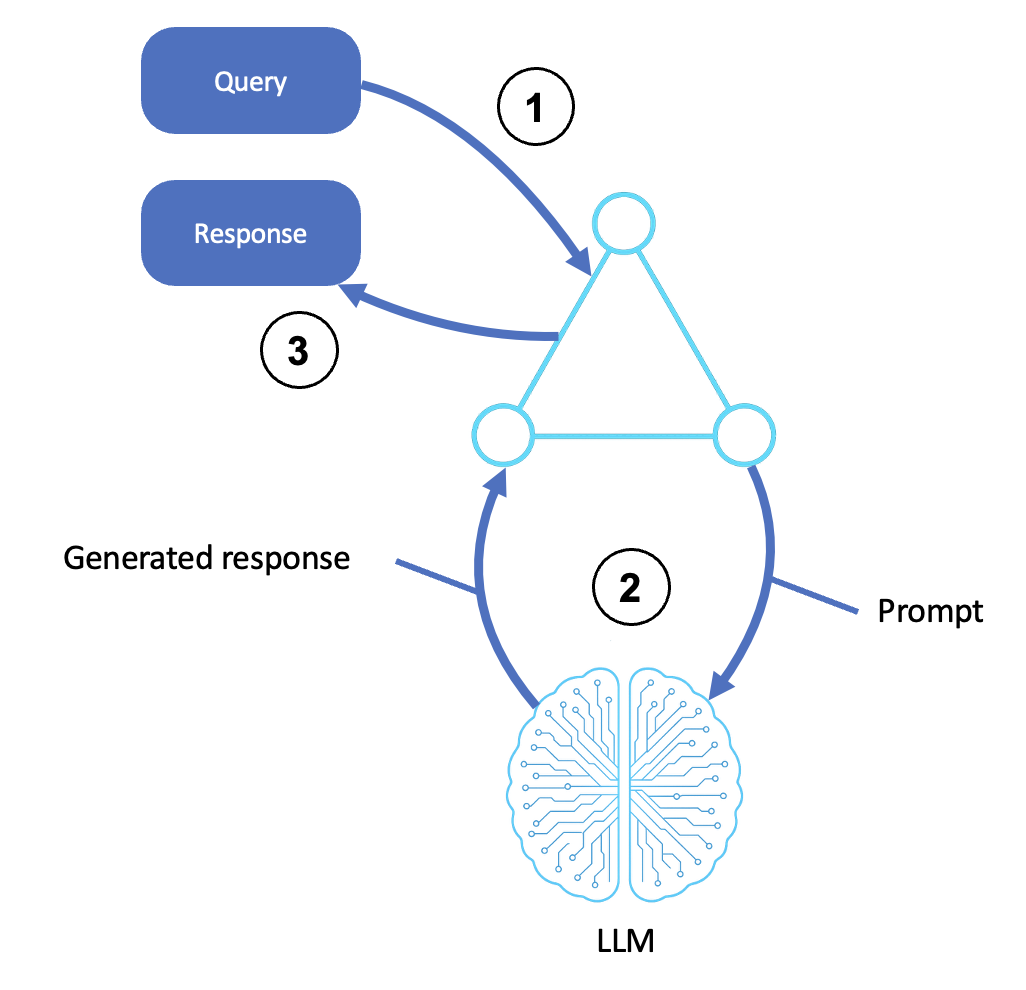
설명
-
입력을 수신합니다.
-
사용자, 시스템 또는 업스트림 에이전트가 쿼리 또는 명령을 제출합니다.
-
입력은 에이전트 쉘 또는 오케스트레이션 계층으로 전달됩니다.
-
이 단계에는 모든 사전 처리, 프롬프트 템플릿 지정 및 목표 식별이 포함됩니다.
-
-
LLM을 호출합니다.
-
에이전트는 쿼리를 구조화된 프롬프트로 변환하여 LLM으로 전송합니다(예: Amazon Bedrock을 통해).
-
LLM은 사전 훈련된 지식 및 컨텍스트를 사용하여 프롬프트를 기반으로 응답을 생성합니다.
-
생성된 출력에는 추론 단계(chain-of-thought), 최종 답변 또는 순위 옵션이 포함될 수 있습니다.
-
-
응답을 반환합니다.
-
생성된 출력은 에이전트의 인터페이스로 릴레이됩니다.
-
여기에는 형식 지정, 사후 처리 또는 API 응답이 포함될 수 있습니다.
-
기능
-
자연어 또는 구조화된 입력 지원
-
프롬프트 엔지니어링을 사용하여 동작을 안내합니다.
-
상태 비저장 및 확장 가능
-
UI, CLI, APIs 및 파이프라인에 포함할 수 있습니다.
