더 이상 Amazon Machine Learning 서비스를 업데이트하거나 새 사용자를 받지 않습니다. 이 설명서는 기존 사용자에 제공되지만 더 이상 업데이트되지 않습니다. 자세한 내용은 머신 러닝이란? 단원을 참조하세요.
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
바이너리 분류
많은 바이너리 분류 알고리즘의 실제 출력은 예측 점수입니다. 점수는 주어진 관측치가 긍정 클래스에 속한다는 시스템의 확실성을 나타냅니다. 이 점수의 소비자는 관측치를 긍정으로 분류할지 또는 부정으로 분류할 지를 결정하기 위해 분류 임계값(커트라인)을 선택하여 점수를 해석하고 점수를 이 값과 비교합니다. 임계값보다 점수가 높은 관측치는 긍정 클래스로 예측되고, 임계값보다 점수가 낮으면 부정 클래스로 예측됩니다.
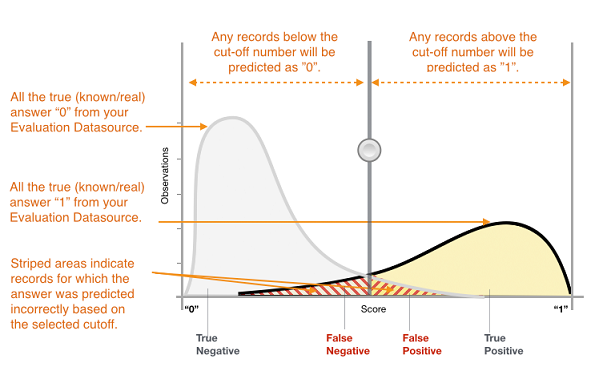
그림 1: 바이너리 분류 모델의 점수 분포
이제 예측은 실제로 알려진 대답 및 예측된 대답을 바탕으로 올바른 긍정 예측(참 긍정), 올바른 부정 예측(참 부정), 잘못된 긍정 예측(거짓 긍정) 및 잘못된 부정 예측(거짓 부정)의 4가지 그룹으로 분류됩니다.
바이너리 분류 정확성 지표는 두 가지 유형의 올바른 예측과 두 가지 유형의 오류를 정량화합니다. 일반적인 지표는 정확도(ACC), 정밀도, 재현율, 거짓 긍정 비율, F1 측정치입니다. 각 지표는 예측 모델의 다른 측면을 측정합니다. 정확도(ACC)는 올바른 예측의 비율을 측정합니다. 정밀도는 긍정으로 예측되는 사례 중 실제 긍정의 비율을 측정합니다. 재현율은 긍정으로 예측된 실제 긍정의 수를 측정합니다. F1 측정치는 정밀도와 재현율의 조화 평균입니다.
AUC는 다른 유형의 지표입니다. AUC에서는 부정적인 예보다 긍정적인 예에 대해 더 높은 점수를 예측하는 모델의 기능을 측정합니다. AUC는 선택한 임계값과는 별개이므로, 임계값을 선택하지 않고도 AUC 지표에서 모델의 예측 성능을 파악할 수 있습니다.
비즈니스 문제에 따라 이러한 지표의 특정 하위 집합에 대해 효과적으로 수행되는 모델에 더 관심을 가질 수 있습니다. 예를 들어 다음과 같이 두 비즈니스 애플리케이션은 ML 모델에 대해 매우 다른 요구 사항을 가질 수 있습니다.
한 애플리케이션은 실제로 긍정(높은 정밀도)인 긍정 예측에 대해 매우 높은 수준의 확신을 가져야 하며, 일부 긍정 사례를 부정(보통 수준의 재현율)으로 잘못 분류할 수 있어야 합니다.
다른 애플리케이션은 가능한 많은 수의 긍정 사례(높은 재현율)를 정확하게 예측해야 하며, 긍정(보통 수준의 정밀도)으로 잘못 분류된 일부 부정 사례를 수용해야 합니다.
Amazon ML에서 관측치는 [0,1]의 범위로 예측된 점수를 얻습니다. 예제를 0 또는 1로 분류할지 결정하기 위한 점수 임계값은 기본적으로 0.5로 설정됩니다. Amazon ML을 사용하면 다양한 점수 임계값 선택이 미치는 영향을 검토하고 비즈니스 요구 사항에 맞는 적절한 임계값을 선택할 수 있습니다.
