비전 이해 프롬프팅 기술
참고
이 설명서는 Amazon Nova 버전 1용입니다. Amazon Nova 2에서 멀티모달 프롬프트를 이해하는 방법에 대한 자세한 내용은 멀티모달 입력 프롬프트를 참조하세요.
다음 비전 프롬프팅 기술은 Amazon Nova에 대한 더 나은 프롬프트를 생성하는 데 도움이 됩니다.
주제
배치가 중요함
문서를 추가하기 전에 미디어 파일(예: 이미지 또는 비디오)을 배치한 다음 모델을 안내하는 지침 텍스트 또는 프롬프트를 배치하는 것이 좋습니다. 텍스트 뒤에 이미지를 배치하거나 텍스트 사이에 이미지를 삽입해도 제대로 작동만 사용 사례에서 허용하는 경우 {media_file}-then-{text} 구조가 선호되는 방식입니다.
다음 템플릿을 사용하여 비전 이해를 수행할 때 텍스트 앞에 미디어 파일을 배치할 수 있습니다.
{ "role": "user", "content": [ { "image": "..." }, { "video": "..." }, { "document": "..." }, { "text": "..." } ] }
구조를 따르지 않음 |
최적화된 프롬프트 |
|
|---|---|---|
User |
[Image1.png] 이미지에서 무슨 일이 일어나고 있는지 설명합니다. |
[Image1.png] 이미지에서 무슨 일이 일어나고 있는지 설명합니다. |
비전 구성 요소가 있는 여러 미디어 파일
여러 차례에 걸쳐 여러 미디어 파일을 제공하는 경우 각 이미지에 번호가 매겨진 레이블을 붙여 소개합니다. 예를 들어, 2개의 이미지를 사용하는 경우 Image
1:과 Image 2:라고 레이블을 지정합니다. 3개의 비디오를 사용하는 경우 Video
1:, Video 2:, Video 3:이라고 레이블을 지정합니다. 이미지 사이 또는 이미지와 프롬프트 사이에 줄 바꿈이 필요하지 않습니다.
다음 템플릿을 사용하여 여러 미디어 파일을 배치할 수 있습니다.
messages = [ { "role": "user", "content": [ {"text":"Image 1:"}, {"image": {"format": "jpeg", "source": {"bytes": img_1_base64}}}, {"text":"Image 2:"}, {"image": {"format": "jpeg", "source": {"bytes": img_2_base64}}}, {"text":"Image 3:"}, {"image": {"format": "jpeg", "source": {"bytes": img_3_base64}}}, {"text":"Image 4:"}, {"image": {"format": "jpeg", "source": {"bytes": img_4_base64}}}, {"text":"Image 5:"}, {"image": {"format": "jpeg", "source": {"bytes": img_5_base64}}}, {"text":user_prompt}, ], } ]
최적화되지 않은 프롬프트 |
최적화된 프롬프트 |
|---|---|
|
두 번째 이미지에서 보이는 것이 무엇인지 설명하세요. [Image1.png] [Image2.png] |
[Image1.png] [Image2.png] 두 번째 이미지에서 보이는 것이 무엇인지 설명하세요. |
|
포함된 문서에 두 번째 이미지가 설명되어 있나요? [Image1.png] [Image2.png] [Document1.pdf] |
[Image1.png] [Image2.png] [Document1.pdf] 포함된 문서에 두 번째 이미지가 설명되어 있나요? |
미디어 파일 유형의 긴 컨텍스트 토큰으로 인해 프롬프트의 시작 부분에 표시된 시스템 프롬프트가 특정 경우에 충족되지 않을 수 있습니다. 이 경우 시스템 가이드를 사용자 턴으로 이동하고 {media_file}-then-{text}의 일반 가이드를 따르는 것이 좋습니다. 이는 RAG, 에이전트 또는 도구 사용에 대한 시스템 프롬프팅에 영향을 주지 않습니다.
비전 이해 작업에 대한 지침 준수 개선을 위해 사용자 지침 사용
비디오 이해를 위해 컨텍스트 내 토큰의 수가 많기 때문에 배치가 중요함에 대한 권장 사항이 매우 중요합니다. 톤과 스타일 등 보다 일반적인 사항에 대해서는 시스템 프롬프트를 사용합니다. 더 나은 성능을 위해 비디오 관련 지침을 사용자 메시지에 포함시키는 것이 좋습니다.
다음 템플릿을 사용하여 지침을 개선할 수 있습니다.
{ "role": "user", "content": [ { "video": { "format": "mp4", "source": { ... } } }, { "text": "You are an expert in recipe videos. Describe this video in less than 200 words following these guidelines: ..." } ] }
텍스트와 마찬가지로 이미지와 비디오에 생각의 사슬을 적용하여 성능을 개선하는 것이 좋습니다. 또한 사용자 프롬프트의 다른 지침을 유지하면서 시스템 프롬프트에 생각의 사슬 지시문을 배치하는 것이 좋습니다.
