기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
재해 복구 계획
재해 복구(DR)는 엔터프라이즈 비즈니스 연속성 및 규정 준수를 위한 중요한 서비스입니다. AMS는 고객과 협력하여 AMS에서 DR 전략을 계획, 구현 및 유지 관리하는 데 도움을 줍니다.
다중 계정 및 단일 계정인 AMS 랜딩 존(LZ)은 대부분의 재해 보호 시나리오를 충족하는 AMS 인프라 구성 요소에 대해 네이티브 다중 AZ 고가용성을 제공합니다. 그러나 비즈니스의 지리적 범위에 따라 리전별 보호가 필요할 수 있습니다. 리전 간 가용성 및 DR을 위해서는 다른 리전에 다른 AMS 계정이 필요합니다(다중 계정 랜딩 존과 단일 계정 랜딩 존 모두에 해당).
AMS는이 블로그에 설명된 AWS DR 지침에 따라 재해 발생 시 미션 크리티컬 시스템을 신속하게 복구
다중 사이트(또는 가용성이 높음)
웜 스탠바이
파일럿 라이트
백업 및 복원
이러한 옵션 및 AMS 지원은 다음 섹션에 설명되어 있습니다.
다중 사이트 또는 고가용성(HA)
HA 솔루션은 일반적으로 클러스터링 또는 동기식 복제와 같은 애플리케이션의 내장 기능을 통해 제공됩니다. 사용자는 Prod 노드와 HA/DR 노드로 모두 이동합니다. DNS는 노드를 직접 또는 탄력적 로드 밸런서(ELB)를 통해 가리킵니다.
AMS 클라우드 아키텍트(CA)는 Well-Architected-Review 및 DR 계획의 일부로 함께 작업합니다.
HA DR은 다음 그림과 같이 애플리케이션 및 AWS네이티브 서비스와 기능을 활용합니다.
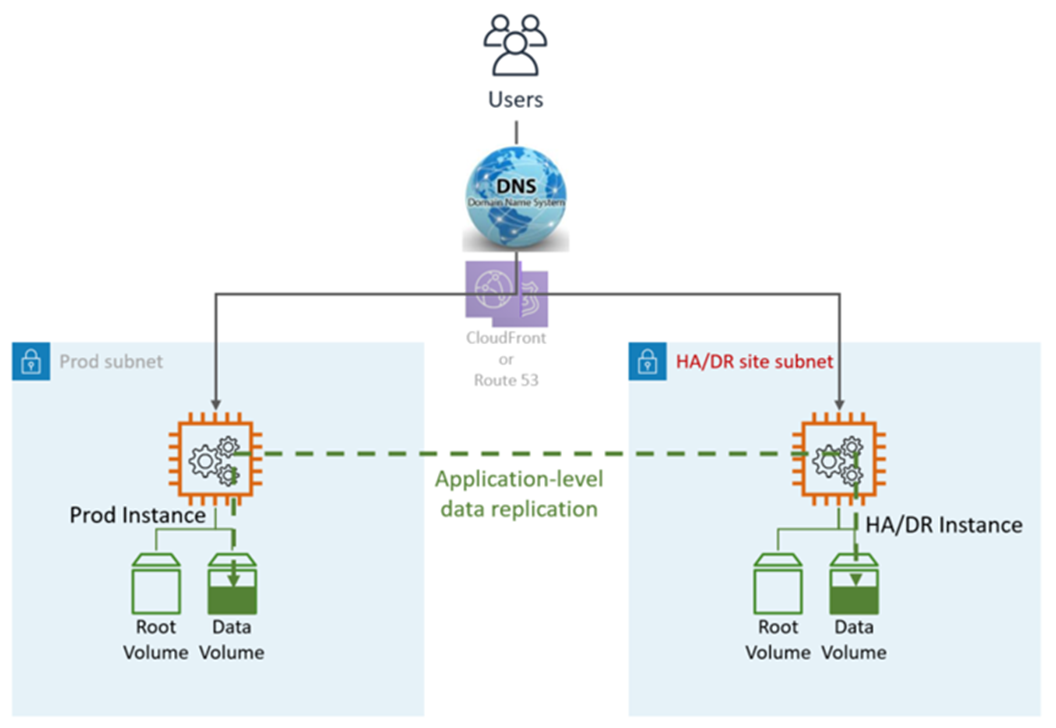
DR 사이트는 동일하거나 다를 수 있습니다 AWS 리전.
