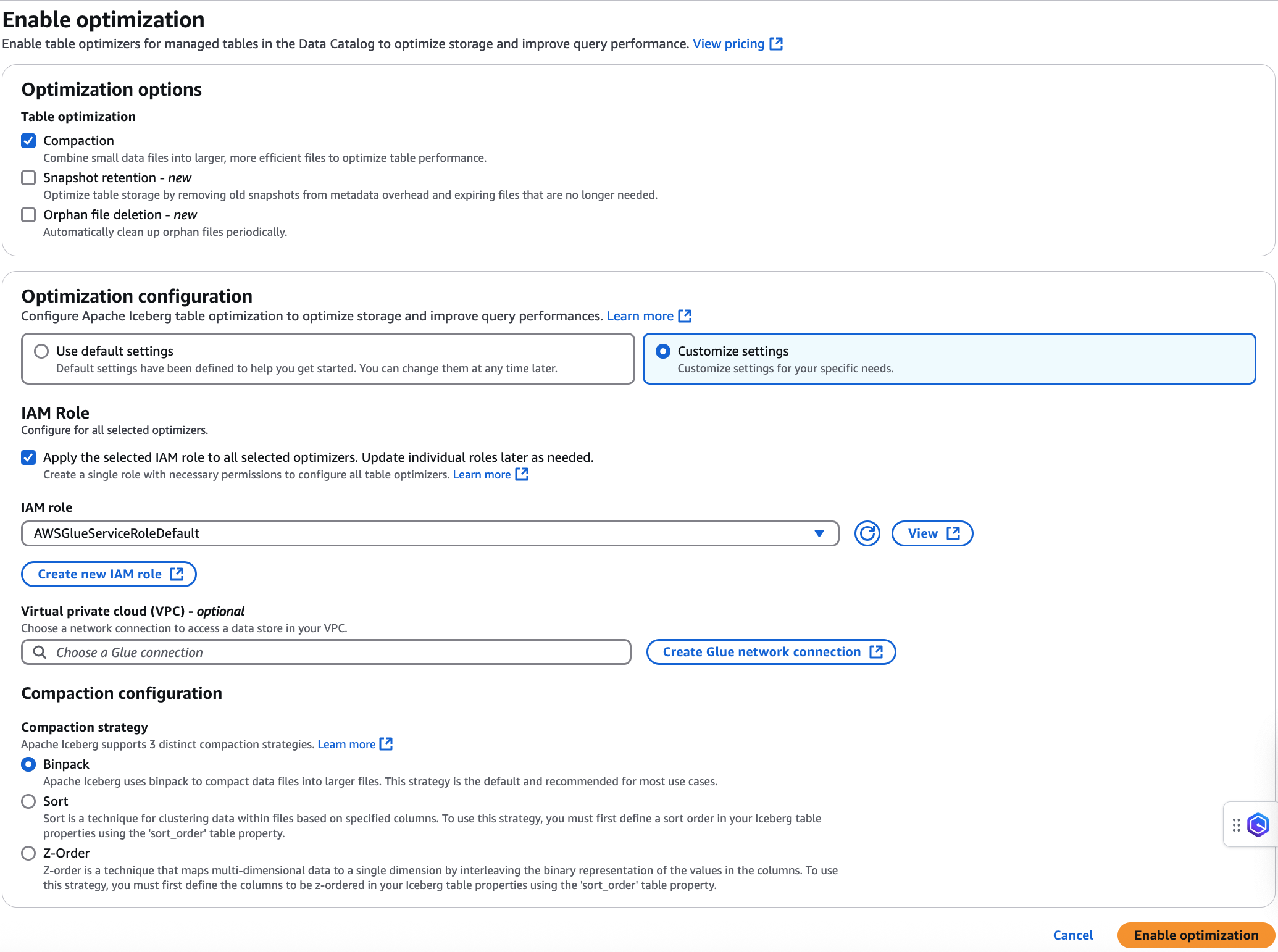
압축 최적화 프로그램 활성화
AWS Glue 콘솔, AWS CLI 또는 AWS API를 사용하여 AWS Glue Data Catalog에서 Apache Iceberg 테이블 압축을 활성화할 수 있습니다. 새 테이블의 경우 Apache Iceberg를 테이블 형식으로 선택하고 테이블을 생성할 때 압축을 활성화할 수 있습니다. 압축 기능은 새 테이블에 대해 기본적으로 비활성화되어 있습니다.