중요
Amazon Nova Premier 모델은 Amazon Nova 패밀리의 더 높은 인텔리전스 모델이며 더 복잡한 태스크를 처리할 수 있습니다. 작업에 고급 생각의 사슬이 필요한 경우 Amazon Nova에 생각할 시간 주기(생각의 사슬)에 제공된 프롬프트 템플릿을 활용하는 것이 좋습니다. 이 접근 방식은 모델의 분석 및 문제 해결 능력을 개선하는 데 도움이 될 수 있습니다.
샷 예시가 거의 없음
텍스트 모델과 마찬가지로 이미지 이해 성능을 개선하기 위한 이미지 예제를 제공하는 것이 좋습니다(추론당 비디오 1개 제한으로 인해 비디오 예제를 제공할 수 없음). 시스템 프롬프트에 예제를 제공하는 대신 미디어 파일 뒤에 사용자 프롬프트에 예제를 배치하는 것이 좋습니다.
| 0-Shot | 2-Shot | |
|---|---|---|
| User | [Image 1] | |
| Assistant | The image 1 description | |
| User | [Image 2] | |
| Assistant | The image 2 description | |
| User | [이미지 3] 이미지에서 무슨 일이 일어나고 있는지 설명 |
[이미지 3] 이미지에서 무슨 일이 일어나고 있는지 설명 |
경계 상자 감지
객체의 경계 상자 좌표를 식별해야 하는 경우 Amazon Nova 모델을 활용하여 [0, 1000]의 스케일로 경계 상자를 출력할 수 있습니다. 이러한 좌표를 얻은 후 사후 처리 단계로 이미지 치수를 기준으로 크기를 조정할 수 있습니다. 이 사후 처리 단계를 수행하는 방법에 대한 자세한 내용은 Amazon Nova Image Grounding notebook
다음은 경계 상자 감지를 위한 샘플 프롬프트입니다.
Detect bounding box of objects in the image, only detect {item_name} category objects with high confidence, output in a list of bounding box format. Output example: [ {"{item_name}": [x1, y1, x2, y2]}, ... ] Result:
더 풍부한 출력 또는 스타일
비디오 이해 출력은 매우 짧을 수 있습니다. 더 긴 출력을 원하는 경우 모델에 대한 페르소나를 생성하는 것이 좋습니다. 시스템 역할을 활용하는 것과 마찬가지로 이 페르소나가 원하는 방식으로 응답하도록 지시할 수 있습니다.
원샷 및 퓨샷 기술을 사용하여 응답을 추가로 수정할 수 있습니다. 좋은 응답이 무엇이어야 하는지에 대한 예제를 제공하고 모델은 답변을 생성하는 동안 응답의 측면을 모방할 수 있습니다.
마크다운으로 문서 콘텐츠 추출
Amazon Nova Premier는 문서에 포함된 차트를 이해하고 과학 논문과 같은 복잡한 도메인에서 콘텐츠를 읽고 이해할 수 있는 향상된 기능을 보여줍니다. 또한 Amazon Nova Premier는 문서 콘텐츠를 추출할 때 향상된 성능을 보여주며 이 정보를 마크다운 테이블 및 Latex 형식으로 출력할 수 있습니다.
다음 예제에서는 이미지에 있는 테이블과 함께 Amazon Nova Premier에 이미지의 내용을 마크다운 테이블로 변환하도록 지시하는 프롬프트를 제공합니다. 마크다운(또는 Latex 표현)이 생성된 후 도구를 사용하여 콘텐츠를 JSON 또는 기타 구조화된 출력으로 변환할 수 있습니다.
Make a table representation in Markdown of the image provided.