참고
리전(교차 리전)마다 Active Directory 환경이 다릅니다.
DR(장애 조치) 단계: 자동 장애 조치, 수동 단계는 필요하지 않습니다. 기본 LZ에 장애가 발생하는 경우 사용자는 자동으로 DR/HA 노드로 다시 라우팅됩니다. 이는 DNS 및 애플리케이션 구성 모두에 의해 달성됩니다.
HA DR 지표:
Recovery Point Objective(RPO): <5분
Recovery Time Objective and (RTO): <5분
유지 관리: 높음(애플리케이션 구성, 패치 적용, SG 또는 ALB, 인증서 등과 같은 두 환경 모두에서 동기식 변경이 필요함).
비용: 높음
웜 대기
"웜 스탠바이"라는 용어는 확장 버전의 환경이 클라우드에서 실행되는 재해 복구(DR) 시나리오를 설명하는 데 사용됩니다.
데이터 복제는 애플리케이션 계층에서 일반적으로 온라인 인스턴스로 비동기적으로 처리되는 반면, 나머지 인스턴스(예: 애플리케이션 및 웹 계층)는 비용을 절약하기 위해 꺼질 수 있습니다. 사용자는 프로덕션 사이트로만 이동합니다. 탄력적 로드 밸런서(ELB)와 같은 다른 AWS 리소스도 DR 사이트에서 사전 프로비저닝될 수 있습니다.
AMS Cloud Architect(CA)는 Well-Architected-Review 및 DR 계획의 일환으로 사용자와 협력합니다.
웜 스탠바이 DR은 다음 그림과 같이 애플리케이션 및 AWS네이티브 서비스와 기능을 활용합니다.
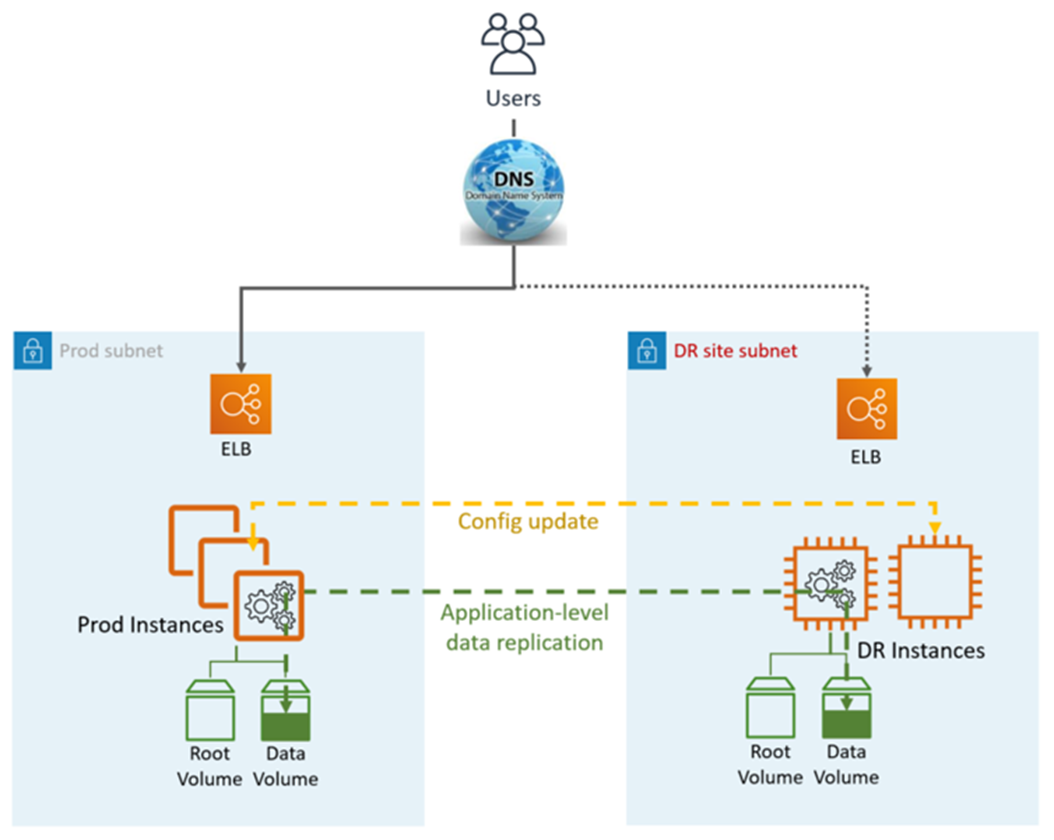
DR 사이트는 동일하거나 다를 수 있습니다 AWS 리전.