- Console
-
압축 기능 활성화하는 방법
-
https://console.aws.amazon.com/glue/에서 AWS Glue 콘솔을 열고 데이터 레이크 관리자, 테이블 작성자 또는 테이블에 대한 glue:UpdateTable 및 lakeformation:GetDataAccess 권한을 부여받은 사용자로 로그인합니다.
-
탐색 창의 데이터 카탈로그에서 테이블을 선택합니다.
테이블 페이지에서 압축을 활성화하려는 열린 테이블 형식의 테이블을 선택한 다음, 작업 메뉴 아래 최적화를 선택하고 활성화를 선택합니다.
테이블 세부 정보 페이지에서 테이블 최적화를 선택하여 압축을 활성화할 수도 있습니다. 페이지 하단에서 테이블 최적화 탭을 선택하고 압축 활성화를 선택합니다.
최적화 활성화 옵션은 Data Catalog에서 새 Iceberg 테이블을 생성할 때도 사용할 수 있습니다.
-
최적화 활성화 페이지의 최적화 옵션 아래 압축을 선택합니다.
-
그런 다음 테이블 최적화 필수 조건 섹션에 표시된 권한을 사용하여 드롭다운에서 IAM 역할을 선택합니다.
새 IAM 역할 생성 옵션을 선택하여 압축을 실행하는 데 필요한 권한이 있는 사용자 지정 역할을 생성할 수도 있습니다.
아래 단계에 따라 기존 IAM 역할을 업데이트하세요.
-
IAM 역할에 대한 권한 정책을 업데이트하려면 IAM 콘솔에서 컴팩션을 실행하는 데 사용되는 IAM 역할로 이동합니다.
-
권한 추가 섹션에서 정책 생성을 선택합니다. 새로 열린 브라우저 창에서 역할에 사용할 새 정책을 생성합니다.
-
정책 생성 페이지에서 JSON 탭을 선택합니다. 필수 조건에 표시된 JSON 코드를 정책 편집기 필드에 복사합니다.
-
Iceberg 테이블 옵티마이저가 특정 가상 프라이빗 클라우드(VPC)에서 Amazon S3 버킷에 액세스해야 하는 보안 정책 구성이 있는 경우 AWS Glue 네트워크 연결을 생성하거나 기존 연결을 사용하세요.
AWS Glue VPC 연결을 아직 설정하지 않은 경우 AWS Glue 콘솔 또는 AWS CLI/SDK를 사용하여 커넥터에 대한 연결 생성 섹션의 단계에 따라 새 연결을 생성하세요.
-
압축 전략을 선택합니다. 사용할 수 있는 옵션:
Binpack - Binpack은 Apache Iceberg의 기본 압축 전략입니다. 최적의 성능을 위해 더 작은 데이터 파일을 더 큰 데이터 파일로 결합합니다.
-
Sort - Apache Iceberg에서 정렬은 지정된 열을 기반으로 파일 내에서 정보를 클러스터링하여 처리해야 하는 파일 수를 줄여 쿼리 성능을 크게 개선하는 데이터 구성 기법입니다. 정렬 순서 필드를 사용하여 Iceberg 메타데이터에서 정렬 순서를 정의하고, 여러 개의 열이 지정되면 데이터가 순서에 따라 정렬되면 유사한 값의 레코드가 파일 내에 함께 저장됩니다. Sort 압축 전략은 파티션 내의 모든 파일에서 데이터를 정렬하여 최적화를 향상시킵니다.