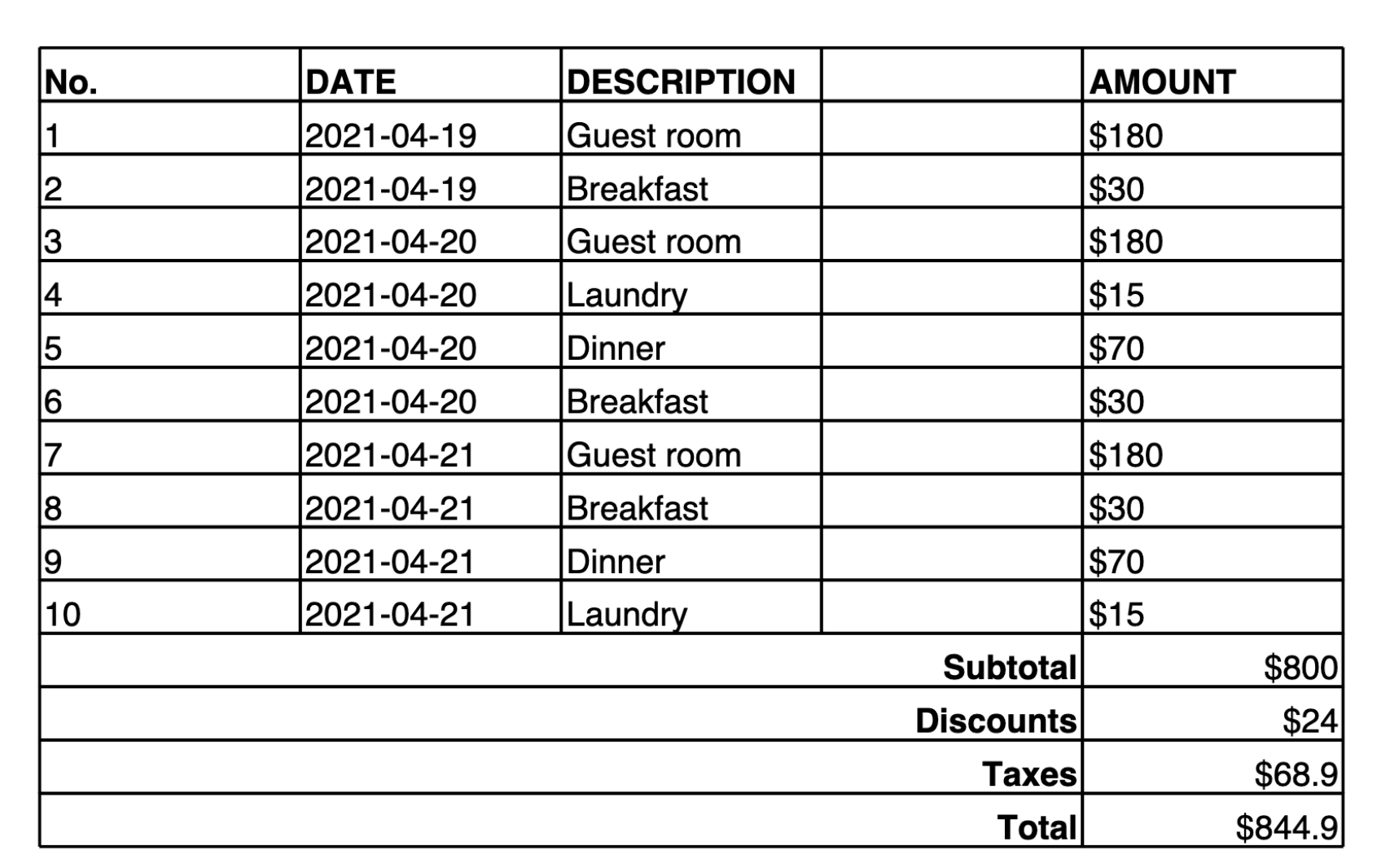
다음은 모델에서 제공하는 출력입니다.
| No. | DATE | DESCRIPTION | AMOUNT | |-----|------------|-------------|--------| | 1 | 2021-04-19 | Guest room | $180 | | 2 | 2021-04-19 | Breakfast | $30 | | 3 | 2021-04-20 | Guest room | $180 | | 4 | 2021-04-20 | Laundry | $15 | | 5 | 2021-04-20 | Dinner | $70 | | 6 | 2021-04-20 | Breakfast | $30 | | 7 | 2021-04-21 | Guest room | $180 | | 8 | 2021-04-21 | Breakfast | $30 | | 9 | 2021-04-21 | Dinner | $70 | | 10 | 2021-04-21 | Laundry | $15 | | | | Subtotal | $800 | | | | Discounts | $24 | | | | Taxes | $68.9 | | | | Total | $844.9 |
이 출력은 ||가 열 구분자로 사용되고 &&가 행 구분자로 사용되는 사용자 지정 테이블 표기법을 사용합니다.
비전 이해를 위한 추론 파라미터 설정
비전 이해 사용 사례를 위해 추론 파라미터 temperature를 0로 설정하고 topK를 1로 설정하는 것으로 시작하는 것이 좋습니다. 모델의 출력을 관찰한 후에 사용 사례에 따라 추론 파라미터를 조정할 수 있습니다. 이러한 값은 일반적으로 필요한 작업 및 분산에 따라 달라지며, 답변에 더 많은 변화를 유도하도록 온도 설정을 늘립니다.
동영상 분류
비디오 콘텐츠를 적절한 범주로 효과적으로 정렬하려면 모델이 분류에 사용할 수 있는 범주를 제공해야 합니다. 다음 샘플 프롬프트를 고려하세요.
[Video] Which category would best fit this video? Choose an option from the list below: \Education\Film & Animation\Sports\Comedy\News & Politics\Travel & Events\Entertainment\Trailers\How-to & Style\Pets & Animals\Gaming\Nonprofits & Activism\People & Blogs\Music\Science & Technology\Autos & Vehicles
비디오 태그 지정
Amazon Nova Premier는 비디오 태그 생성을 위한 향상된 기능을 보여줍니다. 최상의 결과를 얻으려면 쉼표로 구분된 태그를 요청하는 '쉼표를 사용하여 각 태그를 구분' 지침을 사용합니다. 다음은 프롬프트의 예입니다.
[video] "Can you list the relevant tags for this video? Use commas to separate each tag."
비디오의 고밀도 캡션
Amazon Nova Premier는 비디오 내 여러 세그먼트에 대해 생성된 자세한 텍스트 설명인 고밀도 캡션을 제공하는 향상된 기능을 보여줍니다. 다음은 프롬프트의 예입니다.
[Video] Generate a comprehensive caption that covers all major events and visual elements in the video.