참고
리전(교차 리전)마다 Active Directory 환경이 다릅니다.
DR(장애 조치) 단계:
데이터 복제를 중지하고 DR 사이트의 데이터 인스턴스를 마스터로 설정
필요에 따라 애플리케이션 구성 업데이트(새 IP, 서버 이름 등)
DNS를 DR 사이트(ELB)로 리디렉션
필요한 경우 AD 종속성(서비스 계정, SPNs, GPOs 등)
HA DR 지표:
Recovery Point Objective(RPO): <1시간
Recovery Time Objective and (RTO): <1시간(인스턴스 수 및 오케스트레이션에 따라 다름)
유지 관리: 높음(애플리케이션 구성, 패치 적용, 보안 그룹(SG) 또는 애플리케이션 로드 밸런서(ALB), 인증서 등과 같은 두 환경 모두에서 동기식 변경이 필요함).
비용: 중간
파일럿 라이트
이 재해 복구(DR) 접근 방식에서는 제한된 코어 서비스 세트에 대해 Prod 환경의 일부를 복제합니다. 인프라의 작은 부분은 항상 실행되고 있으며 변경 가능한 데이터(예: 데이터베이스 또는 문서)를 동시에 동기화하는 반면 인프라의 다른 부분은 꺼져 있고 테스트 중에만 사용됩니다. 백업 및 복구 접근 방식과 달리 가장 중요한 코어 요소가 이미 구성되어 있고 DR 랜딩 존(시도등)에서 실행되고 있는지 확인해야 합니다.
AMS 클라우드 아키텍트는 Well-Architected-Review 및 DR 계획의 일환으로 고객과 협력합니다.
Pilot Light DR은 다음 그림과 같이 애플리케이션 및 AWS네이티브 서비스와 기능을 활용합니다.
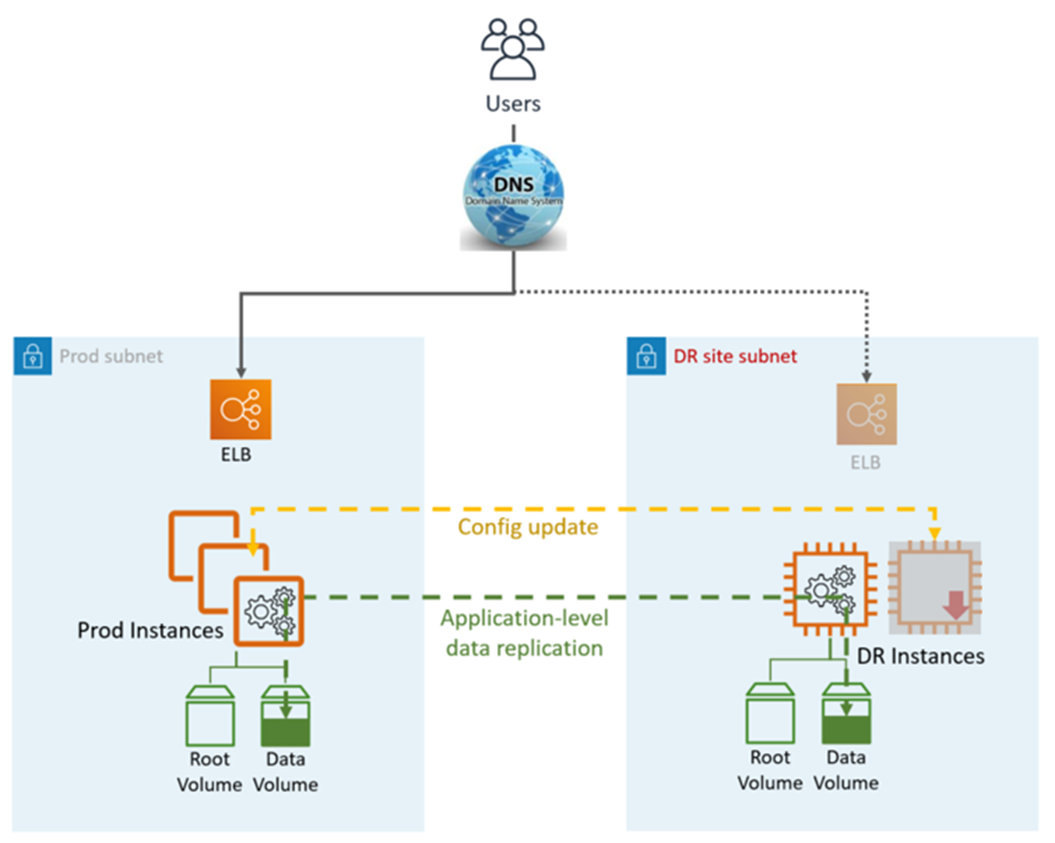
DR 사이트는 동일하거나 다를 수 있습니다 AWS 리전.