Z-order - Z-order는 중요도가 동일한 여러 개의 열을 기준으로 정렬해야 할 때 데이터를 구성하는 방법입니다. 다른 열보다 한 열의 우선 순위를 높이는 기존 정렬과 달리 Z-order는 각 열에 균형 잡힌 가중치를 부여하므로 쿼리 엔진이 데이터를 검색할 때 더 적은 수의 파일을 읽을 수 있습니다.
이 기술은 여러 열의 값을 이진수 형태로 함께 위빙합니다. 예를 들어, 두 열의 숫자가 3과 4인 경우 Z-순서는 먼저 이진수로 변환합니다(3은 011이 되고 4는 100이 됨). 이후 이러한 숫자를 인터리빙하여 새 값인 011010을 생성합니다. 이 인터리빙으로 관련 데이터를 물리적으로 서로 가깝게 유지하는 패턴이 생성됩니다.
Z-order는 다차원 쿼리에 특히 효과적입니다. 예를 들어, 소득, 주 및 우편번호별로 Z-order가 적용된 고객 테이블은 여러 차원에서 쿼리할 때 계층적 정렬에 비해 뛰어난 성능을 제공할 수 있습니다. 이러한 구성을 통해 소득과 지리적 위치의 특정 조합을 대상으로 하는 쿼리가 불필요한 파일 스캔을 최소화하면서 관련 데이터를 빠르게 찾을 수 있습니다.
-
최소 입력 파일 - 압축이 트리거되려면 파티션에 있어야 하는 데이터 파일 수입니다.
-
파일 삭제 임계값 - 압축에 적합한 크기가 되기 위해 데이터 파일에서 요구되는 최소 삭제 작업 수입니다.
-
최적화 활성화를 선택합니다.
- AWS CLI
-
다음 예제는 압축 기능을 활성화하는 방법을 보여줍니다. 계정 ID를 유효한 AWS 계정 ID로 바꿉니다. 데이터베이스 이름과 테이블 이름을 실제 Iceberg 테이블 이름 및 데이터베이스 이름으로 바꿉니다. roleArn을 IAM 역할의 AWS 리소스 이름(ARN)과 압축 실행에 필요한 권한이 있는 IAM 역할의 이름으로 바꿉니다. sort 압축 전략을 z-order 또는 binpack과 같이 다른 지원되는 전략으로 바꿀 수 있습니다.
순서는 요구 사항에 따라 다릅니다.
aws glue create-table-optimizer \
--catalog-id 123456789012 \
--database-name iceberg_db \
--table-name iceberg_table \
--table-optimizer-configuration '{
"roleArn": "arn:aws:iam::123456789012:role/optimizer_role",
"enabled": true,
"vpcConfiguration": {"glueConnectionName": "glue_connection_name"},
"compactionConfiguration": {
"icebergConfiguration": {"strategy": "sort"}
}
}'\
--type compaction
- AWS API
-
CreateTableOptimizer 작업을 직접 호출하여 테이블의 압축을 활성화합니다.
압축을 활성화하면 압축 실행이 완료되면 테이블 최적화 탭에 다음과 같은 압축 세부 정보가 표시됩니다.
- 시작 시간
-
압축 프로세스가 데이터 카탈로그에서 시작되는 시간입니다. 값은 UTC 시간으로 표시된 타임스탬프입니다.
- 종료 시간
-
압축 프로세스가 데이터 카탈로그에서 끝나는 시간입니다. 값은 UTC 시간으로 표시된 타임스탬프입니다.
- Status
-
압축 실행의 상태입니다. 값은 성공 또는 실패입니다.
- 압축된 파일 수
압축된 총 파일 수입니다.
- 압축된 바이트 수
-
압축된 총 바이트 수입니다.