기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
AWS ParallelCluster Auto Scaling
참고
이 섹션은AWS ParallelCluster버전 2.11.4까지의 버전에만 적용됩니다. 버전 2.11.5부터는AWS ParallelCluster가 SGE 또는 Torque 스케줄러의 사용을 지원하지 않습니다. 2.11.4 이하의 버전에서는 계속 사용할 수 있지만 서비스 및AWS지원 팀의 향후 업데이트 또는 문제 해결 지원을AWS받을 수 없습니다.
AWS ParallelCluster버전 2.9.0부터 Auto Scaling은 Slurm Workload Manager (Slurm)에서 사용할 수 없습니다. Slurm 및 다중 대기열 스케일링에 대한 자세한 내용은 다중 대기열 모드 자습서를 참조하세요.
이 항목에 설명된 Auto Scaling 전략은 Son of Grid Engine(SGE) 또는 Torque Resource Manager(Torque) 중 하나를 사용하여 배포되는 HPC 클러스터에 적용됩니다. 이러한 스케줄러 중 하나를 사용하여 배포한 경우AWS ParallelCluster는 컴퓨팅 노드의 Auto Scaling 그룹을 관리하고 필요에 따라 스케줄러 구성을 변경하여 조정 기능을 구현합니다. 기반 HPC 클러스터의 경우AWS Batch는AWS관리형 작업 스케줄러에서 제공하는 탄력적 조정 기능을AWS ParallelCluster사용합니다. 자세한 내용은 Amazon EC2 Auto Scaling 사용 설명서의 Amazon EC2 Auto Scaling이란?을 참조하세요.
와 함께 배포된 클러스터AWS ParallelCluster는 여러 가지 방식으로 탄력적입니다. initial_queue_size는 ComputeFleet Auto Scaling 그룹의 최소 크기 값을 설정하고 원하는 용량 값도 설정합니다. max_queue_size는 ComputeFleet Auto Scaling 그룹의 최대 크기 값을 설정합니다.
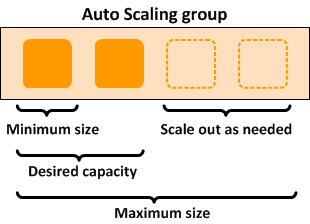
확장
jobwatcher
SGE 스케줄러에서는 각 작업에 실행할 슬롯이 여러 개 필요합니다(슬롯 하나가 vCPU와 같은 처리 장치 하나에 해당). 현재 대기 중인 작업을 제공하는 데 필요한 인스턴스 수를 평가할 때 jobwatcher는 요청된 슬롯의 총 수를 단일 컴퓨팅 노드의 용량으로 나눕니다. 사용 가능한 vCPU 수인 컴퓨팅 노드 용량은 클러스터 구성에서 지정된 Amazon EC2 인스턴스 유형에 따라 다릅니다.
Slurm (AWS ParallelCluster버전 2.9.0 이전) 및 Torque 스케줄러를 사용하면 상황에 따라 각 작업에 노드 수와 모든 노드에 대한 슬롯 수가 모두 필요할 수 있습니다. 각 요청에 대해 jobwatcher는 새로운 계산 요구 사항을 충족시키는 데 필요한 컴퓨팅 노드 수를 결정합니다. 예를 들어, 컴퓨팅 인스턴스 유형이 c5.2xlarge(8 vCPU)이고, 다음과 같은 요구 사항을 가진 3개의 작업이 대기열에 보류 중이라고 가정합니다.
-
job1: 노드 2개/각각 슬롯 4개
-
job2: 노드 3개/각각 슬롯 2개
-
job3: 노드 1개/각각 슬롯 4개
이 예제에서 jobwatcher는 3개의 작업에 대해 사용할 3개의 새로운 컴퓨팅 인스턴스가Auto Scaling 그룹에 필요합니다.
현재 제한: 자동 스케일 업 로직에서는 부분적으로 로드된 사용 중인 노드를 고려하지 않습니다. 예를 들어, 작업을 실행 중인 노드는 빈 슬롯이 있더라도 사용 중인 노드로 간주됩니다.
축소
각 컴퓨팅 노드에서 nodewatcher
-
인스턴스에 scaledown_idletime(기본 설정: 10분)보다 기간이 긴 작업이 없는 경우
-
클러스터에 보류 중인 작업이 없는 경우
인스턴스를 종료하기 위해 nodewatcher는 TerminateInstanceInAutoScalingGroup API 작업을 호출합니다. 이 작업은 Auto Scaling 그룹 크기가 최소 Auto Scaling 그룹 크기인 경우에 인스턴스를 제거합니다. 이 프로세스는 실행 중인 작업에 영향을 미치지 않고 클러스터를 축소합니다. 또한 기본 인스턴스 수가 고정된 탄력적인 클러스터를 활성화할 수 있습니다.
정적 클러스터
자동 확장 값은 HPC의 경우 다른 워크로드와 동일합니다. 유일한 차이점은AWS ParallelCluster에 더 지능적으로 상호 작용하는 코드가 있다는 것입니다. 예를 들어, 정적 클러스터가 필요한 경우 initial_queue_size 및 max_queue_size 파라미터를 필요한 클러스터의 정확한 크기로 설정한 다음 maintain_initial_size 파라미터를 true로 설정합니다. 이렇게 하면 ComputeFleet Auto Scaling 그룹은 최소, 최대 및 원하는 용량에 대해 동일한 값을 갖게 됩니다.