제한 사항
-
메모리 없음 또는 기록 인식
-
외부 도구 또는 데이터 소스와의 상호 작용 없음
-
추론 시 LLM이 알고 있는 내용으로 제한됨
일반 사용 사례
-
대화 질문 및 답변
-
정책 설명 및 요약
-
의사 결정을 위한 지침
-
가볍고 자동화된 챗봇 흐름
-
분류, 레이블 지정 및 점수
구현 지침
다음 도구 및 서비스를 사용하여 기본 추론 에이전트를 생성할 수 있습니다.
-
LLM 호출용 Amazon Bedrock(Anthropic, AI21, Meta)
-
Amazon API Gateway 또는 AWS Lambda - 상태 비저장 마이크로서비스로 노출
-
파라미터 스토어 또는 코드 AWS Secrets Manager로 저장된 프롬프트 템플릿
요약
기본 추론 에이전트는 단순한 구조로 인해 기본적입니다. 목표를 지능형 출력으로 이어지는 추론 경로로 전환하는 핵심 기능이 있습니다. 이 패턴은 도구 기반 에이전트 및 검색 증강 생성(RAG)을 사용하는 에이전트와 같은 고급 패턴의 출발점인 경우가 많습니다. 또한 대규모 워크플로의 신뢰할 수 있는 모듈식 구성 요소입니다.
에이전트 RAG
검색 증강 생성(RAG)은 정보 검색과 텍스트 생성을 결합하여 정확하고 상황에 맞는 응답을 생성하는 기법입니다. RAG를 사용하면 에이전트가 LLM을 사용하기 전에 관련 외부 정보를 검색할 수 있습니다. 최신 정보, up-to-date 사실 정보 또는 도메인별 정보를 바탕으로 에이전트의 효과적인 메모리와 추론 정확도를 높입니다. 사전 훈련된 가중치에만 의존하는 상태 비저장 LLMs과 달리 RAG에는 컨텍스트를 사용하여 프롬프트를 동적으로 개선하는 외부 지식 검색 계층이 있습니다.
아키텍처
RAG 패턴의 로직은 다음 다이어그램에 나와 있습니다.
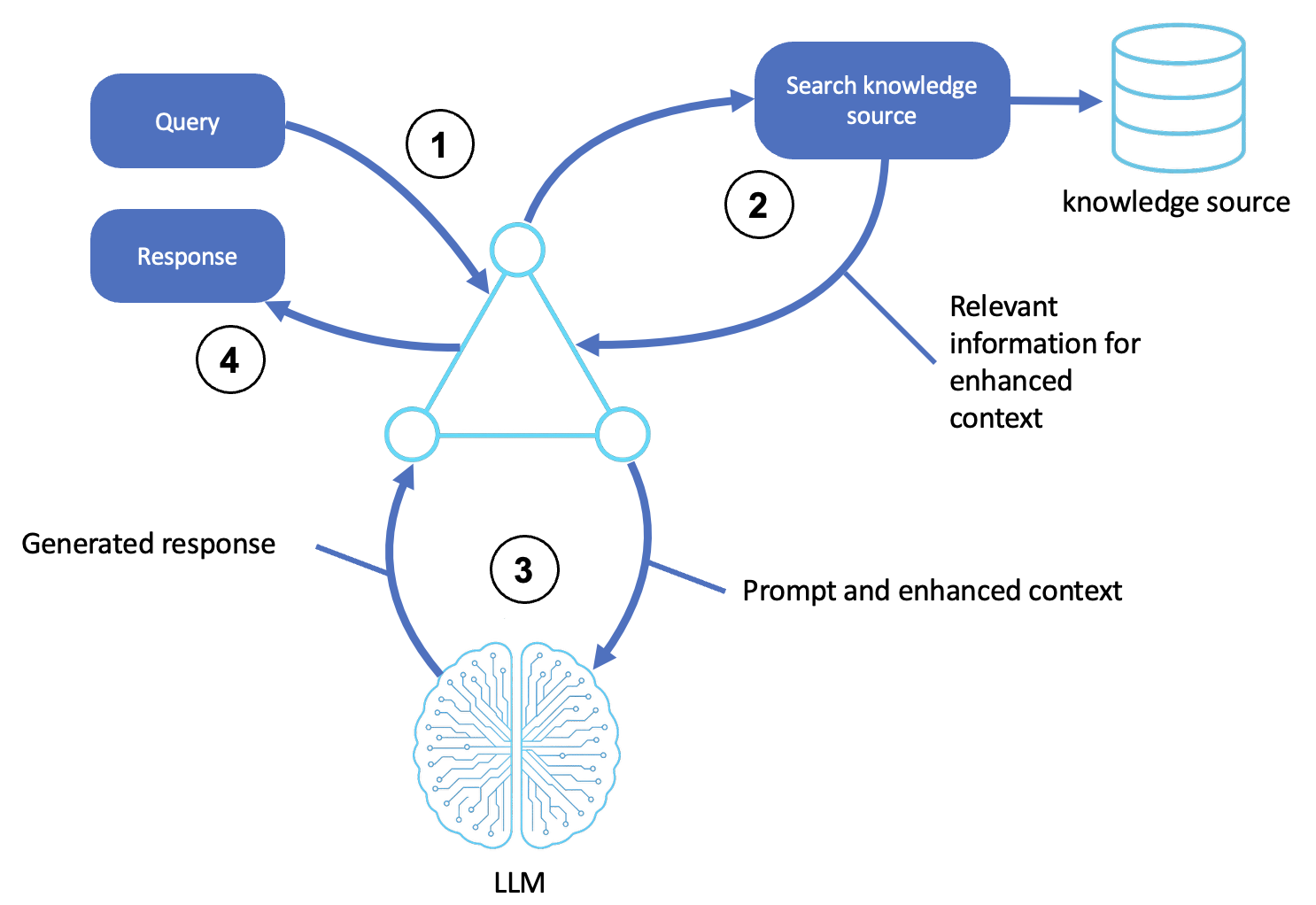
설명
-
쿼리를 수신합니다.
-
사용자 또는 업스트림 시스템은 에이전트에게 쿼리 또는 목표를 제출합니다.
-
에이전트 쉘은 요청을 수락하고 추론을 위한 프롬프트로 형식을 지정합니다.
-
-
외부 소스를 검색합니다.
-
에이전트는 쿼리에서 개념과 의도를 식별합니다.
-
의미 체계 검색 또는 키워드 일치를 사용하여 벡터 저장소, 데이터베이스 또는 문서 인덱스와 같은 지식 소스를 쿼리합니다.