참고
리전(교차 리전)마다 Active Directory 환경이 다릅니다.
DR(장애 조치) 단계:
데이터 복제를 중지하고 DR 사이트의 데이터 인스턴스를 마스터로 설정
꺼진 인스턴스 및 인프라 시작
필요에 따라 애플리케이션 구성 업데이트(새 IP, 서버 이름 등)
필요에 따라 인스턴스를 ELB에 추가
DNS를 DR 사이트(ELB)로 리디렉션
필요한 경우 AD 종속성(서비스 계정, SPNs, GPOs 등)
파일럿 라이트 DR 지표:
Recovery Point Objective(RPO): <1시간
Recovery Time Objective and (RTO): ~1시간(인스턴스 수 및 오케스트레이션에 따라 다름)
유지 관리: 중간
비용: 중간
백업 및 복원
이 간단하고 저렴한 재해 복구(DR) 접근 방식은 재해 복구 중에 사용할 수 있도록 어디서나 DR 랜딩 존으로 데이터와 애플리케이션을 백업합니다.
AMS 클라우드 아키텍트는 백업 및 DR 계획의 일부로 사용자와 협력합니다.
Backup and Restore DR은 다음 그림과 같이 AMS 자동 도구 및 프로세스를 활용합니다.
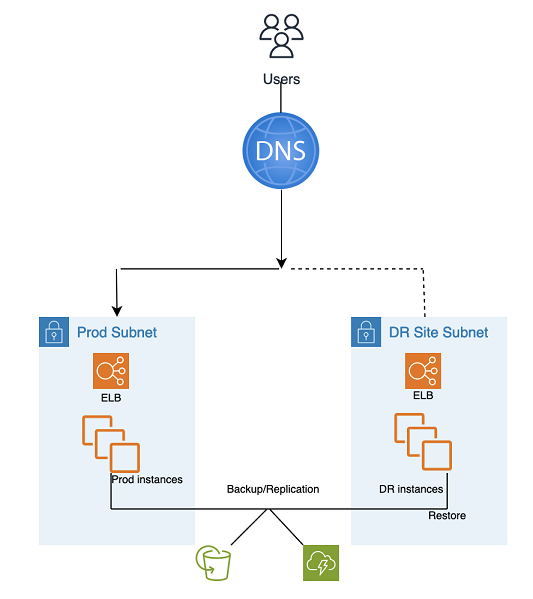
두 가지 백업 및 복제 방법을 사용할 수 있습니다.
"EBS"라고 하는 EBS 스냅샷(복구 시점 목표(RPO) > 1시간)
AWS Elastic Disaster Recovery (복구 시점 목표(RPO) ~ 0.25시간), "DRS"라고 함
DR 사이트는 동일하거나 다른에 있을 수 있습니다 AWS 리전.
참고
다른 리전(교차 리전)에는 다른 Active Directory 환경이 있습니다.
DR(장애 조치) 단계:
스냅샷에서 인스턴스 복원(자리 표시자 인스턴스를 먼저 사용하는 2단계 프로세스)
애플리케이션 구성 업데이트(새 IP, 서버 이름 등)
필요에 따라 다른 인프라 설정(SG, ELB 등)
DNS를 DR 사이트(ELB)로 리디렉션
필요한 경우 AD 종속성 업데이트 또는 복원(서비스 계정, 서비스 보안 주체 이름(SPNs), 그룹 정책 객체(GPOs) 등)
DR 지표 백업 및 복원:
Recovery Point Objective(RPO): >1시간 또는 ~0.25시간(선택한 솔루션에 따라 다름 - EBS 또는 DRE)
Recovery Time Objective and (RTO): ~1시간(인스턴스 수 및 오케스트레이션에 따라 다름)
유지 관리: 높음(애플리케이션 구성, 패치 적용, 보안 그룹 또는 애플리케이션 로드 밸런서, 인증서 등과 같은 두 환경 모두에서 동기식 변경이 필요합니다.