-
가장 관련성이 높은 구절, 문서 또는 엔터티는 다음 단계에서 사용할 수 있도록 검색됩니다.
-
-
컨텍스트 응답을 생성합니다.
-
에이전트는 검색된 정보로 프롬프트를 보강하여 LLM에 대한 컨텍스트 강화 입력을 형성합니다.
-
LLM은 생성형 추론(예: chain-of-thought 또는 반영)을 사용하여 모든 입력을 처리하여 정확한 응답을 생성합니다.
-
-
최종 출력을 반환합니다.
-
에이전트는 출력을 모든 통신 헤더 또는 필요한 서식으로 래핑하여 준비한 다음 사용자 또는 호출 시스템에 반환합니다.
-
(선택 사항) 검색된 문서 및 LLM 출력은 향후 쿼리를 위해 로깅되고 점수가 매겨지고 메모리에 저장될 수 있습니다.
-
기능
-
롱테일 또는 엔터프라이즈별 도메인에서도 사실 기반 출력
-
모델을 미세 조정하지 않는 메모리 확장
-
각 쿼리 및 사용자 상태에 따른 동적 컨텍스트
-
벡터 데이터베이스, 의미 체계 인덱스 및 메타데이터 필터링과 완벽하게 호환
일반 사용 사례
-
엔터프라이즈 지식 도우미
-
규정 준수 봇
-
고객 지원 부조종사
-
검색 강화 챗봇
-
개발자 설명서 에이전트
구현 지침
다음 도구 및 서비스를 사용하여 RAG를 사용하는 에이전트를 생성합니다.
-
LLM 호출을 위한 Amazon Bedrock
-
설명서 또는 구조화된 데이터 검색을 위한 Amazon Kendra, OpenSearch 또는 Amazon Aurora
-
문서 스토리지용 Amazon Simple Storage Service(Amazon S3)
-
AWS Lambda 검색, 프롬프트 및 LLM 추론을 오케스트레이션하려면
-
에이전트와의 지식 기반 통합(메모리 플러그인, 의미 체계 리트리버 또는 Amazon Bedrock 사용)
요약
에이전트 RAG는 정적 모델 추론을 동적 실제 인텔리전스에 연결합니다. 에이전트가 모르는 내용을 조회하고, 검색된 지식의 답변을 합성하고, 신뢰도가 높고 감사 가능한 응답을 생성할 수 있는 기능을 제공합니다.
RAG 패턴은 재훈련 없이 지식 액세스를 확장하는 지능형 에이전트를 구축하기 위한 기반입니다. 도구 사용, 계획 및 장기 메모리와 관련된 보다 복잡한 오케스트레이션 패턴의 전조인 경우가 많습니다.