비용: 중간
AMS에서 EBS 스냅샷을 사용하는 EC2에 대한 재해 보호
사전 조건:
AMS Prod 랜딩 존(소스)
AMS DR 랜딩 존(DR 대상)
EC2 인스턴스에 대해 EBS 스냅샷이 활성화됨(AWS Backup)
스냅샷 복제 솔루션:
교차 AZ: 해당 사항 없음 - EBS 스냅샷은 설계상 리전 내에서 가용성이 높습니다.
교차 리전: AWS Backup
다음 다이어그램은 AMS의 EBS 스냅샷에서 EC2 복원 프로세스를 나타냅니다.
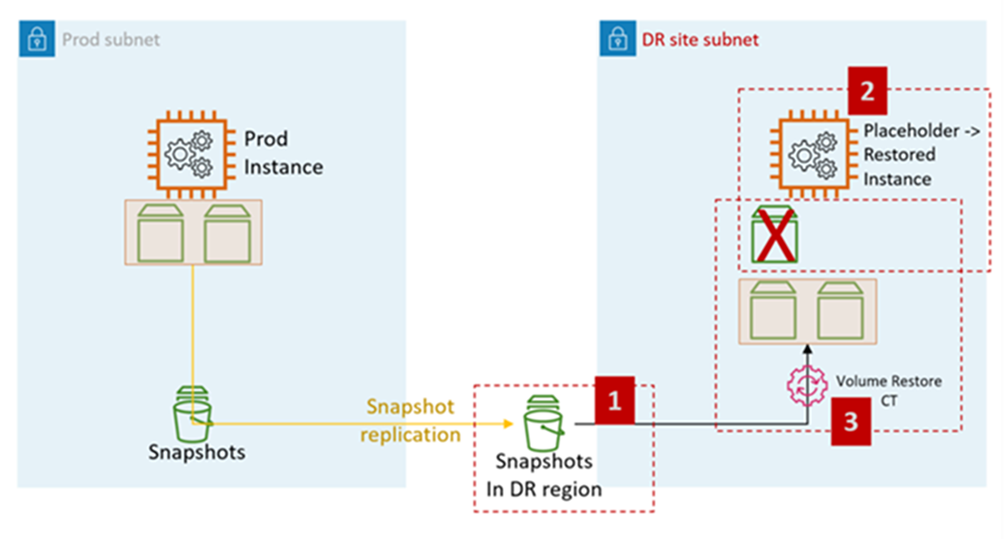
AMS의 EC2 DR 단계:
RFC를 생성하여 대상 계정과 EBS 스냅샷을 공유합니다(교차 리전 DR에 필요).
: 관리, 고급 스택 구성 요소, EBS 스냅샷, 공유
대상 서브넷(DR 사이트 서브넷)에 자리 표시자 EC2 AMS 스택을 생성합니다. 고객이 동일한 스택에서 보안 그룹 및 기타를 할당하는 단계(예: ELB에 인스턴스 추가)를 결합할 수 있으므로 CFN 수집을 사용하여 스택을 생성하는 것이 좋습니다.
변경 유형: 배포, 수집, CloudFormation 템플릿의 스택, 생성
RFC를 높여 EC2 스택 볼륨 복원을 수행합니다.
변경 유형: 관리, 고급 스택 구성 요소, EC2 인스턴스 스택, 볼륨 복원.
CT는 1단계에서 공유된 스냅샷에서 볼륨을 복원하고 2단계에서 생성된 자리 표시자 인스턴스에 연결합니다.
볼륨 복원 CT 기능:
자리 표시자 인스턴스 종료
스냅샷에서 볼륨 복원
볼륨 스왑
인스턴스 시작
이전 도메인에서 나가기
호스트 이름 변경
재부팅합니다. AMS 부트스트랩 스크립트는 시작 시 인스턴스를 대상(DR) 도메인에 조인합니다.
볼륨 복원 CT 입력:
InstanceId(플레이스홀더 인스턴스 ID)
RootDeviceSnapshotId, 복원된 루트 볼륨의 EBS 스냅샷
EC2 인스턴스에서 복원된 모든 볼륨을 암호화하기 위한 KMSKeyId, KMS 키 식별자 또는 ARN
DeviceNames, 최대 25개(선택 사항)
SnapshotIds 최대 25개(선택 사항). 복원할 볼륨의 스냅샷 목록
AMS에서 Elastic Disaster Recovery를 사용하여 EC2에 대한 재해 보호
사전 조건:
AMS Prod 랜딩 존(소스)
AMS DR 랜딩 존(DR 대상)
먼저 사용 AWS 리전 하려는 모든에 대해 Elastic Disaster Recovery 서비스를 초기화해야 합니다.
Elastic Disaster Recovery 콘솔 액세스를 위해 DR 랜딩 존(LZ)에 IAM 역할을 생성합니다.
중요: SSM 문서는 DRS 내에서 시작 후 작업으로 생성됩니다. 이 작업은 PostLaunch 설정의 모든 서버에서 활성화해야 합니다.
대상(자리 표시자) 인스턴스에는 태그 키 "AWSDRS", 값 "AllowLaunchingIntoThisInstance"가 있어야 합니다. 자리 표시자 인스턴스는 중지된 상태여야 합니다. 그렇지 않으면 AMS가 시작 설정에서 자리 표시자 인스턴스를 선택할 수 없고 Elastic Disaster Recovery가 자리 표시자 인스턴스 위에 복원할 수 없습니다.
AMS의 EC2에 대한 Elastic Disaster Recovery 설정 및 복원 프로세스의 다이어그램은 AWS Elastic Disaster Recovery (AWS DRS) 일반 아키텍처를 참조하세요.
AMS에서 Elastic Disaster Recovery를 사용하는 EC2 DR 단계:
적절한 태그를 사용하여 대상 서브넷(DR 사이트 서브넷)에 자리 표시자 EC2 AMS 스택을 생성합니다. 자세한 내용은 이전 섹션을 참조하세요. 동일한 스택에서 보안 그룹을 할당하고 인스턴스, EBS 볼륨 및 기타(예: ELB에 인스턴스 추가)에 태그를 지정하는 단계를 결합할 수 있으므로 CFN 수집을 사용하여 스택을 생성하는 것이 좋습니다.
변경 유형: 배포, 수집, CloudFormation 템플릿의 스택, 생성
자리 표시자 인스턴스를 중지합니다.
변경 유형: 관리, 고급 스택 구성 요소, EC2 인스턴스, 중지
1단계에서 수행하지 않은 경우 자리 표시자 인스턴스와 해당 EBS 볼륨에 키: "AWSDRS", 값: "AllowLaunchingIntoThisInstance"로 태그를 지정합니다.
변경 유형: 관리, 고급 스택 구성 요소, 태그, 업데이트.
소스 서버의 인스턴스 ID로 시작, DRS 시작 설정에서 1단계의 자리 표시자 인스턴스를 대상으로 사용합니다. 소스 서버의 Elastic Disaster Recovery 콘솔에서 인스턴스 복구 드릴을 시작합니다.
참고
자리 표시자 인스턴스 볼륨은 계정에 유지됩니다. 이러한 볼륨을 삭제하려면 재해 복구 작업 종료 시 관리 | 고급 스택 구성 요소 | EBS 볼륨 | 변경 유형 삭제(ct-3e3h8u0sp5z80)를 제출합니다.
Elastic Disaster Recovery 복원 워크플로:
대상(자리 표시자) 인스턴스가 중지됨 상태여야 합니다.
볼륨을 바꾸고 소스(플레이스홀더) 루트 볼륨을 삭제합니다.
인스턴스 시작
시작 후 작업을 실행하여 다음 항목을 완료합니다.
SSM 에이전트를 활성화합니다.
볼륨을 바꾸고 소스(플레이스홀더) 루트 볼륨을 삭제합니다.
인스턴스 시작
PostLaunchScript SSM 문서를 실행합니다. 이 문서는 다음을 수행합니다.
이전 도메인을 떠납니다.
호스트 이름을 변경합니다.
재부팅합니다. AMS 부트스트랩 스크립트는 시작 중에 인스턴스를 대상(DR) 도메인에 조인합니다.
